NeruIPS 2022 | 腾讯AI Lab入选论文解读
腾讯 AI Lab 共有 13 篇论文被本届会议接收,其中 1 篇被选为口头报告,以及 2 篇 Spotlight。本文为部分论文解读,主要聚焦机器学习及计算机视觉领域,并关注 AI 与生命科学领域的结合应用。

机器学习
Learning Neural Set Functions Under the Optimal Subset Oracle
基于最优子集的神经集合函数学习方法EquiVSet
本文由腾讯 AI Lab 主导,与帝国理工大学,中山大学合作完成,已被会议选为口头报告(Oral Presentation)。
集合函数被广泛应用于各种场景之中,例如商品推荐、异常检测和分子筛选等。在这些场景中,集合函数可以被视为一个评分函数:其将一个集合作为输入并输出该集合的分数。我们希望从给定的集合中选取出得分最高的子集。鉴于集合函数的广泛应用,如何学习一个适用的集合函数是解决许多问题的关键。
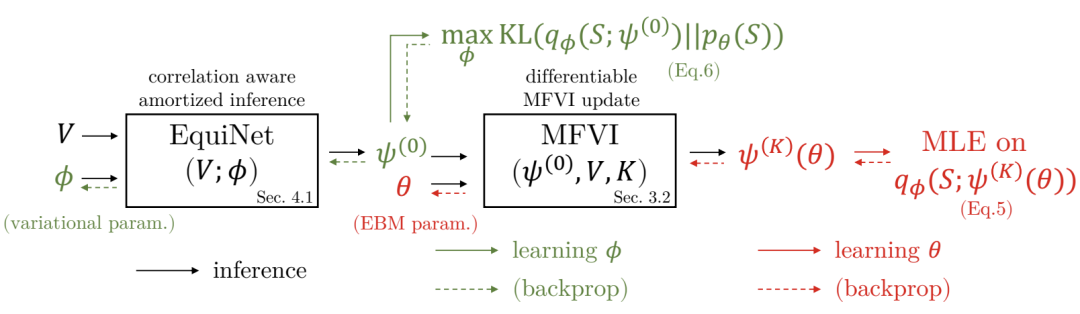
本工作提出了一个基于最大似然的集合函数学习方法EquiVSet。该方法满足以下四个集合函数学习的准则:1)置换不变性;2)支持不同的集合大小;3)最小先验;4)可扩展性。该方法由以下部件组成:基于能量模型的集合概率质量函数;满足置换不变性的DeepSet类型架构;平均场变分推断和它的均摊版本。由于这些结构的巧妙组合,本文提出的方法在三个实际应用场景中(商品推荐,异常检测和分子筛选)的性能远远超过基线方法。
Stability Analysis and Generalization Bounds of Adversarial Training
对抗训练的稳定性分析和泛化边界
本文由腾讯 AI Lab 主导,与香港中文大学(深圳),深圳市大数据研究院合作完成,已被会议评为 Spotlight 论文。
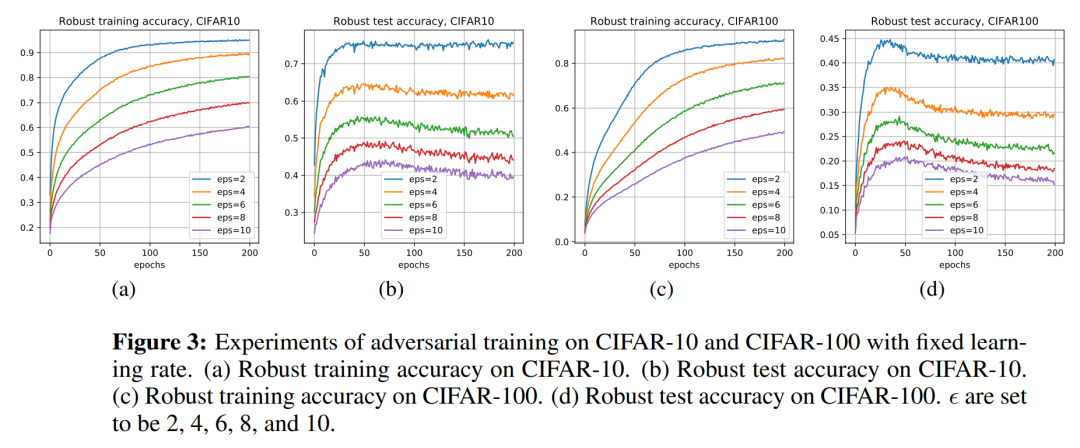
在对抗训练中,深度神经网络可以非常好的拟合训练数据集上的对抗样本,但针对测试集上的对抗样本泛化能力较差,这种现象称为鲁棒性过拟合,并且在常见数据集(包括 SVHN、CIFAR-10、CIFAR-100 和 ImageNet)上对神经网络进行对抗训练时均可以观察到这种现象。
