
超越卷积、自注意力机制:强大的神经网络新算子involution
这篇工作主要是由我和SENet的作者胡杰一起完成的,也非常感谢HKUST的两位导师 陈启峰和张潼老师的讨论和建议。

概要
我们的贡献点简单来讲:
(1)提出了一种新的神经网络算子(operator或op)称为involution,它比convolution更轻量更高效,形式上比self-attention更加简洁,可以用在各种视觉任务的模型上取得精度和效率的双重提升。
(2)通过involution的结构设计,我们能够以统一的视角来理解经典的卷积操作和近来流行的自注意力操作。
论文链接:https://arxiv.org/abs/2103.06255
代码和模型链接:https://github.com/d-li14/involution
这部分内容主要来自原文Section 2,Section 3
convolution
 ,其中
,其中  和
和  分别是输出和输入的通道数目,而
分别是输出和输入的通道数目,而  是kernel size,
是kernel size,  一般不写,代表在
一般不写,代表在  个pixel上共享相同的kernel,即空间不变性,而每个通道C独享对应的kernel则称为通道特异性。convolution的操作可以表达为:
个pixel上共享相同的kernel,即空间不变性,而每个通道C独享对应的kernel则称为通道特异性。convolution的操作可以表达为:
 是input tensor,
是input tensor,  是output tensor,
是output tensor,  是convolution kernel。
是convolution kernel。空间不变性
 ,2.平移等变性,也可以理解为在空间上对类似的pattern产生类似的响应,其不足之处也很明显:提取出来的特征比较单一,不能根据输入的不同灵活地调整卷积核的参数。
,2.平移等变性,也可以理解为在空间上对类似的pattern产生类似的响应,其不足之处也很明显:提取出来的特征比较单一,不能根据输入的不同灵活地调整卷积核的参数。 一项,其中通道数量C往往是数百甚至数千,所以为了限制参数量和计算量的规模,K的取值往往较小。我们从VGGNet开始习惯沿用
一项,其中通道数量C往往是数百甚至数千,所以为了限制参数量和计算量的规模,K的取值往往较小。我们从VGGNet开始习惯沿用  大小的kernel,这限制了卷积操作一次性地捕捉长距离关系的能力,而需要依靠堆叠多个 大小的kernel,这对于感受野的建模在一定程度上不如直接使用大的卷积核更加有效。
大小的kernel,这限制了卷积操作一次性地捕捉长距离关系的能力,而需要依靠堆叠多个 大小的kernel,这对于感受野的建模在一定程度上不如直接使用大的卷积核更加有效。通道特异性
 大小的矩阵,那么矩阵的秩不会超过
大小的矩阵,那么矩阵的秩不会超过  ,代表其中存在很多的kernel是近似线性相关的。
,代表其中存在很多的kernel是近似线性相关的。involution
 ,其中
,其中  ,表示所有通道共享G个kernel。involution的操作表达为:
,表示所有通道共享G个kernel。involution的操作表达为:
 是involution kernel。
是involution kernel。 大小的图像作为输入训练得到的权重,就无法迁移到输入图像尺寸更大的下游任务中(比如检测、分割等)。involution kernel生成的通用形式如下:
大小的图像作为输入训练得到的权重,就无法迁移到输入图像尺寸更大的下游任务中(比如检测、分割等)。involution kernel生成的通用形式如下:
 是坐标(i,j)邻域的一个index集合,所以
是坐标(i,j)邻域的一个index集合,所以  表示feature map上包含
表示feature map上包含  的某个patch。
