
用强化学习通关超级马里奥!

DQN算法实践之速通超级马里奥
作为强化学习(Reinforce Learning,RL)的初学者,常常想将RL的理论应用于实际环境,以超级马里奥为例,当看着自己训练的AI逐渐适应环境,得分越来越高,到最后能完美躲避所有障碍,快速通关时,你肯定能体会到算法的魅力,成就感十足!本文不拘泥于DQN(Deep Q Learning Network)算法的深层原理,主要从代码实现的角度,为大家简洁直白的介绍DQN以及其改进方法,接着,基于Pytorch官方强化学习教程,应用改进后的DQN算法训练超级马里奥,并得到更为优秀的结果。
本文主要内容:
主要参考与项目地址:
算法理论参考:https://datawhalechina.github.io/easy-rl
算法代码参考:https://github.com/datawhalechina/easy-rl/tree/master/codesPytorch官方强化学习示例:
https://pytorch.org/tutorials/intermediate/mario_rl_tutorial.html
https://github.com/yfeng997/MadMario
本文项目地址:https://github.com/likemango/DQN-mario-xiaoyao
一、Basic DQN
DQN用一个神经网络替换Q-Learning中的最优动作价值函数Q*表格,弥补了Q-Learning只能表示有限个状态的缺陷。训练DQN网络模型常见的代码流程如下:
def train(cfg, env, agent):
''' 训练
'''
print('开始训练!')
print(f'环境:{cfg.env_name}, 算法:{cfg.algo_name}, 设备:{cfg.device}')
rewards = [] # 记录所有回合的奖励
ma_rewards = [] # 记录所有回合的滑动平均奖励
for i_ep in range(cfg.train_eps):
ep_reward = 0 # 记录一回合内的奖励
state = env.reset() # 重置环境,返回初始状态
while True:
action = agent.choose_action(state) # 选择动作
next_state, reward, done, _ = env.step(action) # 更新环境,返回transition
agent.memory.push(state, action, reward,
next_state, done) # 保存transition
state = next_state # 更新下一个状态
agent.update() # 更新智能体
ep_reward += reward # 累加奖励
if done:
break
rewards.append(ep_reward)
if ma_rewards:
ma_rewards.append(0.9 * ma_rewards[-1] + 0.1 * ep_reward)
else:
ma_rewards.append(ep_reward)
if (i_ep + 1) % 10 == 0:
print('回合:{}/{}, 奖励:{}'.format(i_ep + 1, cfg.train_eps, ep_reward))
print('完成训练!')
env.close()
return rewards, ma_rewards
其中cfg表示训练过程中的参数,env表示训练的交互环境,agent表示一个DQN的类对象。DQN类中的核心内容有:经验缓存(memory)、动作选择(choose_action)和模型参数更新(update)这三个部分:memory用于存储训练过程中的经验五元组(state,action,reward,next_state,done);choose_action方法实现了输入状态state,输出相应的动作结果,一般采用ε-greedy方法,探索概率为ε,网络选择动作概率为1-ε,这是DQN训练中重要的超参数之一;在update方法中,采样memory中的五元组信息,使用TD(temporary difference)算法进行计算出TD target和TD Error,再通过做反向梯度计算,最后做模型参数更新(https://datawhalechina.github.io/easy-rl/#/chapter3/chapter3?id=temporal-difference)。
Basic DQN能够解决一些简单的离散动作问题,例如gym环境中的“CartPole”,然而对于稍微复杂的环境却难以得到好的效果。DQN方法的缺点是存在非均匀的高估问题(OverEstimate),在多轮学习更新中,会造成最优动作价值函数Q*偏离真实值,使得网络无法输出正确的结果(https://datawhalechina.github.io/easy-rl/#/chapter7/chapter7)。
高估发生在两个地方:
1.Update中计算TD target时取最大化操作。
2.Update中的自举(bootstraping)操作。
二、Nature DQN
所谓自举,即利用网络模型自己去更新自己,既然自举会造成高估问题,那么可以不用网络本身去更新自己——一个直接的想法是使用另一个新的网络去更新DQN网络。新网络的模型结构与DQN本身一样,在计算TD target时使用该网络的计算结果,因而也称该网络为目标网络(target network)。结合上面介绍的Basic DQN,NatureDQN的实现如下(policy_net为DQN网络,target_net为目标网络):
class DQN:
def __init__(self, state_dim, action_dim, cfg):
self.action_dim = action_dim # 总的动作个数
self.device = cfg.device # 设备,cpu或gpu等
self.gamma = cfg.gamma # 奖励的折扣因子
# e-greedy策略相关参数
self.frame_idx = 0 # 用于epsilon的衰减计数
self.epsilon = lambda frame_idx: cfg.epsilon_end + (cfg.epsilon_start - cfg.epsilon_end) * \
math.exp(-1. * frame_idx / cfg.epsilon_decay)
self.batch_size = cfg.batch_size
self.policy_net = MLP(state_dim, action_dim,hidden_dim=cfg.hidden_dim).to(self.device)
self.target_net = MLP(state_dim, action_dim,hidden_dim=cfg.hidden_dim).to(self.device)
# 复制参数到目标网路targe_net
for target_param, param in zip(self.target_net.parameters(),self.policy_net.parameters()):
target_param.data.copy_(param.data)
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=cfg.lr) # 优化器
self.memory = ReplayBuffer(cfg.memory_capacity) # 经验回放
def choose_action(self, state):
''' 选择动作
'''
self.frame_idx += 1
if random.random() > self.epsilon(self.frame_idx):
with torch.no_grad():
state = torch.tensor([state], device=self.device, dtype=torch.float32)
q_values = self.policy_net(state)
action = q_values.max(1)[1].item() # 选择Q值最大的动作
else:
action = random.randrange(self.action_dim)
return action
def update(self):
if len(self.memory) < self.batch_size: # 当memory中不满足一个批量时,不更新策略
return
# 从经验回放中(replay memory)中随机采样一个批量的转移(transition)
state_batch, action_batch, reward_batch, next_state_batch, done_batch = self.memory.sample(
self.batch_size)
# 转为张量
state_batch = torch.tensor(state_batch, device=self.device, dtype=torch.float)
action_batch = torch.tensor(action_batch, device=self.device).unsqueeze(1)
reward_batch = torch.tensor(reward_batch, device=self.device, dtype=torch.float)
next_state_batch = torch.tensor(next_state_batch, device=self.device, dtype=torch.float)
done_batch = torch.tensor(np.float32(done_batch), device=self.device)
# 计算当前状态(s,a)对应的Q(s, a)
q_values = self.policy_net(state_batch).gather(dim=1, index=action_batch)
# 计算下一时刻的状态(s_t,a)对应的Q值
next_q_values = self.target_net(next_state_batch).max(1)[0].detach()
# 计算期望的Q值,对于终止状态,此时done_batch[0]=1, 对应的expected_q_value等于reward
expected_q_values = reward_batch + self.gamma * next_q_values * (1-done_batch)
loss = nn.MSELoss()(q_values, expected_q_values.unsqueeze(1)) # 计算均方根损失
# 优化更新模型
self.optimizer.zero_grad()
loss.backward()
for param in self.policy_net.parameters(): # clip防止梯度爆炸
param.grad.data.clamp_(-1, 1)
self.optimizer.step()
在一定更新回合后需要将DQN网络参数复制给目标网络,只需要在训练中增加如下代码:
if (i_ep + 1) % cfg.target_update == 0: # 智能体目标网络更新
agent.target_net.load_state_dict(agent.policy_net.state_dict())
三、Double DQN
在NatureDQN中,执行网络参数更新方法update时,用target_net计算next_q_values用到了取最大值操作,其目的是获得在状态next_state时,target_net取最大值的动作a*_target,并输出该最大值Q*_max_target值,这一步同样会造成高估问题。既然如此,不采用a*_target并减小Q*_max_target值,那么高估问题就能在一定程度得到缓解。
Double DQN的做法是利用policy_net在next_state时,policy_net取最大值的动作为a*_policy,然后再将该动作带入target_net中进行计算获得新的Q*_max_target^值。由于最优动作选自policy_net而不是target_net,所以容易得出target_net(next_state)[a*_target] >= target_net(next_state)[a*_policy],因此有Q*_max_target^ <=Q*_max_target,这样一定程度减小Q估计,缓解因自举高估带来的不稳定问题。在update方法中对expected_q_values的计算做如下修改:
# 计算当前状态(s,a)对应的Q(s, a)
q_values = self.policy_net(state_batch).gather(dim=1, index=action_batch)
# next_q_values = self.target_net(next_state_batch).max(1)[0].detach()
# 用policy_net计算下一个状态s_t的最优动作a*
next_action_batch = torch.argmax(self.policy_net(state_batch),axis=1).unsueeze(1)
# 用target_net计算下一时刻的状态(s_t_,a)对应的Q值
next_q_values = self.target_net(next_state_batch).gather(dim=1,index=next_action_batch)
# 计算期望的Q值,对于终止状态,此时done_batch[0]=1, 对应的expected_q_value等于reward
expected_q_values = reward_batch + self.gamma * next_q_values * (1-done_batch)
loss = nn.MSELoss()(q_values, expected_q_values.unsqueeze(1)) # 计算均方根损失
# 优化更新模型
self.optimizer.zero_grad()
loss.backward()
for param in self.policy_net.parameters(): # clip防止梯度爆炸
param.grad.data.clamp_(-1, 1)
self.optimizer.step()四、Dueling DQN
Dueling DQN与上述两种优化方式不同,它直接修改网络模型,用一个A*网络和V*网络去表示Q*,其中A*表示为最优优势函数(optimal advantage function),V*表示最优状态价值函数(optimal state value function ),它们三者的关系为A* = Q* - V*(https://datawhalechina.github.io/easy-rl/#/chapter7/chapter7?id=dueling-dqn)。
Dueling DQN与原始DQN网络结构的对比如下图所示:
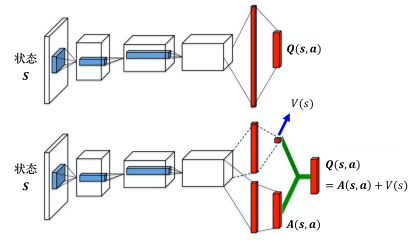
同时为了降低采用不同动作时Q*值的方差,实际中常用Q* = V* + A* - mean(A*)来进一步优化网络,加速收敛。在代码角度上,常见的 Dueling网络模型实现如下:
class DuelingNet(nn.Module):
def __init__(self, state_dim, action_dim,hidden_size=128):
super(DuelingNet, self).__init__()
# 隐藏层
self.hidden = nn.Sequential(
nn.Linear(state_dim, hidden_size),
nn.ReLU()
)
# 优势函数
self.advantage = nn.Sequential(
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, action_dim)
)
# 价值函数
self.value = nn.Sequential(
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 1)
)
def forward(self, x):
x = self.hidden(x)
advantage = self.advantage(x)
value = self.value(x)
# Q* = A* + V* - mean(A*)
return value + advantage - advantage.mean()
五、官方代码及模型分析
本文在DQN训练超级马里奥的项目中,参考了pytorch官方的强化学习教程,该教程代码耦合度低,逻辑结构清晰,非常值得初学者学习。核心代码及其功能如下图所示:

超级马里奥的训练环境来自
gym_super_mario_bros(https://github.com/flexpad/gym-super-mario-bros),代理(agent)与环境(env)交互返回的是游戏当前的RGB图像,因而在开始训练之前需要对图像做一系列的预处理操作,该教程的这部分工作做的十分完善,非常值得学习和借鉴。在完成预处理数据后,我们就集中精力在DQN的算法实现上。官方代码的具体分析可以在这篇文章中找到:https://zhuanlan.zhihu.com/p/402519441?utm_source=wechat_session&utm_medium=social&utm_oi=951210242982260736.
笔者应用该代码在实际训练中还发现一些问题:
首先是直接训练该模型对硬件设备要求高,很可能会出现显存不足的问题(报错:”CUDA out of memory”); 其次是训练结果模型效果不佳,根据官方提供的已训练完成的模型去测试(官方给出训练时间为GPU约20小时,CPU约80小时,但未说明具体设备),发现通关率仍然较低(笔者测试每回合累积奖励大约在1300~2000之间,小概率能够通关;笔者对模型修改后训练测试结果是稳定通关且每回合累积奖励3032); 最后是探索率设置不够合理,DQN模型训练完成后,在实际使用时应该将探索率ε设置为0,然而原作者依然给出了0.1的探索率,将该探索率设置为0后会出现每次agent都在同一地方失败(例如“卡墙角”)等现象,推测原作者之所以这样做,目的是防止agent总是在同样决策下走向相同的失败结局而有意增加了随机性,这有悖于DQN的算法原理。DQN算法的决策过程决定了它是一种确定性的策略,也就是说,对给定的输入状态,每次的输出结果都是相同的,如果在训练完成后,实际测试时还需要增加探索率去避免“卡墙角”或者“碰壁”等情况,那只能说明模型没有训练好,有待于对模型做进一步改进,最终训练好的结果一定是agent每次都会以相同的策略通关而不存在随机性;如果想得到每回合游戏有不一样的通关方式,那么就需要考虑采用其他算法,例如策略学习算法,每一次的动作做概率抽样。
六、模型改进
针对上述问题,笔者对官方模型做出如下修改:
修改经验缓存memory的大小。原则上来说,经验缓存越大,那么能够存储更加久远的对局信息,是有助于模型学习与改进的,然而受限于硬件显存空间的问题,可以考虑降低经验缓存的大小;而且基于直觉判断,超级马里奥第一关的环境也并没有太过复杂,因而适当降低缓存大小,在较为低配的硬件设备上依然可以得到不错的训练效果。(笔者机器配置为i7-9750H和GTX1660Ti,显存6G,笔者在本机和Colab上均做过尝试,将memory从100000调整为18000可以完成训练。如果不更改配置至少需要20G显存,读者可更具机器硬件情况进行调整)。 模型改进。将官方给出D2QN(Nature DQN + Double DQN)改为D3QN(Nature DQN + Double DQN + Dueling DQN).DQN算法本身不可避免的存在高估等问题,使用这些DQN变体能够大幅提高DQN算法的准确性和稳定性(https://zhuanlan.zhihu.com/p/98784255?utm_source=wechat_session&utm_medium=social&utm_oi=951210242982260736)。在官方代码基础上,使用Dueling network对原文件中”neural.py”的网络模型进行修改。 调整超参数。将探索率ε的最小值设置为0,设置更大的BatchSize并减小的学习率,DQN调参可以参考(https://zhuanlan.zhihu.com/p/345353294)
七、训练结果
笔者使用笔记本训练,总时间为24+13+10=47小时,根据不同的硬件环境,训练时间可能会有较大变化。0~24小时、24~37小时、37~47小时三个阶段每百回合平均奖励的变化如图所示:
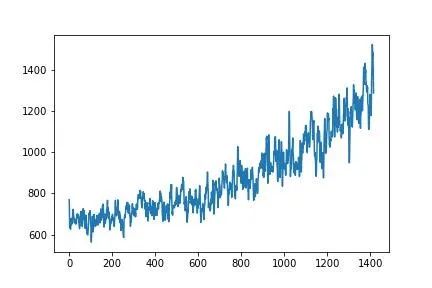

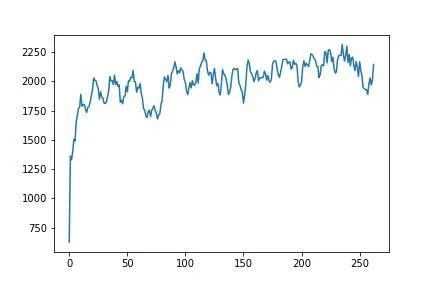
从图中可以看出,在局部区域奖励波动较大,一般属于正常情况,总体上看,平均奖励是随着训练的进行而上升的,说明模型的表现已经越来越好。在训练之余,还可以通过replay.py对已经训练出来的模型进行测试,以验证模型学习的进步(最后一个阶段的奖励虽然在升高,但是还没有达到测试时的3032,原因是此时依然有较低的概率在做随机探索。同时,强化学习的模型并不是训练的越久越好,选择训练阶段中奖励更高的模型往往会是一种更优的选择)。测试模型结果:

八、总结
DQN算法作为强化学习的入门算法之一,将强化学习的核心理论(马尔科夫决策过程、贝尔曼方程等)清晰的融入到算法的实现中,基于DQN算法中的问题,又催生出各式各样DQN算法变体,大幅提高了算法的有效性。在解决离散动作空间的问题上,D3QN(Dueling DDQN)通常都具有不错的表现。大家可以结合实际游戏环境或者参考项目源代码,训练出属于你自己的超级马里奥!
干货学习,点赞三连↓