本文采用一致稳定性的工具来研究对抗性训练的鲁棒性过拟合问题。一个主要挑战是对抗训练的外层函数是不光滑的,使得现有的分析技术无法直接应用过来。为了解决这个问题,本文提出了 η 近似平滑度假设。我们表明对抗训练的外层函数满足η 平滑度假设,其中 η 是与对抗扰动量相关的一个常数。针对满足 η 近似平滑度的损失函数(包括对抗训练损失),本文给出了随机梯度下降 (SGD)算法的基于稳定性的泛化边界。
该项工作的结果从一致稳定性的角度提供了对鲁棒性过拟合的不同理解。此外,文章展示了一些流行的对抗性训练技术(包括早期停止、循环学习率和随机权重平均等)在理论上可以促进稳定性。
Adversarial Task Up-sampling for Meta-learning
基于对抗任务上采样的元学习任务增广
本文由腾讯 AI Lab 主导,与香港城市大学合作完成。
元学习的成功是基于训练任务的分布涵盖测试任务的假设。如果训练任务不足或训练任务分布非常集中,这个假设不再成立,从而导致元学习模型出现数据记忆或者过度拟合,损害元学习模型在新任务的泛化性。这个问题的解决方案是对训练任务进行任务增广,但如何产生大量的有效增广任务仍然是一个待解决的问题。
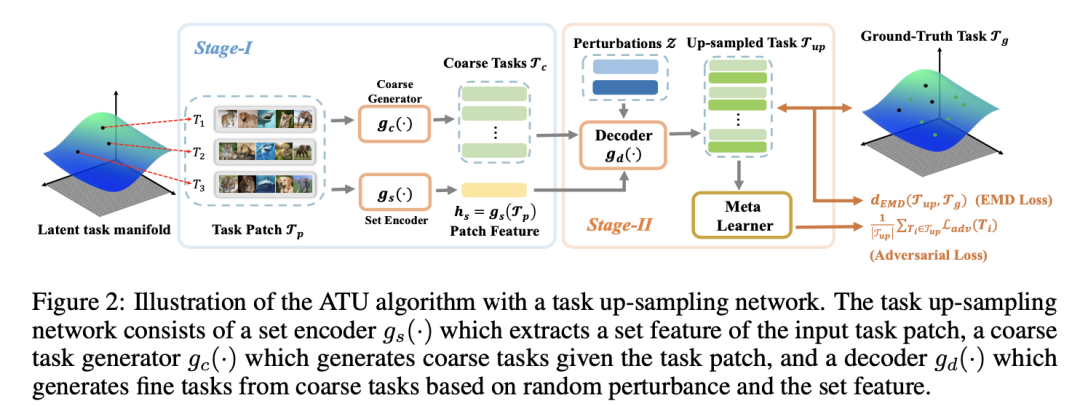
本文提出通过任务上采样网络,学习任务的表示和基于对抗的上采样算法(Adversarial Task Up-sampling, ATU),并从任务表示中应用上采样算法采样增广任务。通过最大化对抗性损失,增广任务可以最大程度地提高元学习模型的泛化能力。在小样本正弦回归和图像分类数据集上,我们实验验证了ATU的增广任务生成质量和对元学习算法泛化性的提高明显超越已有的元学习任务增广算法。
Improve Task-Specific Generalization in Few-Shot Learning via Adaptive Vicinal Risk Minimization
提高小样本学习的任务泛化性——基于任务自适应VRM的单任务优化算法
本文由腾讯 AI Lab 主导,与香港城市大学合作完成。
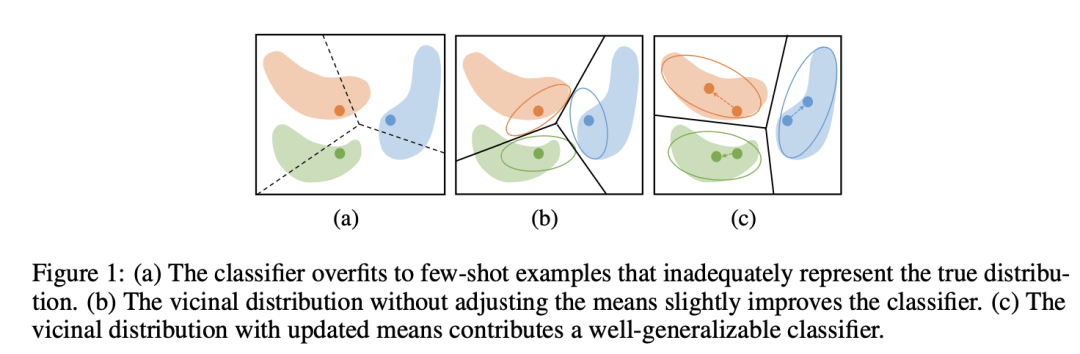
元学习算法提高了小样本学习中总体任务的泛化能力,但是忽略了单任务的泛化能力。由于小样本学习任务中,训练数据的分布可能偏离真实分布,通过ERM优化的模型难以泛化到未见过的数据。
