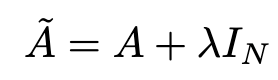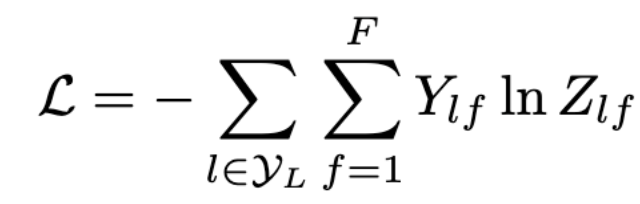日期:2020年10月13日
正文共:3808字24图
预计阅读时间:10分钟
来源:雷锋网
字幕组双语原文:【GCN】图卷积网络(GCN)入门详解英语原文:Graph Convolutional Networks (GCN)翻译:听风1996、大表哥
在这篇文章中,我们将仔细研究一个名为GCN的著名图神经网络。首先,我们先直观的了解一下它的工作原理,然后再深入了解它背后的数学原理。
为什么要用Graph?
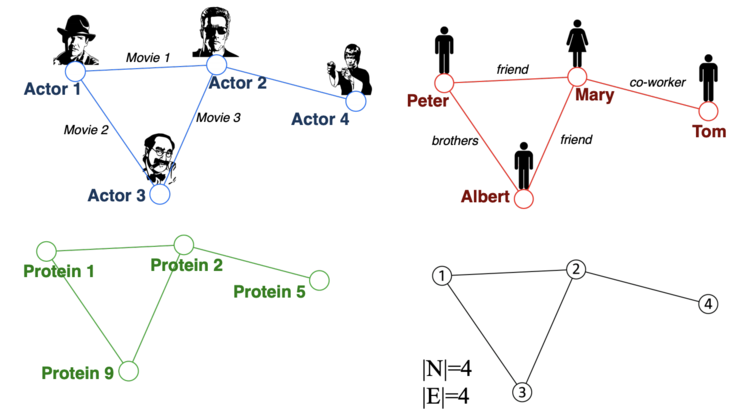
许多问题的本质上都是图。在我们的世界里,我们看到很多数据都是图,比如分子、社交网络、论文引用网络。Graph上的任务
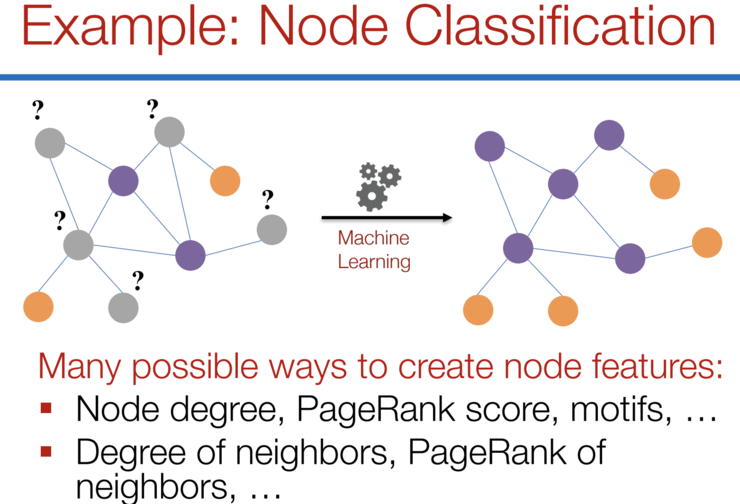
机器学习的生命周期
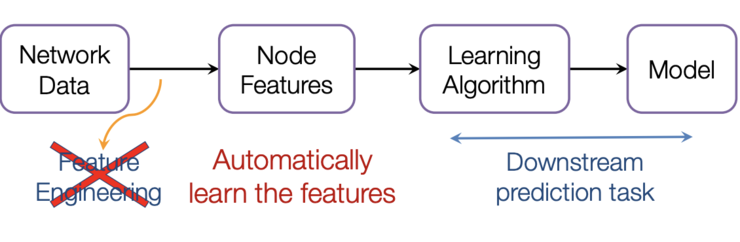
在图中,我们有节点特征(代表节点的数据)和图的结构(表示节点如何连接)。对于节点来说,我们可以很容易地得到每个节点的数据。但是当涉及到图的结构时,要从中提取有用的信息就不是一件容易的事情了。例如,如果2个节点彼此距离很近,我们是否应该将它们与其他对节点区别对待呢?高低度节点又该如何处理呢?