
霸榜马里奥赛车,谷歌将神经进化引入自解释智能体,强化学习训练参...

新智元报道
来源:arxiv编辑:白峰、鹏飞【新智元导读】最近,谷歌的研究人员发现神经进化方法非常适合训练基于视觉的强化学习(RL)任务的自注意力结构,使研究人员能够合并一些模块,包括对智能体有用的一些不可微分的操作,从而解决具有挑战性的视觉任务如马里奥赛车,其参数至少降低了 1000 倍。「新智元急聘主笔、高级主任编辑,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」

心理学中有一种现象叫选择性失明,会使人们看不见东西。选择性关注使我们能够专注于信息的重要部分,而不会将精力分散到无关紧要的细节,而谷歌的这篇强化学习论文正是受此启发。
受神经科学启示,发现高效编码方法
关于大型神经网络的泛化性能讨论很多,虽然较大的神经网络比较小的神经网络具有更好的泛化能力,但原因并不在于它们有更多的权重参数。研究表明,较大的神经网络允许优化算法在允许的解空间的一小部分内找到好的解决方案, 然后可以将这些解修剪成具有有用的归纳偏差的子网络,这些子网络具有较好的推广性。
 目前大多数用于训练神经网络的方法,无论是梯度下降法还是进化算法,都旨在求解给定神经网络的每个单独权重参数的值。我们将这些方法称为直接编码方法。而间接编码提供了一种完全不同的方法。这些方法针对一小组规则或操作(称为基因型)进行优化,这些规则或操作可以指导生成(大得多的)神经网络。通过对参数较少的大型模型的权值进行编码,我们可以大大缩小解空间,而代价是我们的解空间被限制到了一个很小的子空间。我们将这种编码方法融入到我们的智能体中,从而得到一个归纳偏差,这个偏差决定了它擅长什么。
目前大多数用于训练神经网络的方法,无论是梯度下降法还是进化算法,都旨在求解给定神经网络的每个单独权重参数的值。我们将这些方法称为直接编码方法。而间接编码提供了一种完全不同的方法。这些方法针对一小组规则或操作(称为基因型)进行优化,这些规则或操作可以指导生成(大得多的)神经网络。通过对参数较少的大型模型的权值进行编码,我们可以大大缩小解空间,而代价是我们的解空间被限制到了一个很小的子空间。我们将这种编码方法融入到我们的智能体中,从而得到一个归纳偏差,这个偏差决定了它擅长什么。试水马里奥赛车
为了验证这种编码方法的有效性,我们在两个具有挑战性的、基于视觉的 RL 任务中进行评估:CarRacing 和 DoomTakeCover。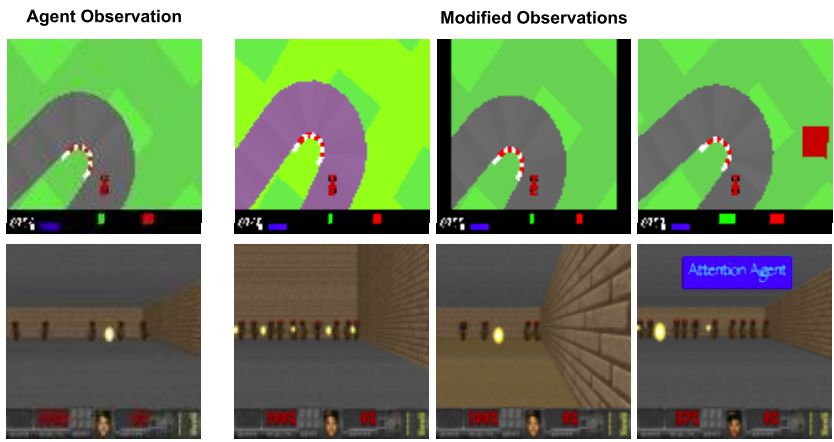 左:原始任务。观测值将调整为 96x96px,并输入给智能体。右:修改后的赛车场环境,颜色扰动,垂直框架,背景斑点。修改后的 DoomTakeCover 环境:更高的墙壁,不同的地板纹理,悬停文字。在 CarRacing 中,智能体控制红色汽车的三个连续动作(向左/向右转向,加速和制动),以有限的步骤访问尽可能多的随机生成的轨道块。在每个步骤中,如果没有碰到轨道块,智能体会收到-0.1 分的处罚,但对于其访问的每个轨道块,将获得+ (1000/n)分的奖励,其中 n 是块总数。只要所有的轨道块都被访问,或者 1000 步走完,就算一局结束。如果 100 次连续测试的平均得分高于 900,则认为 CarRacing 问题已解决。许多研究员尝试使用 Deep RL 算法解决此任务,但直到 David Ha 和 JürgenSchmidhuber 提出《 Recurrent World Models Facilitate