为了解决该问题,本文提出基于任务自适应的临近分布损失最小化算法(Adaptive Vicinal Risk Minimization)。 该项工作使用随机游走算法,计算训练数据访问无标签数据的概率,并根据这个概率分布为每个训练数据构建临近分布。训练数据的临近分布可以更好地拟合数据的真实分布,从而降低过拟合,提高优化算法对单个任务的泛化性。在三个标准的小样本学习的数据集上,本文提出的算法明显超越了基线算法。
计算机视觉
OST: Improving Generalization of DeepFake Detection via One-Shot Test-Time Training
OST:一种提高假脸检测泛化性的方法
本文由腾讯 AI Lab 主导,与阿德莱德大学合作完成。
现有的假脸检测方法普遍存在泛化性不足的问题:当造假方法未出现在训练阶段时,现有的方法通常不能有效的判断给定人脸图片的真假。
本文为提高假脸检测的泛化性提供了一个新的测试时训练思路。具体来说,当给定一个已完成训练的检测器和任意一张测试图片,首先基于这张图片生成一张假图,由于这张假图标签已知,可以用它在测试阶段继续更新检测模型。为了更好的利用预训练模型与更快的更新速度,本工作用元学习概念来作为基本框架。
通过在多个标杆数据集上的实验,该方法不仅能提高检测器在各种未知造假方法上的准确率,也能有效提高检测器在遇到不同后处理方法时的泛化性。

Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation
通过反向梯度扰动提升对抗样本的迁移性
本文由腾讯 AI Lab 主导,与香港中文大学(深圳),深圳市大数据研究院,京东探索研究院合作完成。
对抗样本通过注入难以察觉的扰动来使得模型产生错误的预测,目前深度神经网络已被证明容易受到对抗样本的攻击。由于真实场景下,深度模型结构和网络参数对攻击者而言是不可知的,研究对抗样本的可迁移性对深度系统的安全性而言非常重要。许多现有的工作表明,对抗样本可能会过度拟合生成它们的代理模型,从而限制了其迁移到不同目标模型时的攻击性能。