其实,对于每一项具体的工作,仅仅是特征工程,即把图结构转换为我们的特征,就会消耗大量的时间和精力。如果能以某种方式同时得到图的节点特征和结构信息作为输入,让机器自己去判断哪些信息是有用的,那就更好了。我们希望图能够自己学习 "特征工程"。(图片来自[1])图卷积神经网络(GCNs)
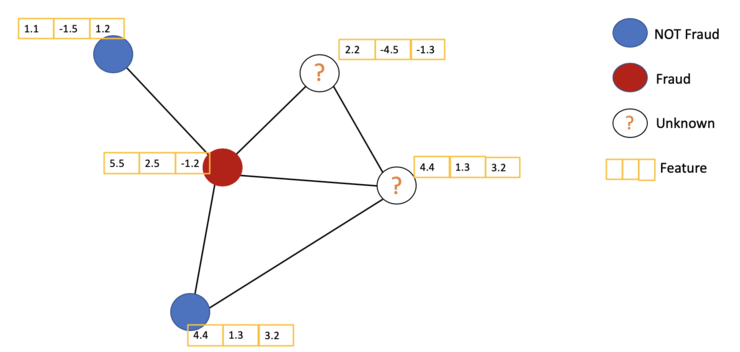
论文:基于图神经网络的半监督分类(2017)[3]GCN是一种卷积神经网络,它可以直接在图上工作,并利用图的结构信息。它解决的是对图(如引文网络)中的节点(如文档)进行分类的问题,其中仅有一小部分节点有标签(半监督学习)。在Graphs上进行半监督学习的例子。有些节点没有标签(未知节点)。 主要思想
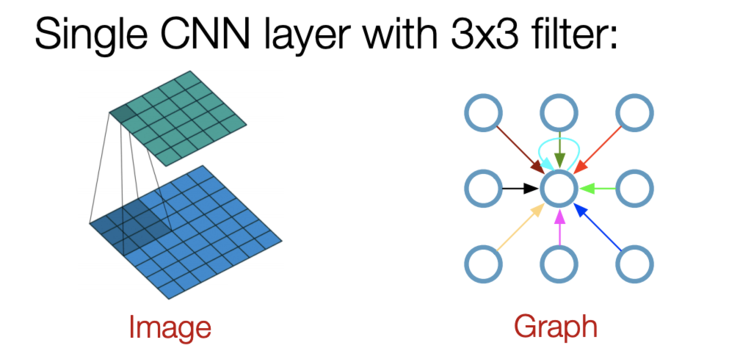
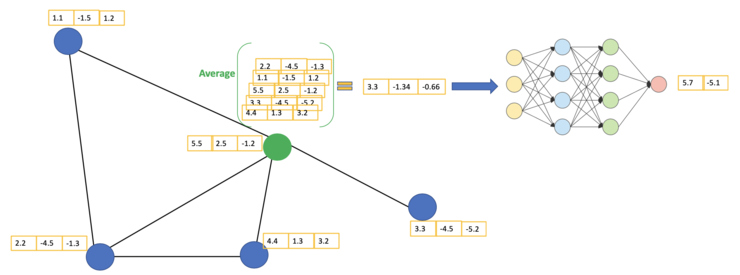
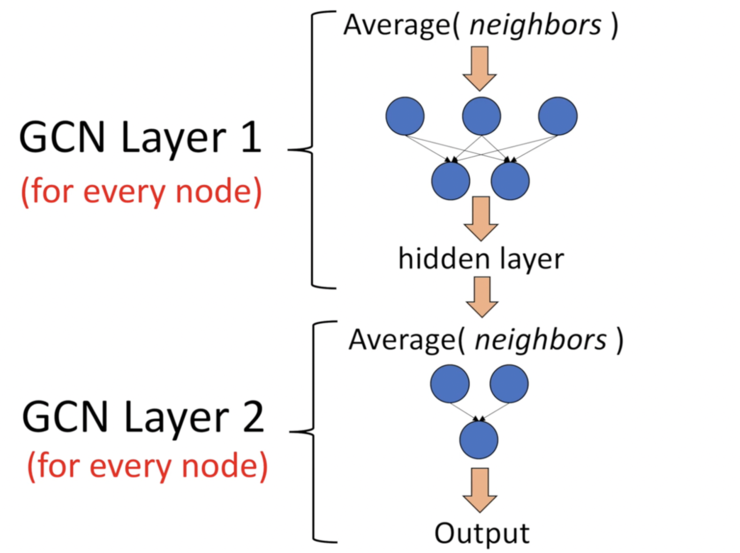
就像"卷积"这个名字所指代的那样,这个想法来自于图像,之后引进到图(Graphs)中。然而,当图像有固定的结构时,图(Graphs)就复杂得多。GCN的基本思路:对于每个节点,我们从它的所有邻居节点处获取其特征信息,当然也包括它自身的特征。假设我们使用average()函数。我们将对所有的节点进行同样的操作。最后,我们将这些计算得到的平均值输入到神经网络中。在下图中,我们有一个引文网络的简单实例。