
手把手教你JS逆向搞定字体反爬并获取某招聘网站信息
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是霖hero。之前给大家分享过手把手教你使用scrapy框架来爬取北京新发地价格行情(理论篇)、手把手教你使用scrapy框架来爬取北京新发地价格行情(实战篇)、手把手教你使用XPath爬取免费代理IP,今天给大家继续带来干货,JS逆向。
网站的反爬措施有很多,例如:js反爬、ip反爬、css反爬、字体反爬、验证码反爬、滑动点击类验证反爬等等,今天我们通过爬取某招聘来实战学习字体反爬。
今日网站
小编已加密:aHR0cHM6Ly93d3cuc2hpeGlzZW5nLmNvbS8=
出于安全原因,我们把网址通过base64编码了,大家可以通过base64解码把网址获取下来。
字体反爬
字体反爬:一种常见的反爬技术,是网页与前端字体文件配合完成的反爬策略,最早使用字体反爬技术的有58同城、汽车之家等等,现在很多主流的网站或APP也使用字体反爬技术为自身的网站或APP增加一种反爬措施。
字体反爬原理:通过自定义的字体来替换页面中某些数据,当我们不使用正确的解码方式就无法获取正确的数据内容。
在HTML中通过@font-face来使用自定义字体,如下图所示:

其语法格式为:
@font-face{
font-family:"名字";
src:url('字体文件链接');
url('字体文件链接')format('文件类型')
}
字体文件一般是ttf类型、eot类型、woff类型,woff类型的文件运用比较广泛,所以大家一般碰到的都是woff类型的文件。
以woff类型文件为例,其内容是怎样的呢,又是以什么编码方式使得数据与代码一一对应的呢?
我们以某招聘网站的字体文件为例,进入百度字体编译器并打开字体文件,如下图所示:

随机打开一个字体,如下图所示:
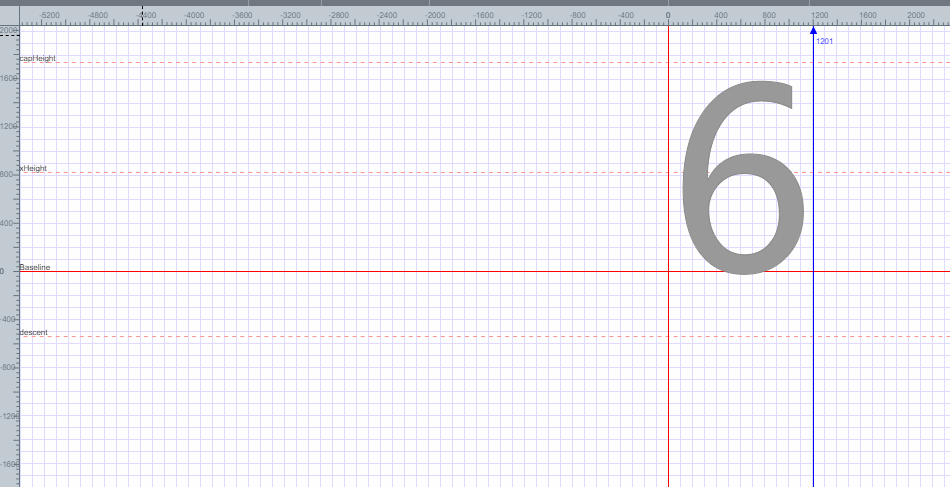
可以发现字体6放在一个平面坐标里面,根据平面坐标的每个点来得出字体6的编码,这里就不解释如何得出字体6的编码了。
如何解决字体反爬呢?
首先映射关系可以看作为字典,大致有两种常用的方法:
第一种:手动把一组编码和字符的对应关系提取出来并用字典的形式展示,代码如下所示:
replace_dict={
'0xf7ce':'1',
'0xf324':'2',
'0xf23e':'3',
.......
