
【经验】深度强化学习训练与调参技巧
来源:知乎(https://zhuanlan.zhihu.com/p/482656367)
作者:岳小飞
天下苦 RL 久矣,其中最苦的地方莫过于训练和调参了,人人欲“调”之而后快。
【RL Tips and Tricks -- Start】
这块主要是 RL Tips and Tricks 的翻译,其中 RL 相关的专有词汇保持英文原版。
这种格式的内容为个人注解,主要是【总结】和【扩展】。下面开始翻译正文~
本文的目的在于帮你更好的用 RL,涵盖了关于 RL 的一般建议(从哪里开始,选择哪种算法,如何评估算法),以及在使用自定义环境或实现 RL 算法时的 Tips 和 Tricks。我们也提供了 视频 和 slides。
使用 RL 的建议
太长不看版
学习 RL 和 Stable Baselines3
如有必要,进行定量的实验和超参数调整
使用单独的测试环境评估效果(记得要检查 wrappers!)
想要更好的效果,就增加训练预算
和其他领域一样,如果你想使用 RL,首先你要学习它(推荐资源),才能理解你在用什么。也推荐看 Stable Baselines3 (BS3) 的文档和教程,其中包括了基本使用和进阶技巧(比如 callbacks 和 wrappers)。
强化学习与其他机器学习有很大不同:相比监督学习使用固定的数据集,强化学习的数据集是 agent 与 env 交互产生的,即自己采集数据来训练自己。这种依赖可能导致恶性循环:如果 agent 收集的数据质量很差,比如获得的 reward 很少,那么 agent 将得不到改善而继续差下去。
这也解释了为什么 RL 的结果跑一次变一次,甚至只是改变了 seed。因此为了获得可靠的结果,需要多跑几次。
RL 要想有好的结果,合适的超参数至关重要。近期的算法(PPO、SAC、TD3)通常只需要很少的超参数调节,但也不要指望算法的默认参数适合每一个 env。
因此,强烈推荐看看 RL zoo(或原始论文)来获得好的超参数。将 RL 应用到一个新问题时,最好的实践就是超参数的自动调优,好消息是 RL zoo 也提供了这种功能。
将 RL 应用到一个自定义问题时,应该始终 normalize 给 agent 的输入(比如使用 VecNormalize for PPO/A2C),还可以看看其他环境的常用预处理(比如 Atari 游戏的 frame-stack)。有关自定义环境更具体的 Tips 和 Tricks 请看下文相关内容。
【总结】强化学习训练困难的根源即在于数据获取的不稳定性。因为数据都是 agent 自己采集的,而每次采集的结果会因 seed 和 超参数 的变化而变化,再加之 stochastic 策略的随机性,数据的稳定性就更差了。既然稳定性不行,为了提高学习效果,那就堆数量,即采集足够多的数据。
目前 RL 的局限
要入 RL 的坑,你得知道 RL 现在有哪些 坑。
Model-free RL 算法(比如 SB3 里实现的算法)通常 sample inefficient,即需要大量的 samples(有时需要上百万次交互)才能学到点有用的。这也是为什么大多数 RL 只在游戏和仿真里取得了成功。比如 ETH Zurich 的工作,ANYmal 四足机器人只在仿真中训练,然后在现实中测试。
一个通用建议,要先获得更好效果,你需要增加 agent 的预算(训练的步数)。
为了让 agent 表现出期望的行为,通常需要 expert knowledge 来设计一个良好的 reward function,这种 reward engineering 一般也需要迭代几次。举个不错的 reward shaping 例子,Deep Mimic 结合了模仿学习和强化学习来做出各种特技动作。
RL 还有一个坑在于训练的不稳定,比如在训练中看到效果突然出现断崖式下跌。这种现象容易在 DDPG 中出现,为了解决这个问题出现了它的扩展版 TD3。其他的方法比如 TRPO、PPO 使用 trust region 来避免过大的 update,进而减少出现这个问题。
【总结】坑还是围绕数据的不稳性展开,主要有三点:1) sample inefficient;2) sensitivity to seed / hyperparameters;3) reward function design。基本上所有的 RL 算法,都在围绕这三点做文章。
如何评估 RL 算法?
(Note:在评估 agent 以及和其他结果对比时,要注意 env wrappers。对 episode rewards 或 lengths 的修改也可能导致不好的评估结果。可以参考 Evaluation Helper 部分的 evaluate_policy 函数。)
因为大多数算法在训练期间会使用 exploration noise,因此需要一个独立的 test env 去评估算法。建议周期性地评估 agent,比如每交互 N(如10000) 次之后测试 n(5~20) 个episodes,然后取平均得到单个 episode 的 reward。
(Note:我们提供了 EvalCallback 来做这样的评估,具体可参考 Callbacks 部分。)
由于某些算法(如 A2C、PPO)默认采取 stochastic 策略,因此在测试即调用 .predict() 时应该设置 deterministic=True,这会有更好的效果。查看 training curve 是一种不错的方式,但会低估 agent 的真实表现。
【扩展】实际上现在不少 RL 库(比如 spinningup、Stable Baselines3)的 training curve 已经是 deterministic=True 的评估了。
我们建议你阅读 Deep Reinforcement Learning that Matters,其中关于 RL 评估做了很好的讨论。
你也可以看看 Cédric Colas 关于这方面的 blog 和 issue。
我该使用哪种算法?