其中每个节点代表一篇研究论文,同时边代表的是引文。我们在这里有一个预处理步骤。在这里我们不使用原始论文作为特征,而是将论文转换成向量(通过使用NLP嵌入,例如tf-idf)。NLP嵌入,例如TF-IDF)。让我们考虑下绿色节点。首先,我们得到它的所有邻居的特征值,包括自身节点,接着取平均值。最后通过神经网络返回一个结果向量并将此作为最终结果。GCN的主要思想。我们以绿色节点为例。首先,我们取其所有邻居节点的平均值,包括自身节点。然后,将平均值通过神经网络。请注意,在GCN中,我们仅仅使用一个全连接层。在这个例子中,我们得到2维向量作为输出(全连接层的2个节点)。在实际操作中,我们可以使用比average函数更复杂的聚合函数。我们还可以将更多的层叠加在一起,以获得更深的GCN。其中每一层的输出会被视为下一层的输入。2层GCN的例子:第一层的输出是第二层的输入。同样,注意GCN中的神经网络仅仅是一个全连接层(图片来自[2])。直观感受和背后的数学原理
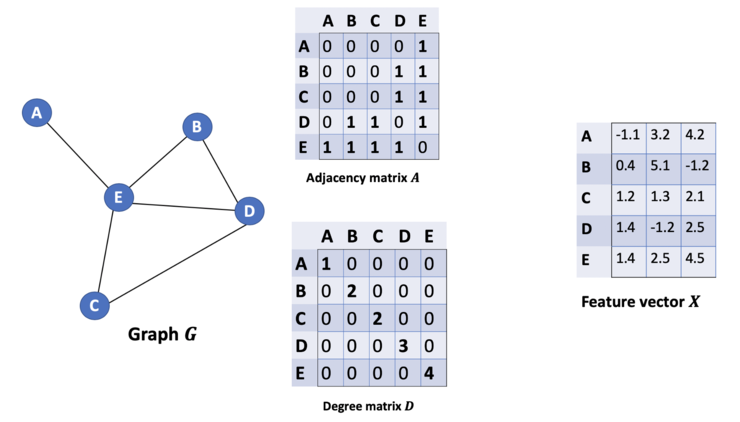
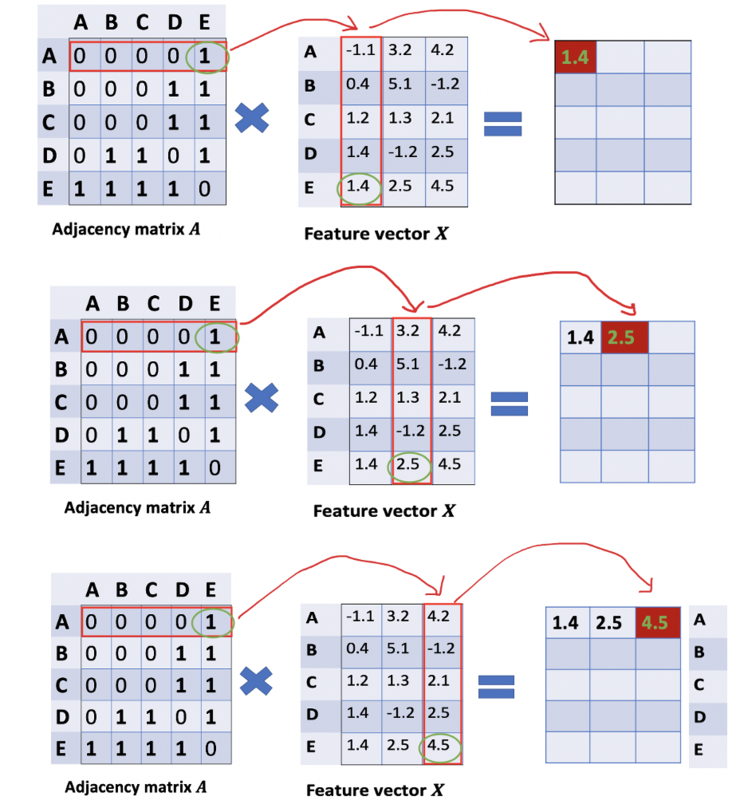
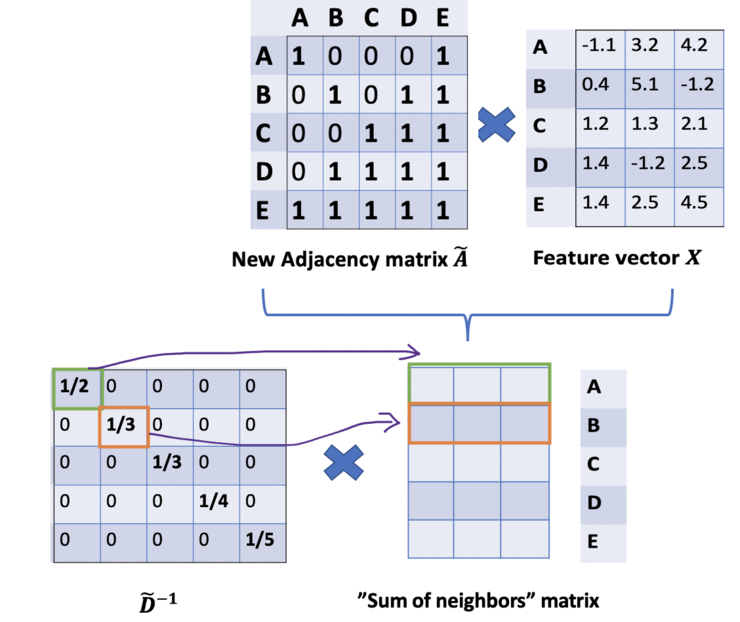
从图G中,我们有一个邻接矩阵A和一个度矩阵D。同时我们也有特征矩阵X。那么我们怎样才能从邻居节点处得到每一个节点的特征值呢?解决方法就在于A和X的相乘。