
【论文解读】医学AI论文解读 | 超声心动图在临床中的自动化检测 | Circulation | 2018 | 中英双语
0 论文
1 概述
2 pipeline
3 技术细节
3.1 预处理
3.2 卷积网络
3.3 VGG分类网络结构
3.4 图像分割
4 遇到的问题
0 论文
论文是2018年的,发表在医学期刊《Circulation》(影响因子20+)的一篇文章《Fully Automated Echocardiogram Interpretation in Clinical Practice》 (超声心动图在临床中的自动化检测)。现在对于整体的学习做一个回顾,可以当成导读:整个文章的算法方面不难,分类模型用的VGG,分割模型用的Unet,损失函数中规中矩,图片处理中规中矩,算是一个老方法在医学领域的一个使用。本文包含三个部分,英文的论文原文内容,宋体的百度翻译内容,以及加粗字体的我的理解与精炼的内容。
1 概述
Using 14 035 echocardiograms spanning a 10-year period, we trained and evaluated convolutional neural network models for multiple tasks, including automated identification of 23 viewpoints and segmentation of cardiac chambers across 5 common views. The segmentation output was used to quantify chamber volumes and left ventricular mass, determine ejection fraction, and facilitate automated determination of longitudinal strain through speckle tracking. Results were evaluated through comparison to manual segmentation and measurements from 8666 echocardiograms obtained during the routine clinical workflow. Finally, we developed models to detect 3 diseases: hypertrophic cardiomyopathy, cardiac amyloid, and pulmonary arterial hypertension.
我们使用了10年的14035张超声心动图,训练和评估了用于多个任务的卷积神经网络模型,包括23个视点的自动识别和5个常见视图的心腔分割。分割输出用于量化腔容积和左心室质量,确定射血分数,并通过散斑跟踪自动确定纵向应变。通过与手工分割和常规临床工作流程中获得的8666张超声心动图的测量结果进行比较来评估结果。最后,我们建立了三种疾病的模型:肥厚型心肌病、心脏淀粉样蛋白和肺动脉高压。
Convolutional neural networks accurately identified views (eg, 96% for parasternal long axis), including flagging partially obscured cardiac chambers, and enabled the segmentation of individual cardiac chambers. The resulting cardiac structure measurements agreed with study report values (eg, median absolute deviations of 15% to 17% of observed values for left ventricular mass, left ventricular diastolic volume, and left atrial volume). In terms of function, we computed automated ejection fraction and longitudinal strain measurements (within 2 cohorts), which agreed with commercial software-derived values (for ejection fraction, median absolute deviation=9.7% of observed, N=6407 studies; for strain, median absolute deviation=7.5%, n=419, and 9.0%, n=110) and demonstrated applicability to serial monitoring of patients with breast cancer for trastuzumab cardiotoxicity. Overall, we found automated measurements to be comparable or superior to manual measurements across 11 internal consistency metrics (eg, the correlation of left atrial and ventricular volumes). Finally, we trained convolutional neural networks to detect hypertrophic cardiomyopathy, cardiac amyloidosis, and pulmonary arterial hypertension with C statistics of 0.93, 0.87, and 0.85, respectively.