'0xfe43':'n',
}
for key in replace_dict:
数据=数据.replace(key,replace_dict[key])
首先定义字体与其对应的代码一一对应的字典,再通过for循环把数据一一替换。
注意:这种方法主要适用于字体映射少的数据。
第二种:首先下载网站的字体文件,再把字体文件转换为XML文件,找到里面的字体映射关系的代码,通过decode函数解码,然后将解码的代码组合成一个字典,再根据字典内容将数据一一替换,由于代码比较长,这里就不写示例代码了,待会在实战演练中会展示这种方法的代码。
好了,字体反爬就简单讲到这里,接下来我们正式爬取某招聘网站。
实战演练
自定义字体文件查找
首先进入某招聘网并打开开发者模式,如下图所示:
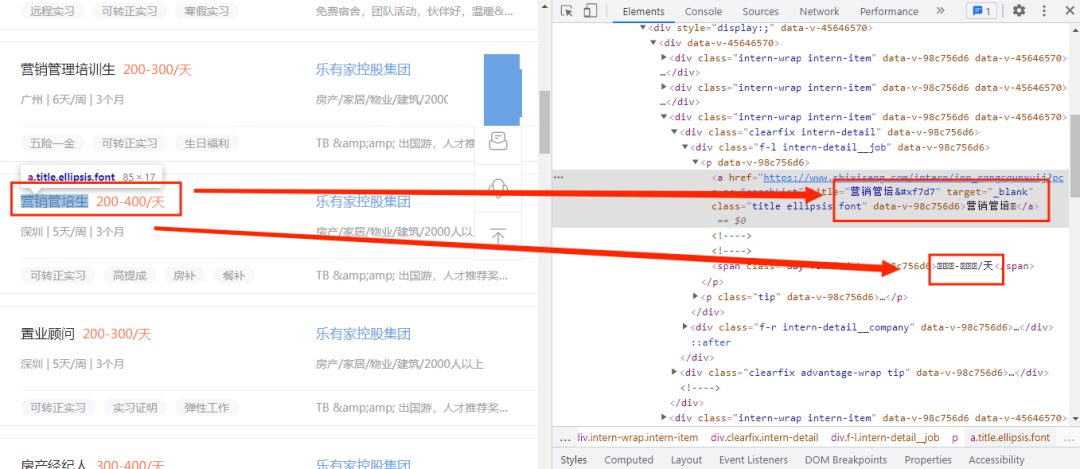
这里我们看到代码中只有生字不能正常函数,而是用来代码来替代,初步判定为使用了自定义的字体文件,这时就要找到字体文件了,那么字体文件在哪里找呢,首先打开开发者模式,并点击Network选项,如下图所示:
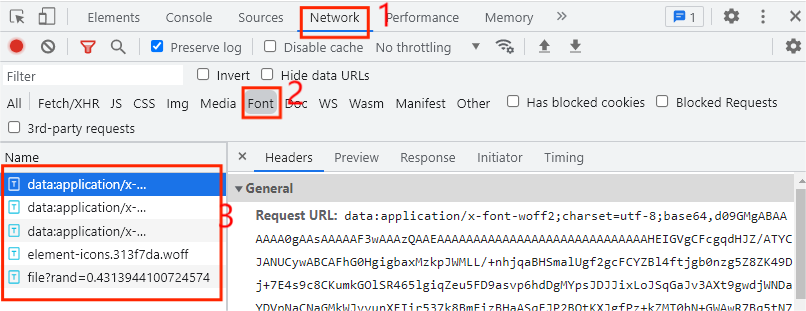
一般情况下,字体文件放在Font选卡中,我们发现这里一共有5个条目,那么哪个是自定义字体文件的条目呢,当我们每次点击下一页的时候,自定义字体文件就会执行一次,这时我们只需要点击网页中的下一页即可,如下图所示:
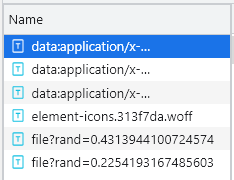
可以看到多了一个以file开头的条目,这时可以初步判定该文件为自定义字体文件,现在我们把它下载下来,下载方式很简单,只需要把file开头的条目的URL复制并在网页上打开即可,下载下来后在百度字体编译器打开,如下图所示:
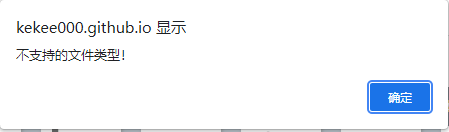
这时发现打开不了,是不是找错了字体文件,网站提示说不支持这种文件类型,那么我们把下载的文件后缀改为.woff在打开试试,如下图所示:

这时就成功打开了。
字体映射关系
找到自定义字体文件了,那么我们该怎么利用呢?这时我们先自定义方法get_fontfile()来处理自定义字体文件,然后在通过两步来把字体文件中的映射关系通过字典的方式展示出来。
字体文件下载与转换; 字体映射关系解码。
字体文件下载与转换
首先自定义字体文件更新频率是很高的,这时我们可以实时获取网页的自定义字体文件来防止利用了之前的自定义字体文件从而导致获取数据不准确。首先观察自定义字体文件的url链接:
https://www.xxxxxx.com/interns/iconfonts/file?rand=0.2254193167485603
https://www.xxxxxx.com/interns/iconfonts/file?rand=0.4313944100724574
https://www.xxxxxx.com/interns/iconfonts/file?rand=0.3615862774301839
可以发现自定义字体文件的URL只有rand这个参数发生变化,而且是随机的十六位小于1的浮点数,那么我们只需要构造rand参数即可,主要代码如下所示:
def get_fontfile():
rand=round(random.uniform(0,1),17)
url=f'https://www.xxxxxx.com/interns/iconfonts/file?rand={rand}'