看看邻接矩阵的第一行,我们看到节点A与节点E之间有连接,得到的矩阵第一行就是与A相连接的E节点的特征向量(如下图)。同理,得到的矩阵的第二行是D和E的特征向量之和,通过这个方法,我们可以得到所有邻居节点的向量之和。- 我们忽略了节点本身的特征。例如,计算得到的矩阵的第一行也应该包含节点A的特征。
- 我们不需要使用sum()函数,而是需要取平均值,甚至更好的邻居节点特征向量的加权平均值。那我们为什么不使用sum()函数呢?原因是在使用sum()函数时,度大的节点很可能会生成的大的v向量,而度低的节点往往会得到小的聚集向量,这可能会在以后造成梯度爆炸或梯度消失(例如,使用sigmoid时)。此外,神经网络似乎对输入数据的规模很敏感。因此,我们需要对这些向量进行归一化,以摆脱可能出现的问题。
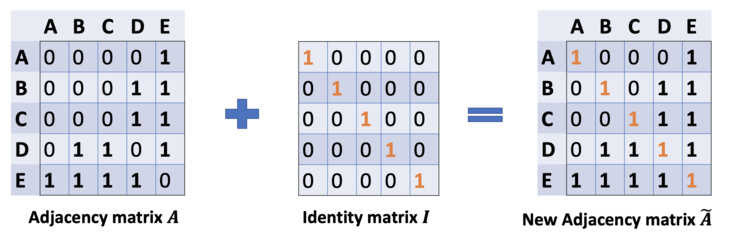
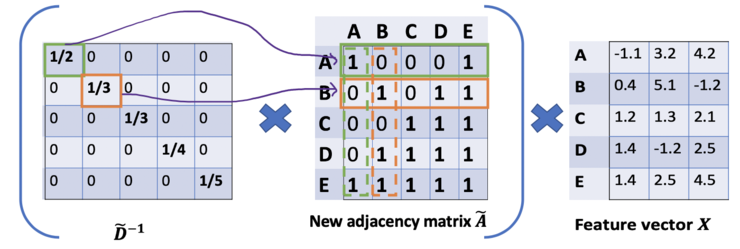
在问题(1)中,我们可以通过在A中增加一个单位矩阵I来解决,得到一个新的邻接矩阵Ã。取lambda=1(使得节点本身的特征和邻居一样重要),我们就有Ã=A+I,注意,我们可以把lambda当做一个可训练的参数,但现在只要把lambda赋值为1就可以了,即使在论文中,lambda也只是简单的赋值为1。通过给每个节点增加一个自循环,我们得到新的邻接矩阵
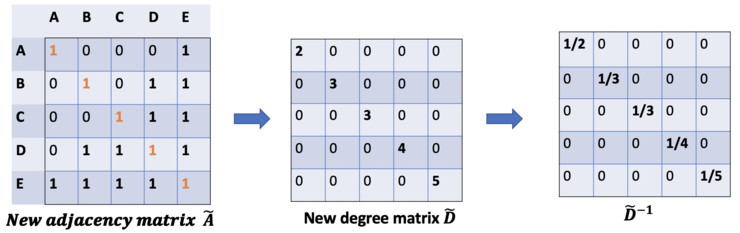
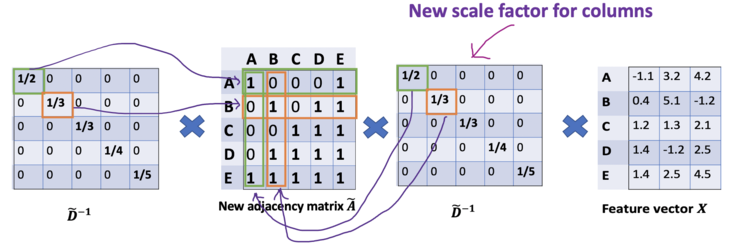