的某个patch。 ,可以有各种不同的设计方式,也值得大家去进一步探索。我们从简单有效的设计理念出发,提供了一种类似于SENet的bottleneck结构来进行实验: 就取为
,可以有各种不同的设计方式,也值得大家去进一步探索。我们从简单有效的设计理念出发,提供了一种类似于SENet的bottleneck结构来进行实验: 就取为  这个单点集,即 取为feature map上坐标为(i, j)的单个pixel,从而得到了involution kernel生成的一种实例化
这个单点集,即 取为feature map上坐标为(i, j)的单个pixel,从而得到了involution kernel生成的一种实例化
 和
和  是线性变换矩阵,r是通道缩减比率,
是线性变换矩阵,r是通道缩减比率,  是中间的BN和ReLU。
是中间的BN和ReLU。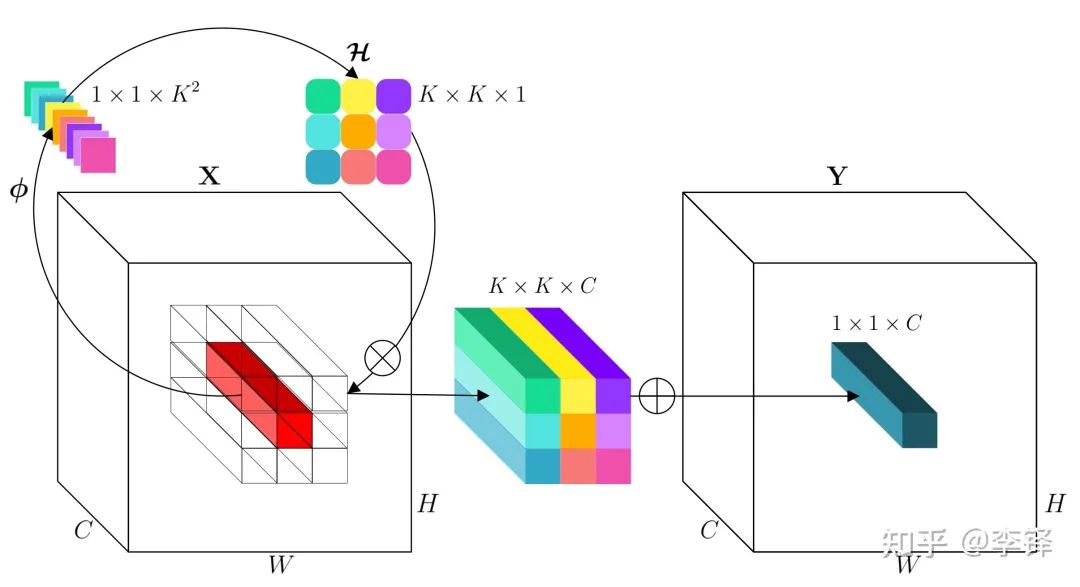 (FC-BN-ReLU-FC)和reshape (channel-to-space)变换展开成kernel的形状,从而得到这个坐标点上对应的involution kernel,再和输入feature map上这个坐标点邻域的特征向量进行Multiply-Add得到最终输出的feature map。具体操作流程和tensor形状变化如下:
(FC-BN-ReLU-FC)和reshape (channel-to-space)变换展开成kernel的形状,从而得到这个坐标点上对应的involution kernel,再和输入feature map上这个坐标点邻域的特征向量进行Multiply-Add得到最终输出的feature map。具体操作流程和tensor形状变化如下:
 是坐标(i,j)附近
是坐标(i,j)附近  的邻域。单纯基于PyTorch API简单的伪代码实现如下:
的邻域。单纯基于PyTorch API简单的伪代码实现如下:
 ,计算量分为kernel generation和Multiply-Add (MAdd)两部分
,计算量分为kernel generation和Multiply-Add (MAdd)两部分  ,明显低于普通convolution的参数量
,明显低于普通convolution的参数量  和计算量
和计算量  。
。在通道上共享kernel(仅有G个kernel)允许我们去使用大的空间span(增加K),从而通过spatial维度的设计提升性能的同时保证了通过channel维度的设计维持效率(见ablation in Tab. 6a,6b),即使在不同空间位置不共享权重也不会引起参数量和计算量的显著增长。
虽然我们没有在空间上的每个pixel直接共享kernel参数,但我们在更高的层面上共享了元参数(meta-weight,即指kernel生成函数的参数),所以仍然能够在不同的空间位置上进行knowledge的共享和迁移。作为对比,即使抛开参数量大涨的问题,如果将convolution在空间上共享kernel的限制完全放开,让每个pixel自由地学习对应的kernel参数,则无法达到这样的效果。
[Discussion] 与self-attention的相关性
这部分内容主要来自原文Section 4.2
self-attention
 ,
, 分别为输入
分别为输入  线性变换后得到的query,key和value,H是multi-head self-attention中head的数目。下标表示(i, j)和(p,q)对应的pixel之间进行query-key匹配,
线性变换后得到的query,key和value,H是multi-head self-attention中head的数目。下标表示(i, j)和(p,q)对应的pixel之间进行query-key匹配,  表示query(i,j)对应key的范围,可能是 的local patch(local self-attention),也可能是 的full image(global self-attention)。