response=requests.get(url,headers=headers).content
with open('file.woff','wb')as f:
f.write(response)
font = TTFont('file.woff')
font.saveXML('file.xml')
首先通过random.uniform()方法来控制随机数的大小,再通过round()方法控制随机数的位数,这样就可以得到rand的值,再通过.content把URL响应内容转换为二进制并写入file.woff文件中,在通过TTFont()方法获取文件内容,通过saveXML方法把内容保存为xml文件。xml文件内容如下图所示:
字体解码及展现
该字体.xml文件一共有4589行那么多,哪个部分才是字体映射关系的代码部分呢?
首先我们看回在百度字体编码器的内容,如下图所示:

汉字人对应的代码为f0e2,那么我们就在字体.xml文件中查询人的代码,如下图所示:
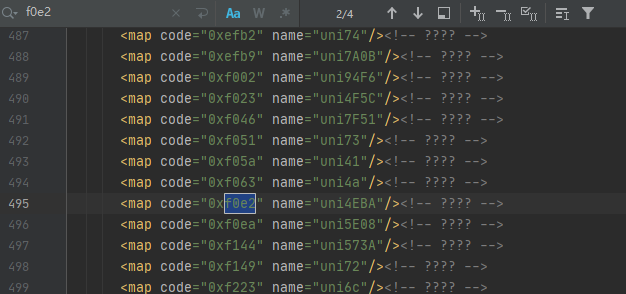
可以发现一共有4个结果,但仔细观察每个结果都相同,这时我们可以根据它们代码规律来获取映射关系,再通过解码来获取对应的数据值,最后以字典的形式展示,主要代码如下所示:
with open('file.xml') as f:
xml = f.read()
keys = re.findall('<map code="(0x.*?)" name="uni.*?"/>', xml)
values = re.findall('<map code="0x.*?" name="uni(.*?)"/>', xml)
for i in range(len(values)):
if len(values[i]) < 4:
values[i] = ('\\u00' + values[i]).encode('utf-8').decode('unicode_escape')
else:
values[i] = ('\\u' + values[i]).encode('utf-8').decode('unicode_escape')
word_dict = dict(zip(keys, values))
首先读取file.xml文件内容,找出把代码中的code、name的值并分别设置为keys键,values值,再通过for循环把values的值解码为我们想要的数据,最后通过zip()方法合并为一个元组并通过dict()方法转换为字典数据,运行结果如图所示:

获取招聘数据
在上一步中,我们成功把字体映射关系转换为字典数据了,接下来开始发出网络请求来获取数据,主要代码如下所示:
def get_data(dict,url):
response=requests.get(url,headers=headers).text.replace('&#','0')
for key in dict:
response=response.replace(key,dict[key])
XPATH=parsel.Selector(response)
datas=XPATH.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div[1]/div[1]/div')
for i in datas:
data={
'workname':i.xpath('./div[1]/div[1]/p[1]/a/text()').extract_first(),