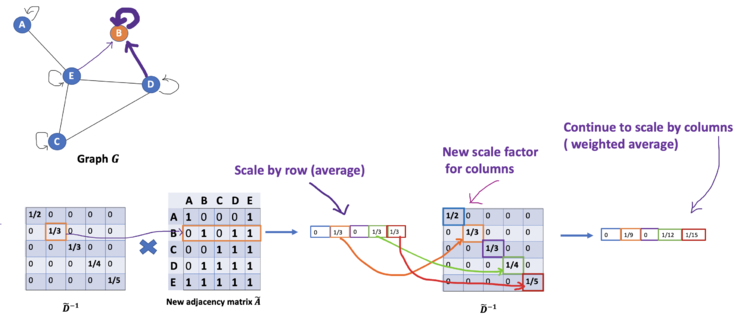
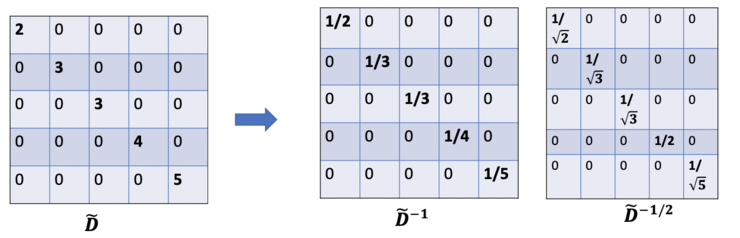
对于问题(2): 对于矩阵缩放,我们通常将矩阵乘以对角线矩阵。在当前的情况下,我们要取聚合特征的平均值,或者从数学角度上说,要根据节点度数对聚合向量矩阵ÃX进行缩放。直觉告诉我们这里用来缩放的对角矩阵是和度矩阵D̃有关的东西(为什么是D̃,而不是D?因为我们考虑的是新邻接矩阵Ã 的度矩阵D̃,而不再是A了)。现在的问题变成了我们要如何对和向量进行缩放/归一化?换句话说:我们如何将邻居的信息传递给特定节点?我们从我们的老朋友average开始。在这种情况下,D̃的逆矩阵(即,D̃^{-1})就会用起作用。基本上,D̃的逆矩阵中的每个元素都是对角矩阵D中相应项的倒数。例如,节点A的度数为2,所以我们将节点A的聚合向量乘以1/2,而节点E的度数为5,我们应该将E的聚合向量乘以1/5,以此类推。因此,通过D̃取反和X的乘法,我们可以取所有邻居节点的特征向量(包括自身节点)的平均值。到目前为止一切都很好。但是你可能会问加权平均()怎么样?直觉上,如果我们对高低度的节点区别对待,应该会更好。为列增加一个新的缩放器。
新的缩放方法给我们提供了 "加权 "的平均值。我们在这里做的是给低度的节点加更多的权重,以减少高度节点的影响。这个加权平均的想法是,我们假设低度节点会对邻居节点产生更大的影响,而高度节点则会产生较低的影响,因为它们的影响力分散在太多的邻居节点上。在节点B处聚合邻接节点特征时,我们为节点B本身分配最大的权重(度数为3),为节点E分配最小的权重(度数为5)。因为我们归一化了两次,所以将"-1 "改为"-1/2"
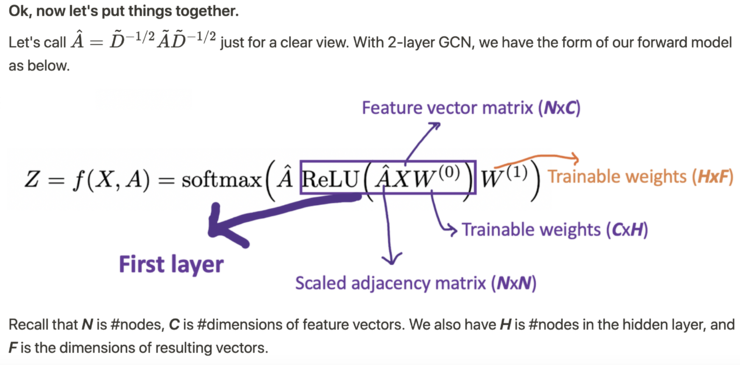
例如,我们有一个多分类问题,有10个类,F 被设置为10。在第2层有了10个维度的向量后,我们将这些向量通过一个softmax函数进行预测。Loss函数的计算方法很简单,就是通过对所有有标签的例子的交叉熵误差来计算,其中Y_{l}是有标签的节点的集合。 层的数量
#layers的含义
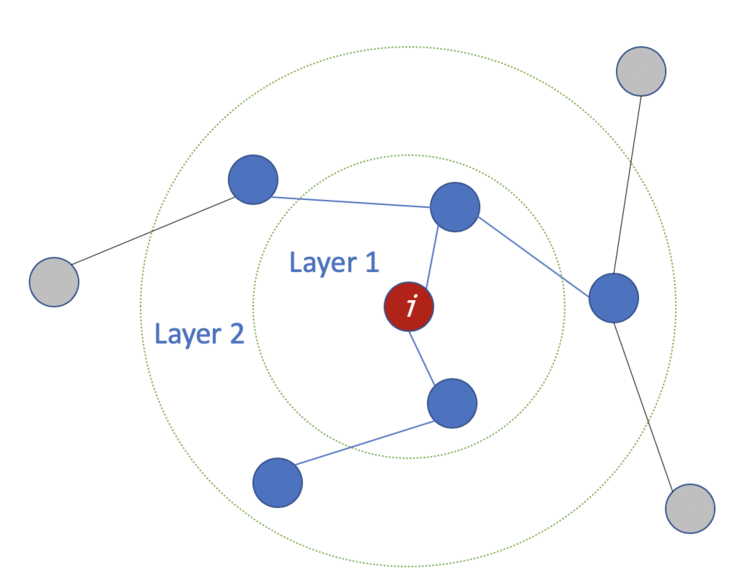
层数是指节点特征能够传输的最远距离。例如,在1层的GCN中,每个节点只能从其邻居那里获得信息。每个节点收集信息的过程是独立进行的,对所有节点来说都是在同一时间进行的。当在第一层的基础上再叠加一层时,我们重复收集信息的过程,但这一次,邻居节点已经有了自己的邻居的信息(来自上一步)。这使得层数成为每个节点可以走的最大跳步。所以,这取决于我们认为一个节点应该从网络中获取多远的信息,我们可以为#layers设置一个合适的数字。但同样,在图中,通常我们不希望走得太远。设置为6-7跳,我们就几乎可以得到整个图,但是这就使得聚合的意义不大。例:收集目标节点 i 的两层信息的过程
GCN应该叠加几层?