卷积神经网络能准确识别视野(例如胸骨旁长轴为96%),包括部分模糊的心腔,并能分割单个的心腔。左心室容积测量值与左心室容积绝对值的17%一致。在功能方面,我们计算了自动射血分数和纵向应变测量值(在两个队列内),这与商业软件得出的值一致(射血分数,中值绝对偏差=观察值的9.7%,N=6407研究;对于应变,中值绝对偏差=7.5%,N=419,和9.0%,n=110),并证明适用于对乳腺癌患者进行曲妥珠单抗心脏毒性的连续监测。总的来说,我们发现在11个内部一致性指标(例如,左心房和心室容积的相关性)中,自动测量与手动测量相当或优于人工测量。最后,我们训练了卷积神经网络来检测肥厚性心肌病、心脏淀粉样变性和肺动脉高压,其C统计量分别为0.93、0.87和0.85。
2 pipeline
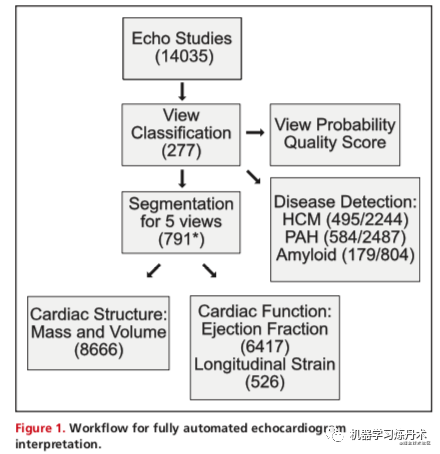 先对数据进行分类,然后再做分割。
先对数据进行分类,然后再做分割。
Preprocessing entailed automated downloading of echocardiograms in Digital Imaging and Communications in Medicine format, separating videos from still images, extracting metadata (eg, frame rate, heart rate), converting them into numeric arrays for matrix computations, and deidentifying images by overwriting patient health information. We next used convolutional neu- ral networks (described later) for automatically determining echocardiographic views. Based on the identified views, videos were routed to specific segmentation models (parasternal long axis [PLAX], parasternal short axis, apical 2-chamber [A2c], api- cal 3-chamber, and apical 4-chamber [A4c]), and the output was used to derive chamber measurements, including lengths, areas, volumes, and mass estimates. Next, we generated 2 commonly used automated measures of left ventricular (LV) function: ejection fraction and longitudinal strain. Finally, we derived models to detect 3 diseases: hypertrophic cardiomyop- athy, pulmonary arterial hypertension, and cardiac amyloidosis.
预处理需要自动下载医学格式的数字成像和通信中的超声心动图,从静态图像中分离视频,提取元数据(例如帧速率、心率),将其转换为矩阵计算的数字数组,以及通过覆盖患者健康信息来消除图像的标识。下一步我们使用卷积神经网络(稍后描述)来自动确定超声心动图视图。【这一步应该就是对图进行分类】,根据确定的视图,视频被路由到特定的分割模型(胸骨旁长轴[PLAX]、胸骨旁短轴、心尖2腔[A2c]、api-cal3腔和心尖4腔[A4c])【这里知道应该是一个5分类的任务】,输出用于推导腔室测量值,包括长度、面积、体积和质量估计值。接下来,我们生成了两种常用的左心室功能自动测量方法:射血分数和纵向应变。最后,我们建立了检测3种疾病的模型:肥厚型心肌病、肺动脉高压和心脏淀粉样变性。
3 技术细节
Specifically, 277 echocardiograms col- lected over a 10-year period were used to derive a view clas- sification model (Table II in the online-only Data Supplement). The image segmentation model was trained from 791 images divided over 5 separate views (Table III in the online-only Data Supplement). Comparison of automated and manual mea- surements was made against 8666 echocardiograms, with the majority of measurements made from 2014 to 2017 (Table IV in the online-only Data Supplement). For this pur- pose, we used all studies where these measurements were available (ie, there was no selection bias). The number of images used for training the different segmentation models was not planned in advance, and models were retrained as more data accrued over time. From initial testing, we rec- ognized that at least 60 images would be needed, and we allocated more training data and resources to A2c and A4c views because these were more central to measurements for both structure and function.