'link':i.xpath('./div[1]/div[1]/p[1]/a/@href').extract_first(),
'salary':i.xpath('./div[1]/div[1]/p[1]/span/text()').extract_first(),
'place':i.xpath('./div[1]/div[1]/p[2]/span[1]/text()').extract_first(),
'work_time':i.xpath('./div[1]/div[1]/p[2]/span[3]/text()').extract_first()+i.xpath('./div[1]/div[1]/p[2]/span[5]/text()').extract_first(),
'company_name':i.xpath('./div[1]/div[2]/p[1]/a/text()').extract_first(),
'Field_scale':i.xpath('./div[1]/div[2]/p[2]/span[1]/text()').extract_first()+i.xpath('./div[1]/div[2]/p[2]/span[3]/text()').extract_first(),
'advantage': ','.join(i.xpath('./div[2]/div[1]/span/text()').extract()),
'welfare':','.join(i.xpath('./div[2]/div[2]/span/text()').extract())
}
saving_data(list(data.values()))
首先自定义方法get_data()并接收字体映射关系的字典数据,再通过for循环将字典内容与数据一一替换,最后通过xpath()来提取我们想要的数据,最后把数据传入我们自定义方法saving_data()中。
保存数据
数据已经获取下来了,接下来将保存数据,主要代码如下所示:
def saving_data(data):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='recruit')
cursor = db.cursor()
sql = 'insert into recruit_data(work_name, link, salary, place, work_time,company_name,Field_scale,advantage,welfare) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,data)
db.commit()
except:
db.rollback()
db.close()
启动程序
好了,程序已经写得差不多了,接下来将编写代码运行程序,主要代码如下所示:
if __name__ == '__main__':
create_db()
get_fontfile()
for i in range(1,3):
url=f'https://www.xxxxxx.com/interns?page={i}&type=intern&salary=-0&city=%E5%85%A8%E5%9B%BD'
get_data(get_dict(),url)
结果展示
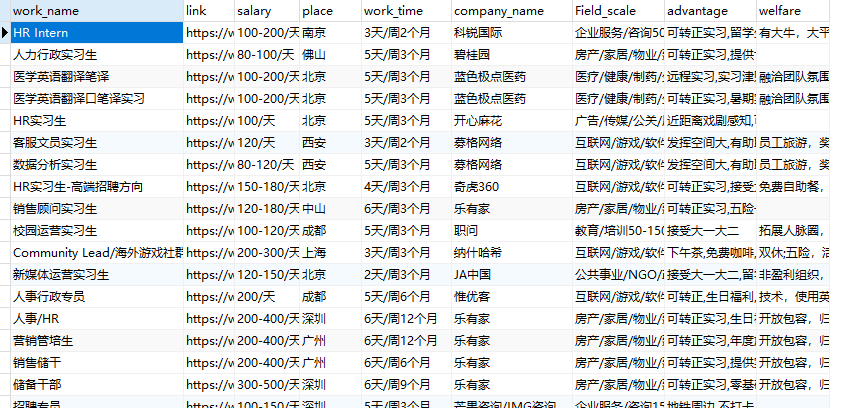
好了,学习字体反爬并爬取某招聘就讲到这里了!!!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~