表示query(i,j)对应key的范围,可能是 的local patch(local self-attention),也可能是 的full image(global self-attention)。
self-attention中不同的head对应到involution中不同的group(在channel维度split) self-attention中每个pixel的attention map  对应到involution中每个pixel的kernel
对应到involution中每个pixel的kernel 

 对应于attention matrix multiplication前对 做的线性变换,self-attention操作后一般也会接另一个线性变换和残差连接,这个结构正好就对应于我们用involution替换resnet bottleneck结构中的 convolution,前后也有两个 convolution做线性变换。
对应于attention matrix multiplication前对 做的线性变换,self-attention操作后一般也会接另一个线性变换和残差连接,这个结构正好就对应于我们用involution替换resnet bottleneck结构中的 convolution,前后也有两个 convolution做线性变换。 而不是 (
而不是 (  是position encoding matrix)。而从我们involution的角度来看,这只不过是又换了一种kernel generation的形式来实例化involution。
是position encoding matrix)。而从我们involution的角度来看,这只不过是又换了一种kernel generation的形式来实例化involution。 ,
,  ),这同时也说明了CNN设计中的locallity依然是宝藏,因为即使用global self-attention,网络的浅层也很难真的利用到复杂的全局信息。
),这同时也说明了CNN设计中的locallity依然是宝藏,因为即使用global self-attention,网络的浅层也很难真的利用到复杂的全局信息。Vision Transformer
实验结果
ImageNet图像分类
 convolution得到了一族新的骨干网络RedNet,性能和效率优于ResNet和其他self-attention做op的SOTA模型。
convolution得到了一族新的骨干网络RedNet,性能和效率优于ResNet和其他self-attention做op的SOTA模型。COCO目标检测和实例分割
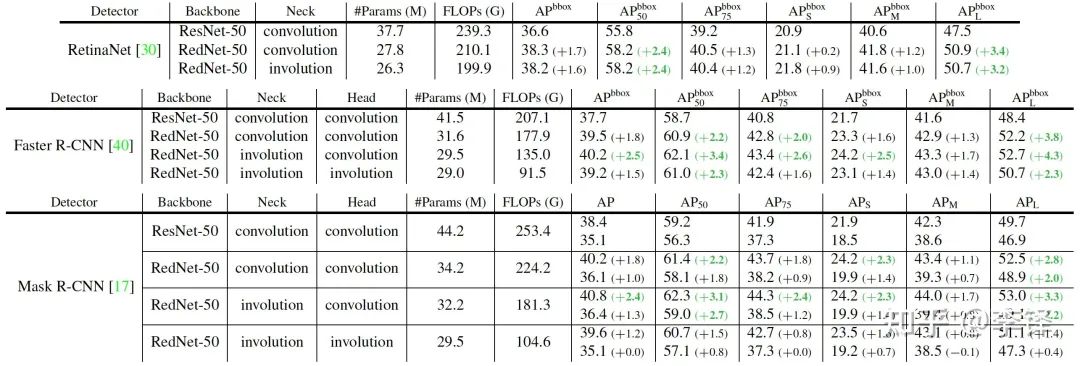
 40%。
40%。Cityscapes语义分割

 提升最多(3%-4%),Cityscapes分割任务中也是大物体(比如墙,卡车,公交车等)的单类别IoU提升最明显(高达10%甚至20%以上),这也验证了我们在之前分析中所提到的involution相比于convolution在空间上具有动态建模长距离关系的显著优势。
提升最多(3%-4%),Cityscapes分割任务中也是大物体(比如墙,卡车,公交车等)的单类别IoU提升最明显(高达10%甚至20%以上),这也验证了我们在之前分析中所提到的involution相比于convolution在空间上具有动态建模长距离关系的显著优势。关于广义的involution中kernel生成函数空间进一步的探索; 类似于deformable convolution加入offest生成函数,使得这个op空间建模能力的灵活性进一步提升; 结合NAS的技术搜索convolution-involution混合结构(原文Section 4.3); 我们在上文论述了self-attention只是一种表达形式,但希望(self-)attention机制能够启发我们设计更好的视觉模型,类似地detection领域最近不少好的工作,也从DETR的架构中获益匪浅。
© THE END
评论