
【Python爬虫】如何搞定字体反爬
首先声明,本文章仅为学习技术使用,如作他用所负责任一概与作者无关。
前几天有个私活,要爬取某车之家的口碑评论,没有接单,但是对于其中涉及到的字体反爬有了浓厚的研究兴趣,因此,打算锻炼一下自己的反爬能力,盘它!!!
什么是字体反爬
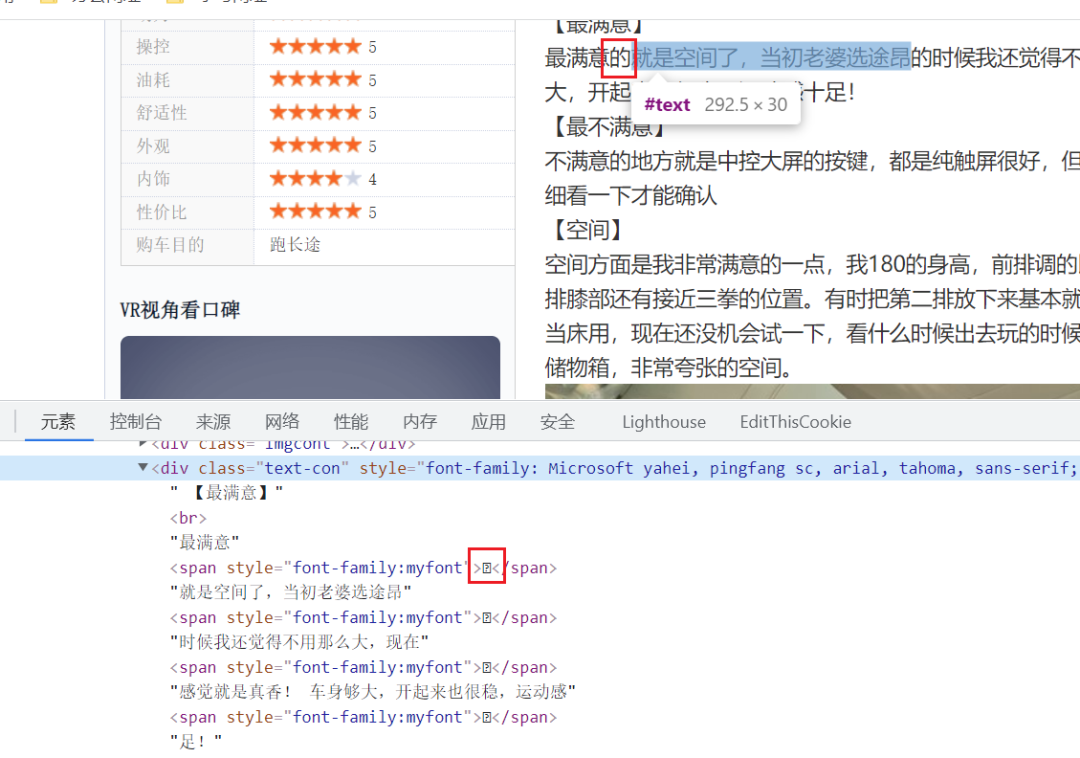
如图所示,在网页中能正常看到的文字,但是到代码中文没了,变成了一个span标签,如果爬虫不能解决这些文字问题,那么获取下来的内容就没有什么意义了。关于字体反爬下面这个文章说的很清楚了:
反爬终极方案总结—字体反爬 - 笑看山河的文章 - 知乎
解决思路
在百度上搜了一下“字体反爬”有很多相关的文章,但基本无法解决某车之家的随机变形字体,因此,需要另寻思路。在前面的知乎文章中,其实已经给出了一个方向,那就是OCR。。。。。。
因此,思路就是:1爬取页面->2下载页面的自定义字体->3将自定义字体转成图片->4使用OCR识别出文字->5替换页面文档中的特殊字符
准备工作-安装第三方包
尝试了很多库,最后使用cnocr这个库的识别率最好,但在安装这个库时就遇到了问题,因此,这里先将解决安装问题的过程记录一下:
首先创建了一个干净的虚拟环境,并激活
安装cnocr 
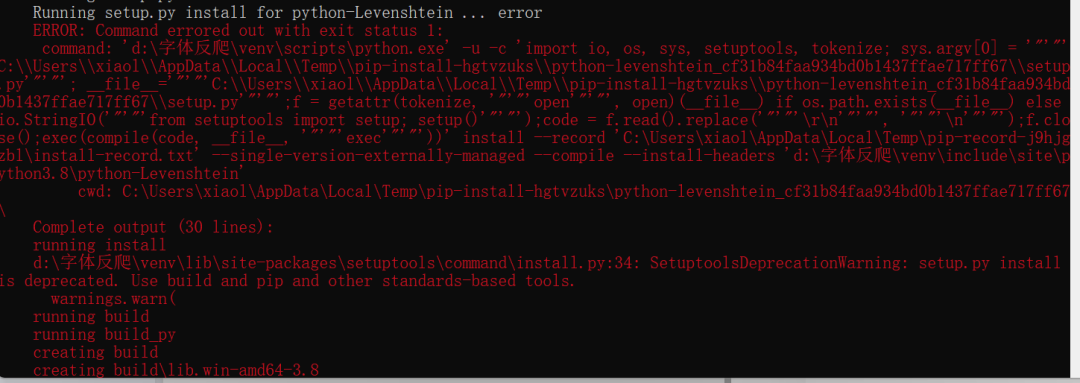
在安装python-Levenshtein这个包时出错了,一大堆的红色英文,让英语渣渣的我十分头疼。不过,经历过无数次锤炼的我,已经能够熟练的解决问题了:把关键字复制下来,求助于万能的百度^_^,果不其然,有很多解决方案。具体就自行百度了,这里直接上我的解决方法“直接下载whl文件到本地安装”。点这里进入下载whl文件的地址搜索python-Levenshtein下载
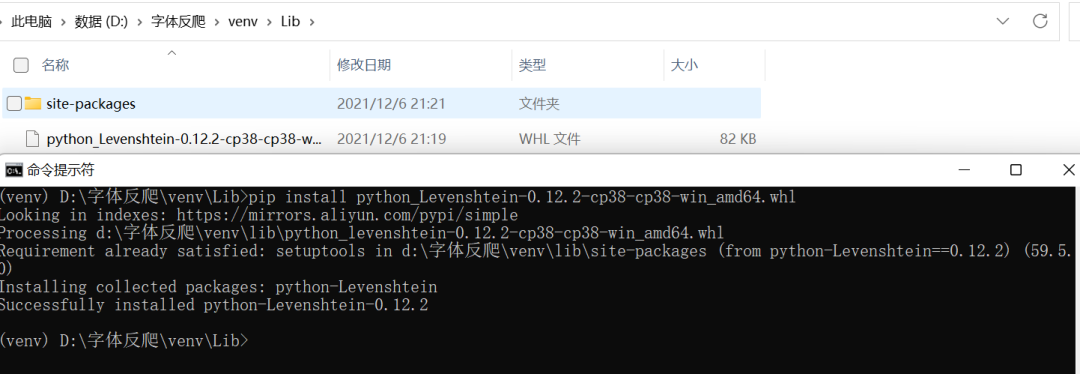 注意图片中的安装命令与文件名称以及存放目录间的关系,这个包安装成功后,再次运行pip install cnocr就不再报错了。
注意图片中的安装命令与文件名称以及存放目录间的关系,这个包安装成功后,再次运行pip install cnocr就不再报错了。
安装fontTools、reportlab用于识别字体并画图
这个步骤正常的pip install即可,没有碰到问题
分步实现
因为本文是专注解决字体反爬问题,因此,没考虑爬虫的其他步骤,直接随机选择了5个网页的代码和字体文件进行试验:
读取字体文件并逐个文字转成图片:
from fontTools.ttLib import TTFont
from fontTools.pens.basePen import BasePen
from reportlab.graphics.shapes import Path
from reportlab.lib import colors
from reportlab.graphics import renderPM
from reportlab.graphics.shapes import Group, Drawing
import os
class ReportLabPen(BasePen):
"""
画出字体的类
"""
def __init__(self, glyphset, path=None):
BasePen.__init__(self, glyphset)
if path is None:
path = Path()
self.path = path
def _moveTo(self, p):
(x, y) = p
self.path.moveTo(x, y)
def _lineTo(self, p):