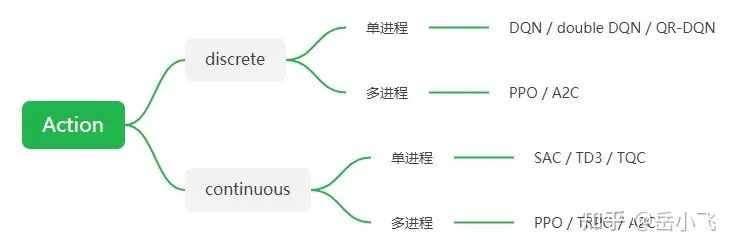
在 RL 中没有万金油,使用哪种算法取决于具体的需求和问题。首先要区分 action space 是 discrete(比如上下左右) 还是 continuous(比如达到某个速度)?
一些算法只能用于对应的 action space:DQN 只能用于 discrete action,SAC 只能用于 continuous action。
【扩展】实际上也有 DQN 的 continuous 版:NAF,SAC 的 discrete 版:SAC-Discrete。
接下来看你的训练是否需要并行?如果时间对你很宝贵,你应该选择 A2C 和它的变种比如 PPO。参考 Vectorized Environment 来了解更多 multiple workers 训练。
【扩展】实际上也有优秀的分布式框架 Ape-X,可搭配各种 off-policy RL 算法如 DQN、DDPG 使用。此外要注意的是,对于 off-policy 算法而言,多进程不一定更“快”,在 wall-clock time 和 sample efficiency 之间有个折中。更多的 envs 意味着更低的 sample efficiency 和 更短的 wall-clock time,具体见 pull #439。
RL 算法的选择总结如下,注意 normalization 很重要!
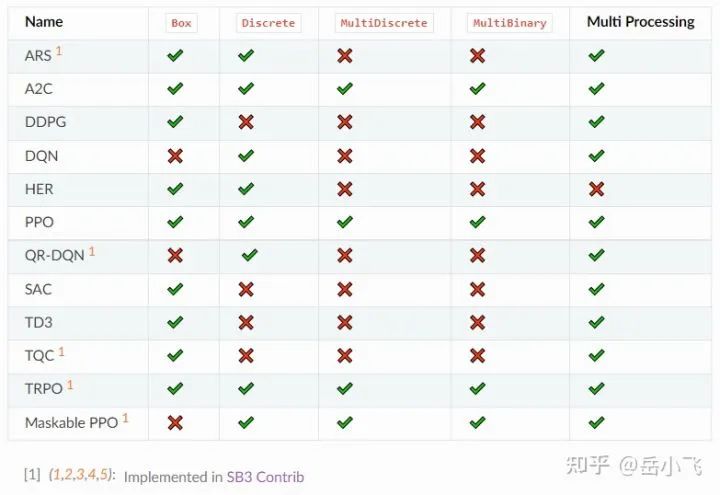
【扩展】Stable Baselines3 实现的 RL 算法具体的适用情况:
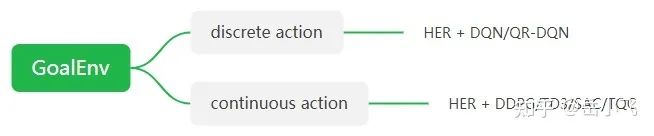
如果你的 env 使用 GoalEnv 接口,那么要配合后视经验 HER 使用,注意 HER 的 batch_size 很重要!
创建自定义环境的 Tips 和 Tricks
如果你想自定义环境,推荐看这里,我们也提供了一个 colab notebook 例子。
一些基本的建议:
尽量 normalize 你的 observation space,尤其知道边界值的时候
normalize 你的 action space 到 [-1,1],这个 scale 很容易做到,当与 env 交互时 rescale 回去即可
从 shaped reward 开始,并且简化问题
用 random actions 去测试 env 是否正常,注意保持 gym 接口
我们提供了方法查看自定义环境是否正常:
from stable_baselines3.common.env_checker import check_env
env = CustomEnv(arg1, ...)
# It will check your custom environment and output additional warnings if needed
check_env(env)如果想用 random agent 快速测试环境,很简单:
env = YourEnv()
obs = env.reset()
n_steps = 10
for _ in range(n_steps):
# Random action
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
if done:
obs = env.reset()action space 为什么要 normalize?
大多数 RL 算法处理 continuous aciton 是基于 Gaussian 分布(最初中心在 0,方差为 1)。因此,如果你忘了 normalize 自定义环境中的 action space,会导致学习很难,调试难上加难(见 issue #473)。
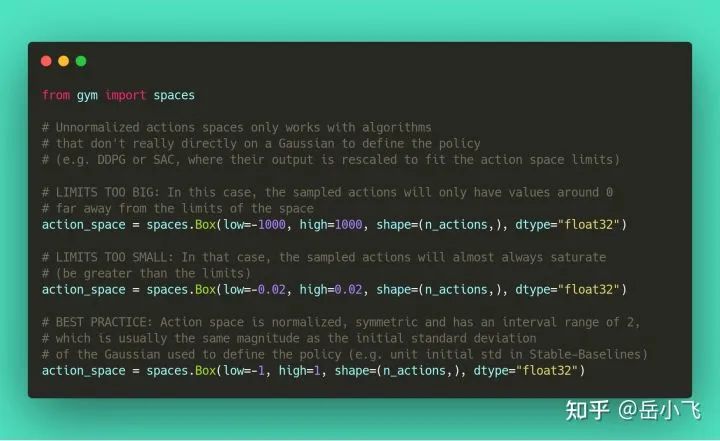
使用 Gaussian 分布会带来另一个问题,即 action range 没有边界,因此经常使用 clipping 来保证一个有效区间。一种更好的方案是使用 squashing 函数(见 SAC)或者 Beta 分布(见 issue #112)。
(Note:对于 DDPG 或 TD3 来说不需要,因为它们不依赖任何概率分布。)
【总结】observation、action 都尽量 normalzation,从 shaped reward 开始。
实现 RL 算法的 Tips 和 Tricks
当你想自己写 RL 算法来复现 paper 时,John Schulman 的 nuts and bolts of RL research 很有用(视频)。
我们建议按照以下步骤来实现一个可用的 RL 算法:
多看几次原始论文
看现有的实现(如果有的话)
试着在简单的 toy problems 上有点作用
让算法运行在越来越难的 env 上(可以和 RL zoo 上的结果对比),配合调参
【扩展】建议从 spinningup 这种 single-file 的 RL 库开始改。
在编写算法时,需要特别注意不同对象的 shape(broadcast 的错误会暗藏杀机),以及什么时候停止梯度传播。
关于从易到难的 env 选择,@ariffin 推荐如下:
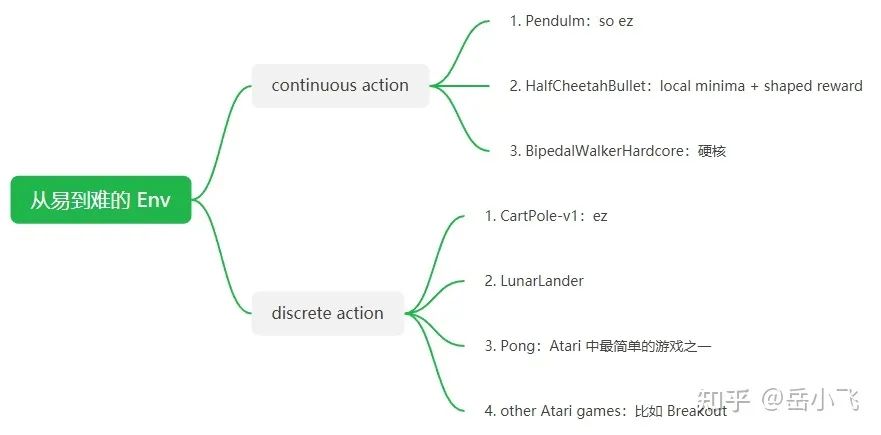
【RL Tips and Tricks -- End】
个人心得
个人是做机械臂+强化学习的,首先推荐一个机械臂的简单环境,建议先跑跑常见的 DQN、DDPG、SAC 等算法,可以配合 spinningup 使用,既学了怎么自定义 env,又学了 RL 算法。在简单环境中,可以尝试各种 shaped reward,测试 normalization 的影响。
自定义环境时,一定要注意 seed 对应的 np_random,这样能保证可复现。
observation:要提供足够多的 information,从数据完备性上要能解决问题。再说说 normalization,以机械臂为例:机械臂的角度一般在 [-π, π],实测角度作为 observation 的话可以不 normalization,但末端位置作为 observation 由于与连杆长度有关建议 normalization,不一定要严格到 [-1,1],推荐末端位置使用相对工具系的,这样与机械臂本体解耦,泛化能力更好。observation 中还可借鉴 Atari 游戏的 frame-stack,即把当前位置和上一位置组合,或者加入当前速度。
action:机械臂一般是 continuous action,使用相关 RL 算法时一定要 normalize 到 [-1,1],很重要。
reward:先 reward shaping,再说 sparse reward。多个不同的子 reward 要注意各自比例,不要让次要 reward 喧宾夺主。考虑到要让 agent 尽快完成任务,一般采用负的 reward。reward engineer 要耐心,多迭代几次。推荐定义一个 base env,派生不同 reward 的 env 分别训练好横向对比。
终止条件:可以 early stopping,也可试着 max steps,对于是真 done 还是超时 done 要区分。
网络结构:如果是向量输入,一般 2~3 个隐藏层足矣,每层 128 或 256 节点,ReLU 激活函数。
replay_buffer_size:设大一点,比如 1e6,很多时候缓存被放满前训练就收敛了,并不需要删除任何记忆。
原文链接
https://zhuanlan.zhihu.com/p/482656367
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码