为了减轻对抗样本对代理模型的过度拟合,本文提出了一种新的攻击方法,称为反向对抗扰动攻击(RAP)。具体来说,不同于现有的最小化单个对抗样本的损失,RAP目标于寻找具有一致性低对抗攻击损失的区域。RAP 的对抗攻击过程可以表述为一个min-max双层优化问题。在每一步的迭代中,RAP首先计算基于当前对抗样本点的一个最弱的攻击方向,并叠加到对抗样本上。通过将 RAP 集成到攻击的迭代过程中,我们的方法可以找到具有一致性低对抗攻击损失的区域,降低对抗样本对模型对决策边界的变化的敏感性,进而减轻其对代理模型的过拟合。
综合实验比较表明,RAP 可以显著提高对抗迁移性。此外,RAP 可以自然地与许多现有的黑盒攻击技术相结合,以进一步提高迁移攻击性能。最后,针对 Google Cloud Vision API的目标攻击实现显示我们的方法获得了 22% 的性能提升。
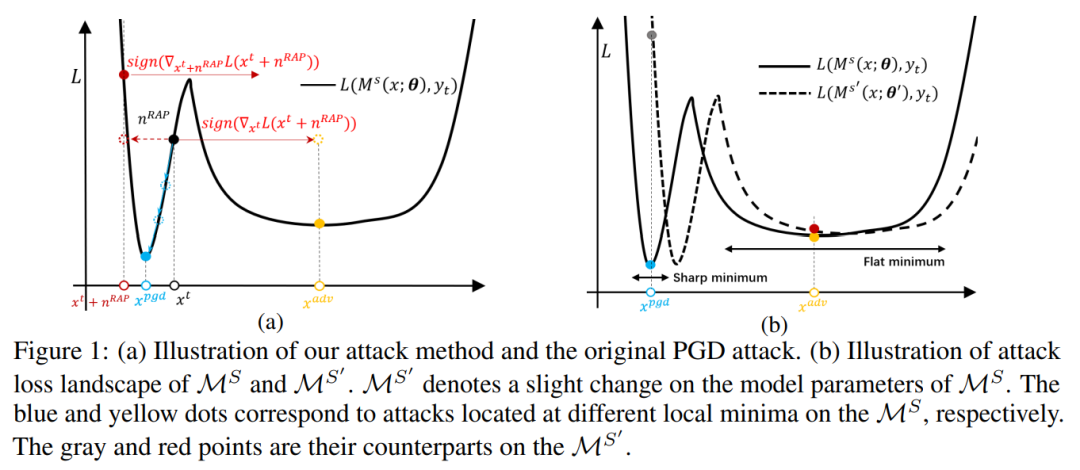
AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
AdaptFormer:一种可适配多种视觉识别任务的的适应性 ViT
本文由腾讯AI Lab主导,与香港大学,香港中文大学合作完成。
在计算机视觉中,预训练的ViT(Vision Transformers)获得了很好的效果。然而,将一个ViT适配于不同的图像和视频数据是非常有挑战性的,因为计算开销和存储负担都很重,每一个模型都需要独立并且完全的训练从而适配于不同的任务。这样一个完全训练的适配限制了其往不同数据域的迁移性。
为了解决这个问题,本文提出了一个有效的针对 ViT 的迁移方式,称为 Adaptformer。其可以将一个ViT适配到不同的图像和视频任务中。这样一个适配比先前的机制有很多优势。第一, Adaptformer 仅仅引入轻量级的模型。在额外增加2%的参数量的情况下,其在不更新原有模型参数的情况下,提升了原有ViT模型的迁移性,在视频分类任务中超越了完全训练模型的效果。第二,其可以方便的植入现有模型中并跟随不同视觉任务变化而相应调整。第三,大量的图像和视频实验表明 Adaptformer 可以很好的提升 ViT 在目标数据源的效果。举例来说,在更新 1.5% 的额外参数量时,其可以比完全训练模型,在 SSV2 获得 10% 和在 HMDB51 获得 19% 的额外提升。
One Model to Edit Them All: Free-Form Text-Driven Image Manipulation with Semantic Modulations