(x, y) = p
self.path.lineTo(x, y)
def _curveToOne(self, p1, p2, p3):
(x1, y1) = p1
(x2, y2) = p2
(x3, y3) = p3
self.path.curveTo(x1, y1, x2, y2, x3, y3)
def _closePath(self):
self.path.closePath()
class TtfToImage:
"""
将ttf文件中的文字转成image图片的类
"""
def __init__(self, ttf_file, fmt='png'):
"""
初始化对象
:param ttf_file: ttf文件的绝对路径
:param fmt: 输出的图片格式,默认png
"""
self.ttf_file = ttf_file
path, file_name = os.path.split(self.ttf_file)
# 将ttf文件的文件名作为图片输出的文件夹名称,并放置在与ttf文件相同的目录下
self.out_path = os.path.join(path, file_name.split('.')[0])
self.fmt = fmt
def check_out_path(self):
"""
检查图片文件输出的路径,如文件夹未创建,则直接创建
"""
if os.path.isdir(self.out_path):
pass
else:
os.mkdir(self.out_path)
def draw_to_image(self):
"""
将字体画图输出
"""
self.check_out_path()
font = TTFont(self.ttf_file)
gs = font.getGlyphSet()
glyphnames = font.getGlyphNames()
n = 0
for i in glyphnames:
if i[0] == '.':
continue
g = gs[i]
pen = ReportLabPen(gs, Path(fillColor=colors.black, strokeWidth=5))
g.draw(pen)
w, h = g.width, g.width
g = Group(pen.path)
g.translate(0, 400)
d = Drawing(w, h)
d.add(g)
image_file = os.path.join(self.out_path, f'{i.replace("uni", "")+"."+self.fmt}')
renderPM.drawToFile(d, image_file, self.fmt)
n += 1
print(f'第{n}个字体制作完毕,图片为{image_file}!')
if __name__ == '__main__':
ttf = TtfToImage('d:/字体反爬/测试用例/途昂1/wKgHGlsV95yAIlpKAADWCPynXQc60..ttf')
ttf.draw_to_image()
这个步骤就是将字体文件ttf中的文字画出一张张图片,大部分代码是从百度上搜索的,感谢无数的代码贡献者,让我不用重复造轮子!

将文字图片拼成矩阵图片
在使用单字进行ocr识别时,正确率反而不如缩小后的矩阵文字,因此,将单字拼成矩阵 进行识别反而能够提高正确率。
import json
import PIL.Image as Image
import os
import numpy as np
class ImagesCompose:
def __init__(self, font_files_path, image_size=50, each_row_num=10):
self.font_files_path = font_files_path
self.image_size = image_size # 每张小图片的大小
self.images = [i for i in os.listdir(self.font_files_path)]
self.column = each_row_num # 图片合并成一张图后每行的字数,默认10个字
image_count = len(self.images)
self.row = image_count // self.column # 计算图片合并成一张图后,一共有几行
if image_count % self.column != 0: # 如果余数不为0,则增加一行
self.row += 1
for i in range(self.row * self.column - image_count): # 并且用None字符补足数量以便后续转换矩阵
self.images.append('None')
# 将self.images转成row行column列的矩阵
self.images = np.array(self.images).reshape((self.row, self.column))
def image_compose(self):
"""
组合图片
"""
to_image = Image.new('RGB', (self.column * self.image_size, self.row * self.image_size)) # 创建一个新图
# 循环遍历,把每张图片按顺序粘贴到对应位置上
for x, y in np.argwhere(self.images):
if self.images[x, y] != 'None': # 当文件名不是None时,拼接图片
from_image = Image.open(os.path.join(self.font_files_path, self.images[x, y])).resize(
(self.image_size, self.image_size), Image.ANTIALIAS)
to_image.paste(from_image, (y * self.image_size, x * self.image_size))
# 把矩阵中的文件名扩展名去除
self.images[x, y] = os.path.splitext(self.images[x, y])[0]
to_image.save(f'{self.font_files_path}.png') # 保存新图
# 将字体的编码矩阵保存到TXT文件中,以便后续制作字典
with open(f'{self.font_files_path}_keys.txt', 'w', encoding='utf-8') as fin:
fin.write(json.dumps(self.images.tolist(), ensure_ascii=False))
if __name__ == '__main__':
obj = ImagesCompose(r'D:\字体反爬\测试用例\途昂1\wKgHGlsV95yAIlpKAADWCPynXQc60')
obj.image_compose()

使用ocr库解析图获取文字,并生成文字编码与汉字对应的字典
from cnocr import CnOcr
import json
import numpy as np
class GetFonts:
def __init__(self, font_file, key_file):
self.ocr = CnOcr()
self.font_file = font_file
with open(key_file, 'r', encoding='utf-8') as fout:
self.key_array = np.array(json.loads(fout.read()))
self.font_dict = {}
def get_font_dict(self):
res = self.ocr.ocr(self.font_file)
res = [row[0] for row in res]
res = np.array(res)
for x, y in np.argwhere(self.key_array):
if self.key_array[x, y] != 'None':
self.font_dict[self.key_array[x, y]] = res[x, y]
with open(f'{self.font_file.replace(".png", ".txt")}', 'w', encoding='utf-8') as fin:
fin.write(json.dumps(self.font_dict, ensure_ascii=False))
if __name__ == '__main__':
fonts = GetFonts(
r'D:\字体反爬\测试用例\途昂1\wKgHGlsV95yAIlpKAADWCPynXQc60.png',
r'D:\字体反爬\测试用例\途昂1\wKgHGlsV95yAIlpKAADWCPynXQc60_keys.txt',
)
fonts.get_font_dict()
这一步是将前序步骤中处理完成的文字矩阵图片与文字编码矩阵进行匹配,将ocr识别出的文字与文字编码构造成字典。如下图:
 4. 替换HTML中的自定义字符
4. 替换HTML中的自定义字符
最后替换HTML中的span自定义字符标签即可
import json
class ParseHtml:
def __init__(self, html, font_dict_file):
self.html_path = html
with open(html, 'r', encoding='utf-8') as fin:
self.html = fin.read()
with open(font_dict_file, 'r', encoding='utf-8') as fin:
self.font_dict = json.loads(fin.read())
def replace_html(self):
for k, v in self.font_dict.items():
p = f"&#x{k.lower()};"
self.html = self.html.replace(p, v)
with open(self.html_path.replace('.txt', '_new.txt'), 'w', encoding='utf-8') as fout:
fout.write(self.html)
if __name__ == '__main__':
obj = ParseHtml(
'd:/字体反爬/测试用例/途昂1/途昂1.txt',
'd:/字体反爬/测试用例/途昂1/wKgHGlsV95yAIlpKAADWCPynXQc60.txt'
)
obj.replace_html()
其他测试案例
字体反爬的关键点就是构造编码与文字的字典,因此,将其他测试案例的原图与结果进行一下匹配,看一下正确率,哇!完美!!!