具体而言,在10年的时间里收集了277张超声心动图,用于推导视图分类模型(仅在线数据补充中的表II)。图像分割模型是从791张图像中训练出来的,这些图像分为5个独立的视图(表3,仅在线数据补充)。将自动和手动测量与8666个超声心动图进行了比较,大多数测量是在2014年至2017年进行的(仅在线数据补充中的表IV)。对于这个目标,我们使用了所有这些测量数据可用的研究(即,没有选择偏差)。用于训练不同分割模型的图像数量没有事先计划好,随着时间的推移积累更多的数据,模型被重新训练。从最初的测试中,我们发现至少需要60幅图像,并且我们为A2c和A4c视图分配了更多的训练数据和资源,因为这两个视图对结构和功能的测量更为重要。
从中可以知道:【训练的时候使用的样本只有几百个就足够了】
3.1 预处理
We identified 260 patients at UCSF who met guideline-based criteria for hypertrophic cardiomyopathy: “unexplained left ventricular (LV) hypertrophy (maximal LV wall thickness ≥ 15 mm) associated with nondilated ventricular chambers in the absence of another cardiac or systemic disease that itself would be capable of producing the magnitude of hypertro- phy evident in a given patient.”9 These patients were selected from 2 sources: the UCSF Familial Cardiomyopathy Clinic and the database of clinical echocardiograms. Patients had a variety of thickening patterns, including upper septal hyper- trophy, concentric hypertrophy, and predominantly apical hypertrophy. A subset of patients underwent genetic testing. Overall, 18% of all patients had pathogenic or likely patho- genic mutations. We downloaded all echocardiograms within the UCSF database corresponding to these patients and confirmed evidence of hypertrophy. We excluded bicycle, treadmill, and dobutamine stress echocardiograms because these tend to include slightly modified views or image anno- tations that could have confounding effects on models trained for disease detection. We also excluded studies of patients conducted after septal myectomy or alcohol septal ablation and studies of patients with pacemakers or implantable defibrillators. Control patients were also selected from the UCSF echocardiographic database. For each hypertrophic cardiomyopathy (HCM) case study, ≤5 matched control studies were selected, with matching by age (in 10-year bins), sex, year of study, ultrasound device manufacturer, and model. This process was simplified by organizing all of our studies in a nested format in a python dictionary so we can look up studies by these characteris- tics. Given that the marginal cost of analyzing additional samples is minimal in our automated system, we did not perform a greedy search for matched controls. Case, con- trol, and study characteristics are described in Table V in the online-only Data Supplement.
We did not require that cases were disease-free, only that they did not have HCM.
我们在加州大学旧金山分校发现了260名符合肥厚性心肌病指南标准的患者:“未解释的左心室(LV)肥大(最大左室壁厚≥15 mm)与非扩张性心室室有关,而另一种心脏或系统性疾病本身能够产生这些患者选自2个来源:加州大学旧金山分校家族性心肌病诊所和临床超声心动图数据库。患者有各种各样的增厚模式,包括上中隔高营养型,向心性肥大和以心尖肥大为主。一部分病人接受了基因检测。总的来说,18%的患者有致病性或可能的致病性突变。我们下载了加州大学旧金山分校数据库中与这些患者相对应的所有超声心动图,并确认了肥大的证据。我们排除了bicycle、treadmill和多巴酚丁胺负荷超声心动图,因为这些超声心动图往往包括稍微修改的视图或图像注释,可能会对模型产生混淆的影响
接受疾病检测训练。我们也排除了对间隔肌切除术或酒精性间隔消融术后患者的研究,以及对使用起搏器或植入式除颤器的患者的研究。对照组患者也从加州大学旧金山分校超声心动图数据库中选择。对于每一个肥厚型心肌病(HCM)病例研究,选择≤5个匹配的对照研究,按年龄(以10年为单位)、性别、研究年份、超声设备制造商和型号进行匹配。通过在python字典中以嵌套格式组织我们的所有研究,我们可以通过这些特征来查找研究,从而简化了这个过程。考虑到分析额外样本的边际成本在我们的自动化系统中是最小的,我们没有执行贪婪的搜索匹配的控制。病例、对照和研究特点在仅在线数据补充中的表V中描述。我们没有要求病例是无病的,只是他们没有HCM。
(补充资料)Additionally, each echocardiogram contains periphery information unique to different output settings on ultrasound machines used to collect the data. This periphery information details additional details collected (i.e. electrocardiogram, blood pressure, etc.). To improve generalizability across institutions, we wanted the classification of views to use ultrasound data and not metadata presented in the periphery. To address this issue, every image is randomly cropped between 0-20 pixels from each edge and resized to 224x224 during training. This provides variation in the periphery information, which guides the network to target more relevant features and improves the overall robustness of our view classification models.