左:原始任务。观测值将调整为 96x96px,并输入给智能体。右:修改后的赛车场环境,颜色扰动,垂直框架,背景斑点。修改后的 DoomTakeCover 环境:更高的墙壁,不同的地板纹理,悬停文字。在 CarRacing 中,智能体控制红色汽车的三个连续动作(向左/向右转向,加速和制动),以有限的步骤访问尽可能多的随机生成的轨道块。在每个步骤中,如果没有碰到轨道块,智能体会收到-0.1 分的处罚,但对于其访问的每个轨道块,将获得+ (1000/n)分的奖励,其中 n 是块总数。只要所有的轨道块都被访问,或者 1000 步走完,就算一局结束。如果 100 次连续测试的平均得分高于 900,则认为 CarRacing 问题已解决。许多研究员尝试使用 Deep RL 算法解决此任务,但直到 David Ha 和 JürgenSchmidhuber 提出《 Recurrent World Models FacilitatePolicy Evolution.In Advances in Neural Information Processing Systems 》才部分解决。DoomTakeCover 是我们进行的另一项任务,在该任务中,智能体必须躲避怪物发射的火球并尽可能长地存活。每局持续 2100 步,但如果智能体被枪杀,则结束。这是一个离散的控制问题,智能体可以选择在每个步骤中向左/向右移动或保持静止。智能体每一次成功躲避,会获得+1 分的奖励,并且如果 100 局以上的平均累积奖励大于 750,则认为任务已完成。
引入 self-attention 进行数据处理
我们将自注意力机制引入到输入图像的处理,主要经过以下几个步骤: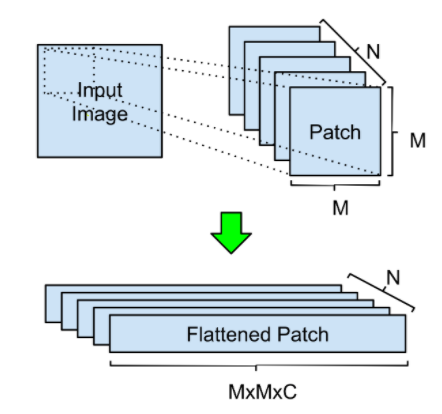
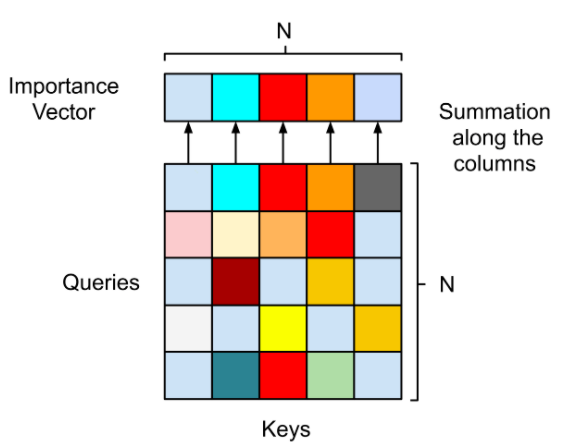
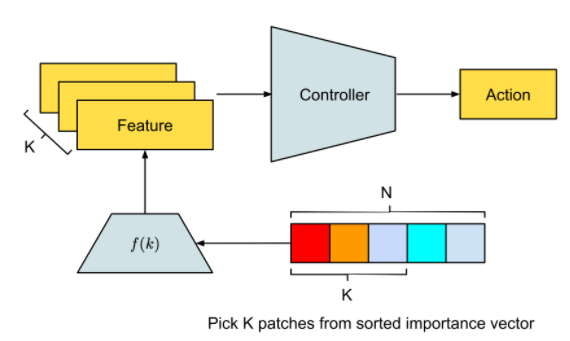
不仅达成目标,参数还锐减 1000 倍
结构设计好之后,开始用神经进化算法对自注意力模块和控制器的参数进行训练,神经进化为什么是训练自注意力智能体的理想方法呢?因为神经进化可以去除基于梯度方法的不必要的复杂性,从而使计算更简单。此外,我们还用一些模块来增强自注意力的有效性,下面是实验的结果。
结果显示,经过神经进化训练的智能体,比传统方法需要的参数要少 1000 倍,并且能够解决具有挑战性的基于视觉的 RL 任务。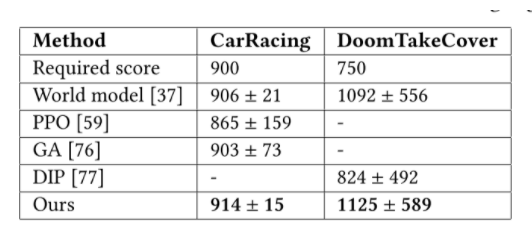
人工智能吹响了智能大航海时代的号角,AI也成为抗疫救灾的技术主题词。新智元特推出“AI方舟”直播公开课,依托“AI开放创新平台”小程序,邀请一线AI技术专家分享实战经验,带你一起驶向载满干货的新航程。

评论