一个模型搞定图像编辑:利用语义调制实现基于自由文本的图像编辑
本文由腾讯 AI Lab 主导,与清华大学、香港科技大学合作完成。
利用文本个性化输入的方式,可以使得用户在图像编辑中方便地描述其意图。基于 stylegan 的视觉隐空间和 CLIP 的文本空间,研究关注于如何将这两个空间进行匹配,从而实现基于文本的属性编辑。目前来看,隐空间的匹配都是经验性设计的。从而导致每一个图像编辑模型,只能处理一种固定的文本输入。
本文提出了一种叫自由形式 CLIP 的方法,期望能够构建一个自动的隐空间对齐的方式,从而一个图像编辑模型可以处理多种多样的文本输入。该方法有一个跨模态语义调制模块,其包含了语义对齐和注入。语义对齐通过线性映射的方式自动实现了隐空间匹配,该映射是靠交叉注意力实现的。在对齐之后,我们将文本的语义信息注入视觉隐空间中。对于一类图像,我们可以用多种文本信息进行编辑。与此同时,我们观察到尽管训练时候我们用单一的文本语义。在测试中可以用多种文本语义同时进行图像编辑。
在实验中,我们在三类图像上对我们的算法进行了评估。实验结果表明我们算法有效的进行了语义准确和视觉真实的图像编辑。

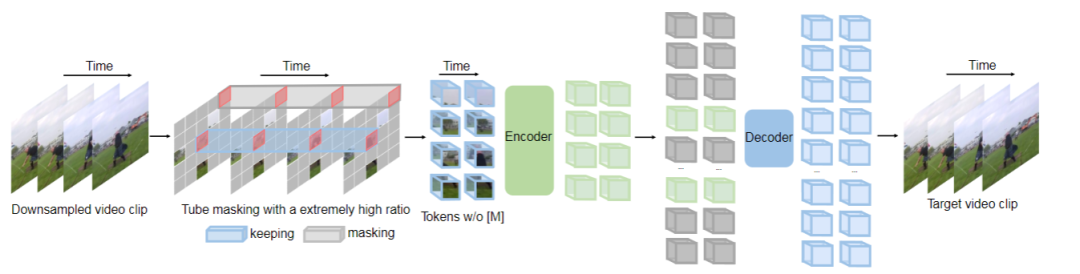
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
视频 MAE:遮盖的自动编码器在自监督视频预训练中是有效利用数据的学习器
本文由腾讯 AI Lab 主导,与南京大学合作完成。
在大数据进行视频 Transformer 预训练往往能够比在小数据集上取得更优的性能。本文指出,视频的遮盖式自动编码器在自监督视频预训练中是一个有效利用数据的学习器。作者受最近图像的遮盖式编码器启发,提出了视频管道式遮盖的的方式,该遮盖需要用一个非常大的比例。而这样一个简单的设计会使得视频恢复更具有挑战性,同时对自监督学习更具有意义,因为可以在预训练中有效提取更多的视频表征。
该项工作有三个重要的发现。第一,用一个极端比例的掩膜依然能够获得很好的效果。在时间维度冗余的视频内容支持我们这样一个极端比例的掩膜设计。第二,视频MAE在小数据集上也能够取得很好的性能。这可能是因为任务本身对数据的充分利用。第三,我们展示了数据质量比数量更重要。跨域问题在预训练和实际后续训练中比较重要。
实验证明,该算法在不利用外部额外数据前提下,利用原始的 ViT 结构可以在 K400 上取得 84.7% 的准确率,在 SSV2 上取得 75.3% 的准确率,在 HMDB51 上取得 61.1% 的准确率。
AI+生命科学
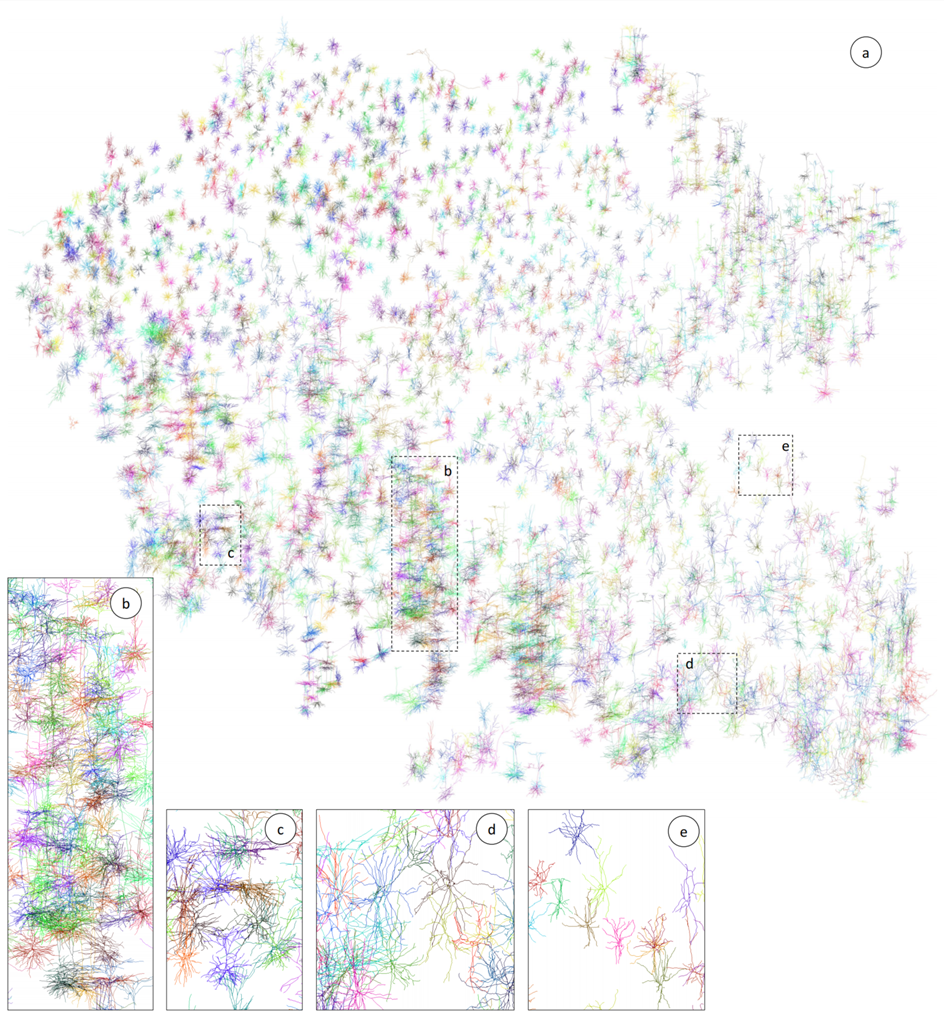
TreeMoco: Contrastive Neuron Morphology Representation Learning
TreeMoco:神经元形态表征对比学习
本文由腾讯 AI Lab 主导, 与宾夕法尼亚大学、东南大学合作完成。
神经元形态学是描绘神经元细胞类型、分析大脑发育过程和评估神经系统疾病病理变化的关键指标。传统分析主要依赖于启发式特征和人眼观察。用于定量并全面描述神经元形态的特征在很大程度上依然缺失。
为了填补这一空白,该项工作采用 Tree-LSTM 网络对神经元形态进行编码,并引入了名为 TreeMoco 的自监督学习框架在无标签信息的前提下学习特征。
作者来自三种不同公共资源的 2403 个小鼠大脑的高质量 3D 神经元重建上测试了 TreeMoco。结果表明,TreeMoco 在分类主要脑细胞类型和识别亚型方面均有效。据目前所知,TreeMoco 是第一个探索通过对比学习来学习神经元树形态表示的尝试,它具有为定量神经元形态分析提供新思路的巨大潜力。

Equivariant Graph Hierarchy-based Neural Networks
等变图层次网络
本文由腾讯 AI Lab 主导,与清华大学,中国人民大学高瓴人工智能学院合作完成。
等变图神经网络(EGNs)在描述多体物理系统的动态方面具有强大的功能。现有的等变图神经网络的消息传递机制捕捉复杂系统的空间/动力学层次,特别是限制了子结构的发现和系统全局信息的融合。
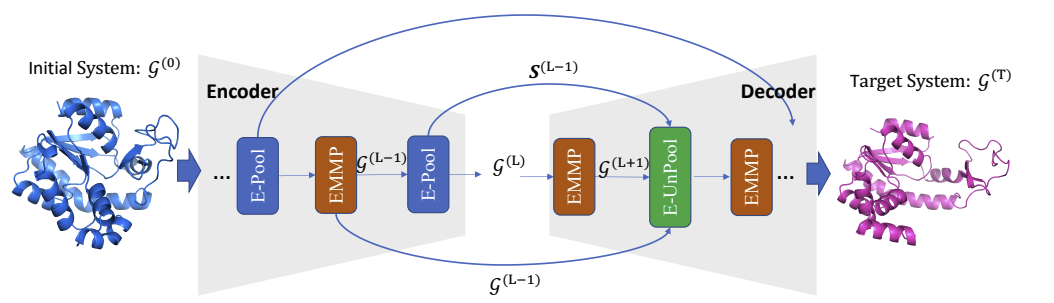
本文提出的等变图层次网络(EGHN),由三个关键部分组成:广义等值矩阵消息传递(EMMP)、E-Pool 和 E-UnPool。特别是,EMMP 能够提高传统等变量消息传递的表达能力,E-Pool 将得到节点的更抽象的层次结构。而 E-UnPool 则利用高层信息来更新低层节点的动态。
本文证明了 E-Pool 和 E-UnPool 是等变的,以满足物理对称性。大量的实验评估验证了我们的EGHN在多个应用中的有效性,包括多物体动力学模拟、运动捕捉和蛋白质动力学建模。正如它们的名字所暗示的,E-Pool 和 E-UnPool 都被保证是等价的,以满足物理对称性。大量的实验评估验证了我们的 EGHN 在多个应用中的有效性,包括多物体动力学模拟、运动捕捉和蛋白质动力学建模。
Learning Causally Invariant Representations for Out-of-Distribution Generalization on Graphs
面向图数据分布外泛化的因果表示学习
本文由腾讯 AI Lab 与香港中文大学,香港浸会大学和悉尼大学合作完成,已被会议评为 Spotlight 论文。
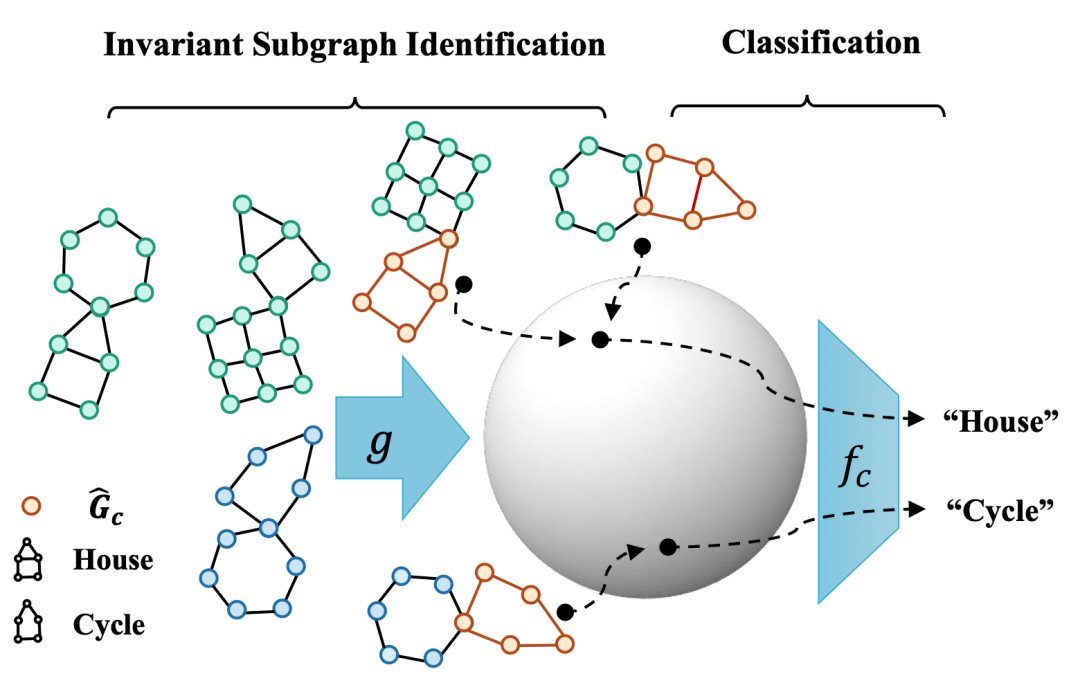
近年来,尽管在图像等欧式数据上使用因果不变性原理进行分布外泛化(Out-of-Distribution generalization)取得了一定的成功,但对图数据的研究仍然有限。与欧式数据不同,图的复杂性对采用因果不变性原理的使用提出了独特的挑战。首先,图上的分布偏移(Distribution shifts)既可以在节点属性上出现,也可以在图结构上出现,给图上不变性的识别带来了很大的困难。此外,先前大部分欧式数据上的分布外泛化算法所需要的域(Domain)或环境划分信息,在图数据上也很难获得,给面向图数据的分布外泛化算法开发带来了更大的挑战。
为了在图数据上也能做到分布外泛化,本文提出了一个新的框架,称为因果关系启发不变图学习 (CIGA),以识别和利用图数据上的因果不变性,使得模型能够在图上的各种分布变化下实现良好的泛化性能。具体来说,我们首先用因果图建模了图上可能的分布变化,并推导出,当模型只关注包含有关标签成因的最多信息的子图时,可以实现图上的分布外泛化。为此,我们提出了一个信息论目标,以提取最大程度地保留不变的同类信息的所需子图,使用这类子图进行学习和预测则可不受分布变化的影响。
本文对 16 个合成数据集和真实世界数据集的广泛实验,包括在 AI 制药相关的分子属性预测数据集 DrugOOD 上,验证了 CIGA 在图上(节点属性、图结构、图大小等)各种分布偏移下良好的分布外泛化能力。
文章转自腾讯AI Lab微信(tencent_ailab)

分享
收藏
点赞
在看