此外,每个超声心动图都包含用于收集数据的超声机器上不同输出设置的外围信息。此外围信息详细说明了收集到的其他详细信息(即心电图、血压等)。为了提高跨机构的概括性,我们希望视图的分类使用超声数据,而不是外围显示的元数据。为了解决这个问题,每个图像从每个边缘随机裁剪0-20像素,并在训练期间调整为224x224。提高了我们的分类模型的鲁棒性,为我们的网络分类提供了更多的相关信息。
(补充资料)Training data comprised of 10 random frames from each manually labeled echocardiographic video. We trained our network on approximately 70,000 pre -processed images. For stochastic optimization, we used the ADAM optimizer2 with an initial learning rate of 1e-5 and mini-batch size of 64. For regularization, we applied a weight decay of 1e-8 on all network weights and dropout with probability 0.5 on the fully connected layers. We ran our tests for 20 epochs or ~20,000 iterations, which takes ~3.5 hours on a Nvidia GTX 1080. Runtime per video was 600 ms on average.
Accuracy was assessed by 5-fold cross-validation at the individual image level. When deploying the model, we would average the prediction probabilities for 10 randomly selected images from each video.
训练数据由10个随机帧组成,来自每个手动标记的超声心动图视频。我们在大约70000张预处理图像上训练了我们的网络。对于随机优化,我们使用ADAM优化器2,初始学习率为1e-5,最小批量为64。对于正则化,我们对所有网络权重和完全连接层的概率为0.5的脱落。我们测试了20个时代或20000次迭代,在nvidiagtx1080上需要大约3.5小时。每段视频的运行时间平均为600毫秒。在5倍图像水平上对个体准确性进行评估。在部署该模型时,我们将平均每个视频中随机选择的10个图像的预测概率。
【论文中做的预处理】:
我们排除了bicycle、treadmill和多巴酚丁胺负荷超声心动图,因为这些超声心动图往往包括稍微修改的视图或图像注释,可能会对模型产生混淆的影响; 我们也排除了对间隔肌切除术或酒精性间隔消融术后患者的研究,以及对使用起搏器或植入式除颤器的患者的研究。 对照组患者也从加州大学旧金山分校超声心动图数据库中选择。 为了提高跨机的鲁棒性,从每个图片的每个边缘随机剪裁0到20个像素,并在训练期间调整成224x224大小。 一个标注的视频中抽取10个视频帧作为训练的输入,所以右7W个输入,这个卷积也是2D的卷积,在推理阶段把10个帧的预测值的均值作为视频的预测值
3.2 卷积网络
We first developed a model for view classification. Typical echocardiograms consist of ≥70 separate videos representing multiple viewpoints. Furthermore, with rotation and adjust- ment of the zoom level of the ultrasound probe, sonogra- phers actively focus on substructures within an image, thus creating many variations of these views. Unfortunately, none of these views is labeled explicitly. Thus, the first learning step involves teaching the machine to recognize individual echo- cardiographic views. Models are trained using manual labels assigned to indi- vidual images. Using the 277 studies described earlier, we assigned 1 of 30 labels to each video (eg, parasternal long axis or subcostal view focusing on the abdominal aorta). Because discrimination of all views (subcostal, hepatic vein versus subcostal, inferior vena cava) was not necessary for our downstream analyses, we ultimately used only 23 view classes for our final model (Table IX in the online-only Data Supplement). The training data consisted of 7168 individually labeled videos.