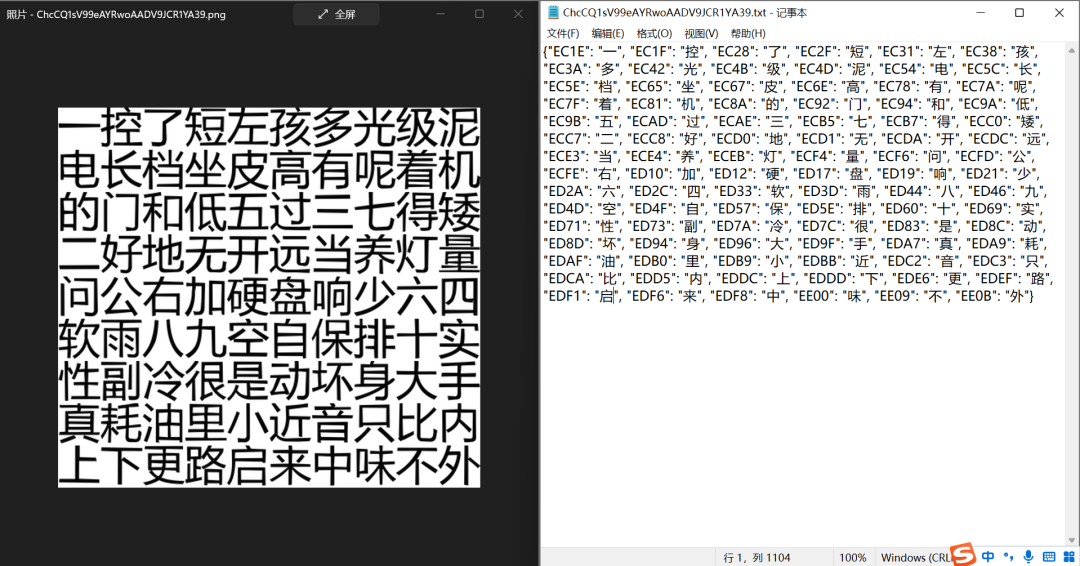
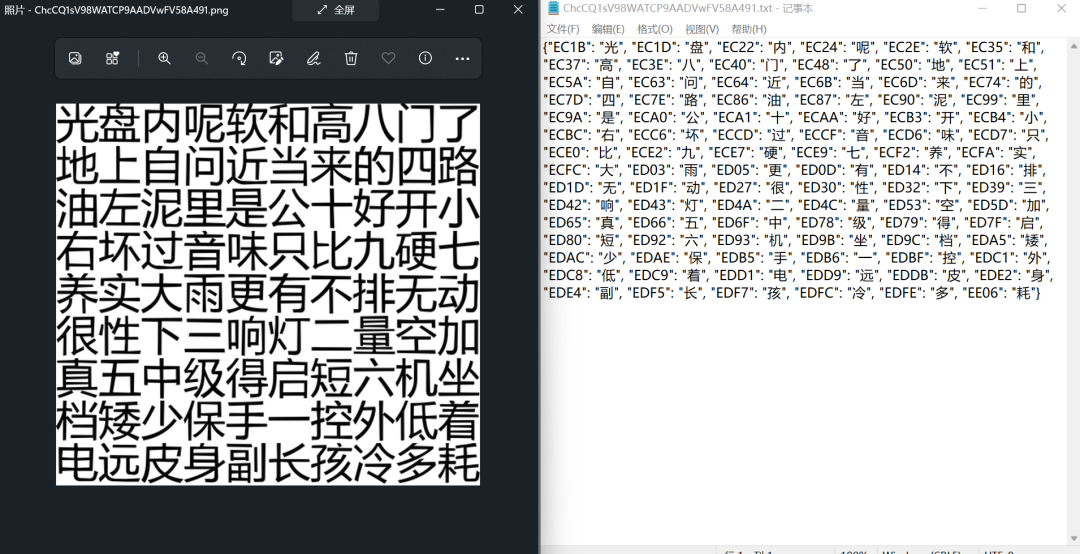
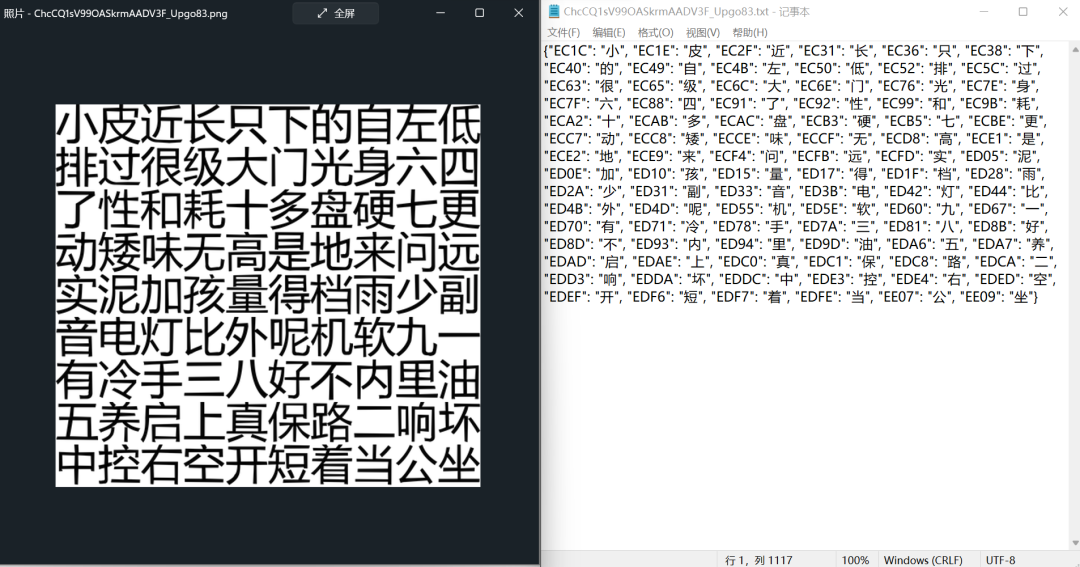
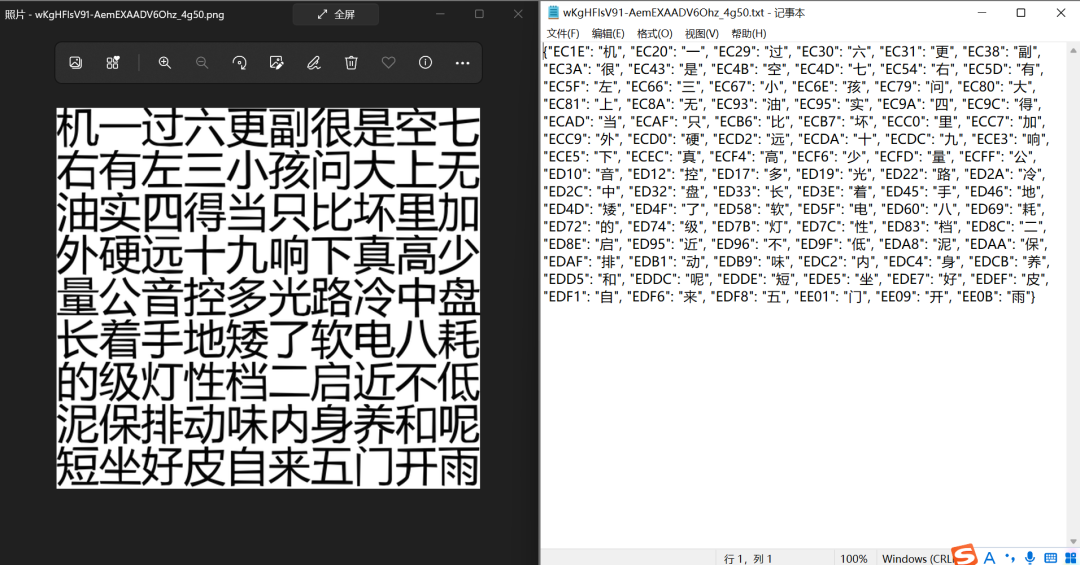
最终总结
从测试的5个用例来看,字体反爬的难关算是攻克了,目前效果堪称完美,这个解决方案总体用到了以下几个库:
fontTools、reportlab将字体生成图片; PIL.Image库进行图片组合; cnocr进行ocr文字识别(这是核心,正确率与否主要取决于它); 其他还用到os、json、numpy等进行操作。爬虫与反爬的博弈永无止境,也许没过多久这个方案就失效了,但不变的是我们始终都在进步。
最后,推荐蚂蚁老师的《零基础Python到爬虫到数据分析》课程
购买课程可以联系老师副业接单,单子非常多!