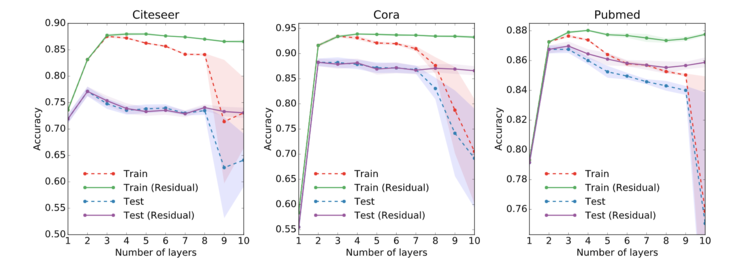
在论文中,作者还分别对浅层和深层的GCN进行了一些实验。在下图中,我们可以看到,使用2层或3层的模型可以得到最好的结果。此外,对于深层的GCN(超过7层),反而往往得到不好的性能(虚线蓝色)。一种解决方案是借助隐藏层之间的残余连接(紫色线)。不同层数#的性能。图片来自论文[3]
做好笔记
- GCN的主要思想是取所有邻居节点特征(包括自身节点)的加权平均值。度低的节点获得更大的权重。之后,我们将得到的特征向量通过神经网络进行训练。
- 我们可以堆叠更多的层数来使GCN更深。考虑深度GCNs的残差连接。通常,我们会选择2层或3层的GCN。
- 这里有一个使用StellarGraph库的GCN演示[5]。该仓库还提供了许多其他GNN的算法。
该框架目前仅限于无向图(加权或不加权)。但是,可以通过将原始有向图表示为一个无向的两端图,并增加代表原始图中边的节点,来处理有向边和边特征。下一步是什么呢?
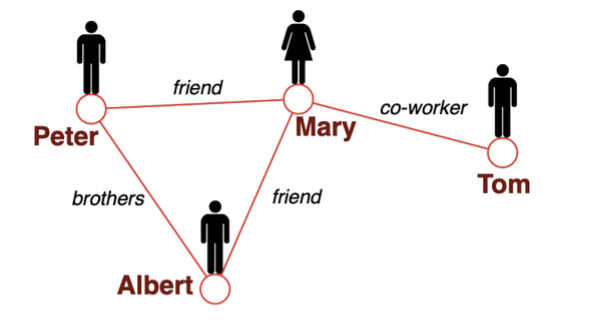
对于GCN,我们似乎可以同时利用节点特征和图的结构。然而,如果图中的边有不同的类型呢?我们是否应该对每种关系进行不同的处理?在这种情况下如何聚合邻居节点?最近有哪些先进的方法?在图专题的下一篇文章中,我们将研究一些更复杂的方法。 如何处理边的不同关系(兄弟、朋友、......)?参考文献
[1] Excellent slides on Graph Representation Learning by Jure Leskovec (Stanford): https://drive.google.com/file/d/1By3udbOt10moIcSEgUQ0TR9twQX9Aq0G/view?usp=sharing[2] Video Graph Convolutional Networks (GCNs) made simple: https://www.youtube.com/watch?v=2KRAOZIULzw[3] Paper Semi-supervised Classification with Graph Convolutional Networks (2017): https://arxiv.org/pdf/1609.02907.pdf[4] GCN source code: https://github.com/tkipf/gcn[5] Demo with StellarGraph library:https://stellargraph.readthedocs.io/en/stable/demos/node-classification/gcn-node-classification.html