我们首先开发了一个视图分类模型。典型的超声心动图包括≥70个独立的视频,代表多个视点。此外,随着超声探头的旋转和缩放水平的调整,超声工作者会主动聚焦于图像中的子结构,从而产生许多不同的视图。不幸的是,这些视图都没有明确标记。因此,第一个学习步骤包括教机器识别个别的心脏回声图视图。使用分配给单个图像的手动标签来训练模型。利用前面描述的277项研究,我们为每个视频指定了30个标签中的一个(例如胸骨旁长轴或肋下视野聚焦于腹主动脉)。因为我们的下游分析不需要区分所有视图(肋下、肝静脉与肋下、下腔静脉),我们最终只使用了23个视图类作为最终模型(仅在线数据补充中的表IX)。训练数据包括7168个单独标记的视频。
3.3 VGG分类网络结构
【简单总结一下】:就是超声心动图数据是包含不同的视角的,所以需要先对视角进行分类,这里分成了30类,手动标准了277个图。然后训练好分类模型,选取30类中的23个类作为下一阶段的模型的数据。所以还剩下7168个视频
The VGG network1 takes a fixed-sized input of grayscale images with dimensions 224x224 pixels (we use scikit-image to resize by linear interpolation). Each image is passed through ten convolution layers, five max-pool layers, and three fully connected layers. (We experimented with a larger number of convolution layers but saw no improvement for our task). All co nvolutional layers consist of 3x3 filters with stride 1 and all max-pooling is applied over a 2x2 window with stride 2. The convolution layers consist of 5 groups of 2 convolution layers, which are each followed by 1 max pool layer. The stack of convolutions is followed by two fully connected layers, each with 4096 hidden units, and a final fully connected layer with 23 output units. The output is fed into a 23-way softmax layer to represent 23 different echocardiographic views. This final step represents a standard multinomial logistic regression with 23 mutually exclusive classes. The predictors in this model are the output nodes of the neural network. The view with the highest probability was selected as the predicted view.
VGG network1采用尺寸为224x224像素的固定大小的灰度图像输入(我们使用scikit图像通过线性插值调整大小)。每个图像通过十个卷积层、五个最大池层和三个完全连接的层。(我们尝试了大量的卷积层,但没有发现我们的任务有任何改进)。所有共决层由3x3过滤器组成,步长为1,所有max池应用于步长为2的2x2窗口上。卷积层由5组2个卷积层组成,每个卷积层后面有1个最大池层。卷积之后是两个完全连接的层,每个层有4096个隐藏单元,最后一个完全连接层有23个输出单元。输出被送入23路softmax层,以表示23种不同的超声心动图视图。最后一步是标准的多项式logistic回归,有23个互斥类。该模型中的预测因子是神经网络的输出节点。选择概率最大的视图作为预测视图。
3.4 图像分割
To train image segmentation models, we derived a CNN based on the U-net architecture described by Ronneberger et al3. The U-net-based network we used accepts a 384x384 pixel fixed-sized image as input, and is composed of a contracting path and an expanding path with a total of 23 convolutional layers. The contracting path is composed of twelve convolutional layers with 3x3 filters followed by a rectified linear unit and four max pool layers each using a 2x2 window with stride 2 for down-sampling. The expanding path is composed of ten convolutional layers with 3x3 filters followed by a rectified linear unit, and four 2x2 up-convolution layers. Every up- convolution in the expansion path is concatenated with a feature map from the contracting path with same dimension. This is performed to recover the loss of pixel and feature locality due to downsampling images, which in turn enables pixel-level classification. The final layer uses a 1x1 convolution to map each feature vector to the output classes. Separate U-net CNN networks were trained to perform segmentation on images from PLAX, PSAX (at the level of the papillary muscle), A4c, A3c, and A2c views. Training data was derived for each class of echocardiographic view via manual segmentation. We performed data augmentation techniques including cropping and blacking out random areas of the echocardiographic image in order to improve model performance in the setting of a limited amount of training data. The rationale is that models that are robust to such variation are likely to generalize better to unseen data. Training data underwent varying degrees of cropp ing (or no cropping) at random amounts for each edge of the image. Similarly, circular areas of random size set at random locations in the echocardiographic image were set to 0-pixel intensity to achieve ''blackout''.This U-net architecture and the data augmentationtechniques enabled highly efficient training, achieving accurate segmentation from a relatively low number of training examples. Finally, in addition to pixelwise cross-entropy loss, we included a distance-based loss penalty for misclassified pixels. The loss function was based on the distance from the closest pixel with the same misclassified class in the ground truth image. This helped mitigate erroneous pixel predictions across the images. We used an Intersection Over Union (IoU) metric for assessment of results. The IoU takes the number of pixels which overlap between the ground truth and automated segmentation (for a given class, such as left atrial blood pool) and divides them by the total number of pixels assigned to that class by either method. It ranges between 0 and 100.
为了训练图像分割模型,我们推导了一个基于Ronneberger等人描述的U-net结构的CNN。我们使用的基于U-net的网络接受384x384像素的固定尺寸图像作为输入,由收缩路径和扩展路径组成,共有23个卷积层。收缩路径由12个带3x3滤波器的卷积层和4个最大池层组成,每个层使用2x2窗口和步长2进行下采样。扩展路径由10个带3x3滤波器的卷积层和4个2x2向上卷积层组成。扩展路径中的每一个上卷积都与来自相同维数收缩路径的特征映射相连接。执行此操作是为了恢复由于图像的下采样而丢失的像素和特征局部性,这反过来又支持像素级分类。最后一层使用1x1卷积将每个特征向量映射到输出类。训练独立的U-netcnn网络对PLAX、PSAX(乳头肌水平)、A4c、A3c和A2c视图的图像进行分割。训练数据是通过人工分割得到的每一类超声心动图视图。为了在有限的训练数据环境下提高模型的性能,我们采用了数据增强技术,包括裁剪和去除超声心动图图像的随机区域。其基本原理是,对这种变化具有鲁棒性的模型很可能会更好地概括为看不见的数据。训练数据经历了不同程度的裁剪(或不裁剪),对图像的每个边缘进行随机数量的裁剪。同样,在超声心动图图像中随机位置设置的随机大小的圆形区域被设置为0像素强度,以实现“断电”。这种U-net结构和数据增强技术实现了高效的训练,从相对较少的训练样本中实现了精确的分割。最后,除了像素交叉熵损失,我们还包括了基于距离的损失惩罚
错误分类的像素。损失函数是基于距离地面真实图像中同一类错误分类的最近像素的距离。这有助于减少图像中错误的像素预测。我们使用了一个相交于联合(IoU)度量来评估结果。IoU取基本真实值和自动分割(对于给定的类别,如左心房血池)之间重叠的像素数,并除以通过任一方法分配给该类别的像素总数。范围在0到100之间。
【简单的解读】
使用的模型是Unet,然后输入数据是2D图像384x384大小,然后网络结构就是23个卷积层,比较常规,由收缩路径和扩展路径组成,共有23个卷积层。收缩路径由12个带3x3滤波器的卷积层和4个最大池层组成,每个层使用2x2窗口和步长2进行下采样。扩展路径由10个带3x3滤波器的卷积层和4个2x2向上卷积层组成。
因为数据有限,所以使用了剪裁(之前提到的对边缘进行剪裁)、去除随机区域(模拟断电现象)。损失函数除了交叉熵,还有对于分类错误的像素有基于距离的损失,这个距离是指与其他同样被预测错误类别的像素之间的距离。我觉得应该是距离越远,惩罚越大,距离越近惩罚越小,保证像素尽可能的聚成一团。
算法的衡量标准是IoU指标。
4 遇到的问题
During the training process, we found that our CNN models readily segmented the LV across a wide range of videos from hundreds of studies, and we were thus interested in understanding the origin of the extreme outliers in our Bland-Altman plots (Figure 4). We under- took a formal analysis of the 20 outlier cases where the discrepancy between manual and automated measure- ments for LV end diastolic volume was highest (>99.5th percentile). This included 10 studies where the auto- mated value was estimated to be much higher than manual (DiscordHI) and 10 where the reverse was seen (DiscordLO). For each study, we repeated the manual LV end diastolic volume measurement. For every 1 of the 10 studies in DiscordHI, we de- termined that the automated result was in fact cor- rect (median absolute deviation=8.6% of the repeat manual value), whereas the prior manual measure- ment was markedly inaccurate (median absolute devia- tion=70%). It is unclear why these incorrect values had been entered into our clinical database. For DiscordLO (ie, much lower automated value), the results were mixed. For 2 of the 10 studies, the automated value was correct and the previous manual value erroneous; for 3 of the 10, the repeated value was intermediate between automated and manual. For 5 of the 10 stud- ies in DiscordLO, there were clear problems with the au-
tomated segmentation. In 2 of the 5, intravenous con- trast had been used in the study, but the segmentation algorithm, which had not been trained on these types of data, attempted to locate a black blood pool. The third poorly segmented study involved a patient with complex congenital heart disease with a double out- let right ventricle and membranous ventricular septal defect. The fourth study involved a mechanical mitral valve with strong acoustic shadowing and reverbera- tion artifact. Finally, the fifth poorly segmented study had a prominent calcified false tendon in the LV com- bined with a moderately sized pericardial effusion. This outlier analysis thus highlighted the presence of inac- curacies in our clinical database as well as the types of studies that remain challenging for our automated segmentation algorithms.
在培训过程中,我们发现我们的CNN模型很容易将LV分割成来自数百个研究的大量视频,因此我们对理解我们平淡无奇的Altman图中极端异常值的来源很感兴趣(图4)。我们对20例异常病例进行了正式分析,其中左室舒张末期容积的手动和自动测量之间的差异最大(>99.5%)。这包括10项研究,其中自动匹配值估计远高于手动(DiscordHI)和10项发现相反(DiscordLO)的研究。对于每项研究,我们重复手动左室舒张末期容积测量。对于DiscordHI的10项研究中的每一项,我们确定自动结果实际上是正确的(中值绝对偏差=重复手动值的8.6%),而先前的手动测量明显不准确(绝对偏差中值=70%)。目前尚不清楚为什么这些不正确的数值被输入到我们的临床数据库中。对于DiscordLO(即自动化值低得多),结果是混合的。在10项研究中,有2项的自动值是正确的,以前的手动值是错误的;在10项研究中,有3项重复值介于自动和手动之间。在不和谐的10个种马中,有5个是明显的问题-
自动分割。在这5项研究中,有2项采用了静脉注射法,但分割算法,没有经过训练,这些类型的数据,试图定位一个黑色血泊。第三个分段较差的研究涉及一个复杂的先天性心脏病患者,右心室双出口和膜性室间隔缺损。第四项研究涉及一个机械二尖瓣与强声影和混响伪影。最后,第五个分段不良的研究发现左室有明显钙化假腱,并伴有中等大小的心包积液。因此,这种异常值分析突出了我们的临床数据库中存在的不精确性,以及对我们的自动分割算法仍然具有挑战性的研究类型。
【个人的理解就是】训练过程中,CNN模型是有能力从大量的视频中分辨出LV左心室的位置的,因此他们对一些分割错误的异常值非常的好奇,最后的结果是发现少部分的异常值的标注是错误的,一部分的预测值是错误的。而错误的样本中,有一半是因为出现了患者使用了静脉注射的方法,而这类的方法事先并没有训练模型;另外一半是因为患者的心脏是非常特殊的(合并右心室双出口和膜性室间隔缺损的复杂先天性心脏病患者)。
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群请扫码: