
反爬篇 | 手把手教你处理 JS 逆向之字体反爬

大家好,我是安果!
上一篇文章我们讲解了 JS 逆向中一种常见的反爬方案「 图片伪装 」
本篇文章将聊聊另一种更加常见的反爬方案「 字体反爬 」
它的实现原理为通过自定义的字体替换网页元素中的部分内容来实现的反爬策略
常见的字体格式包含:ttf、eot、woff,我们一般在网页中通过关键字「 @font-face 」定义字体样式,然后再设置到元素控件样式中去
//定义字体样式
@font-face{
font-family:"字体文件的名字,比如:gzfont";
src:url('字体文件的链接');
}
// 给某个元素控件设置字体样式
.gzfont {
font-family: gzfont;
}
目前有很多主流网站引入了字体反爬,比如:某 8 同城、某车之家等
今天研究的目标对象是:
aHR0cHM6Ly93d3cuZ3VhemkuY29tL2J1eQ==
1、分析一下
打开目标页面及浏览器的开发者工具栏,我们发现汽车价格、首付金额、公里数中的部分内容在源码中显示为乱码,但在界面中展示正常
元素的字体样式名称为「 gzfont 」
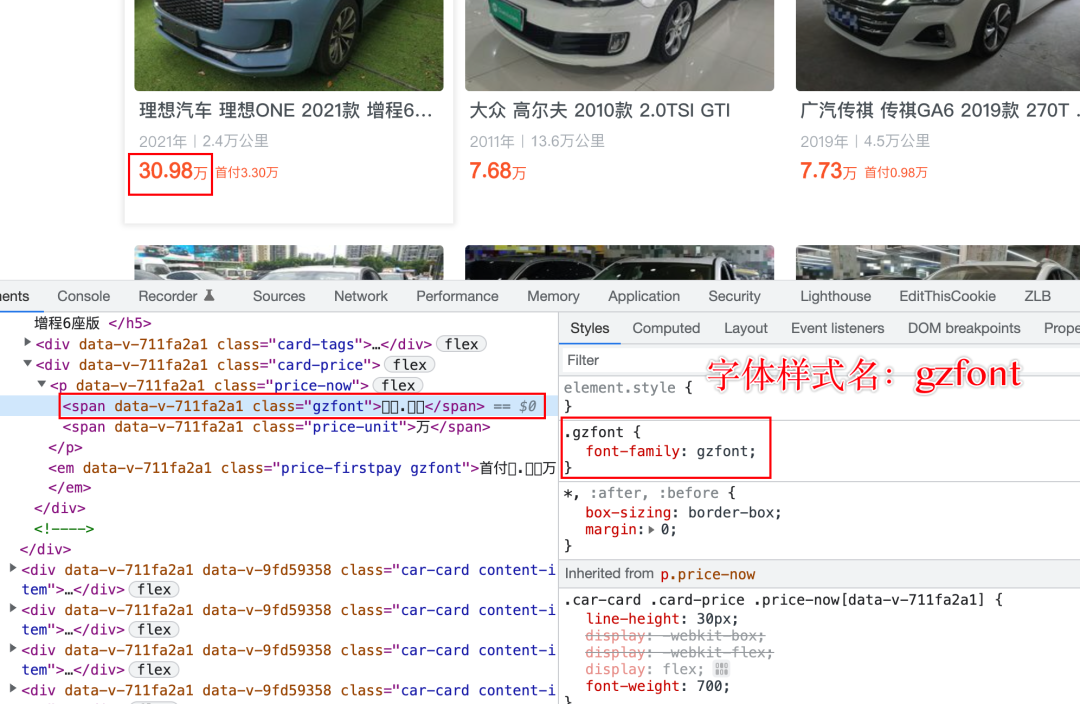
我们在网页源码中通过关键字「 gzfont 」尝试查找字体的实际 URL 地址
但是源码中并未出现字体定义的逻辑,因此我们可以推测字体实际加载地址是通过 Ajax 加载的

我们在「 Sources 」面板下,通过上面的关键字全局搜索该关键字出现的所有代码块进行逐一分析
通过新增一个断点,找到 gzfont 字段生成的逻辑及字体 URL 地址
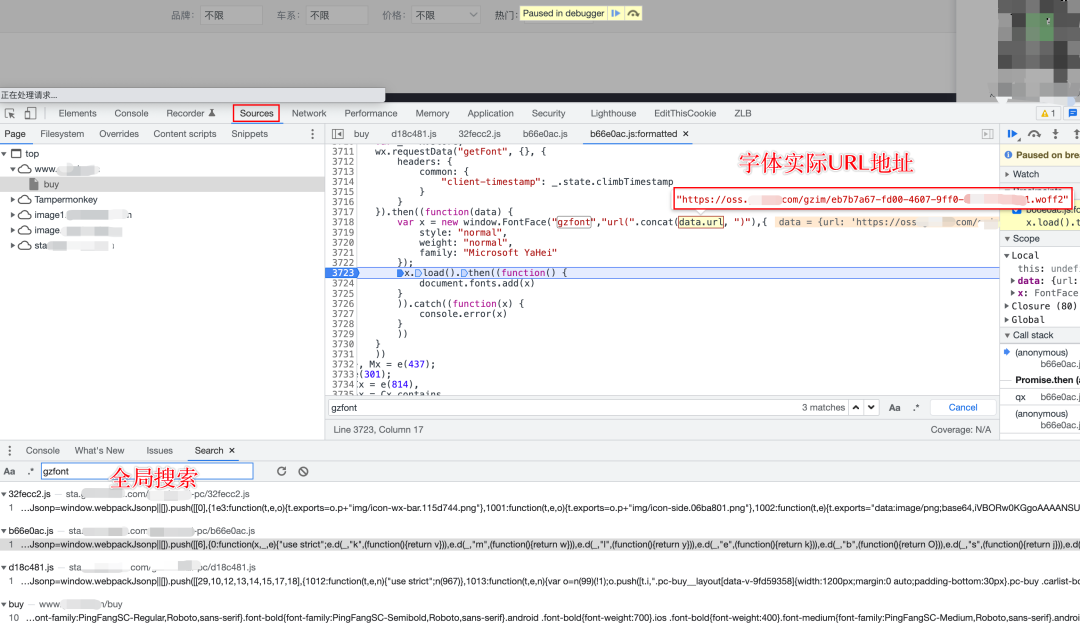
在浏览器的新窗口中,通过字体 URL 下载字体文件,然后在 PC 上使用软件 FontCreator 打开查看
下载地址:
https://www.pcsoft.com.cn/soft/21156.html
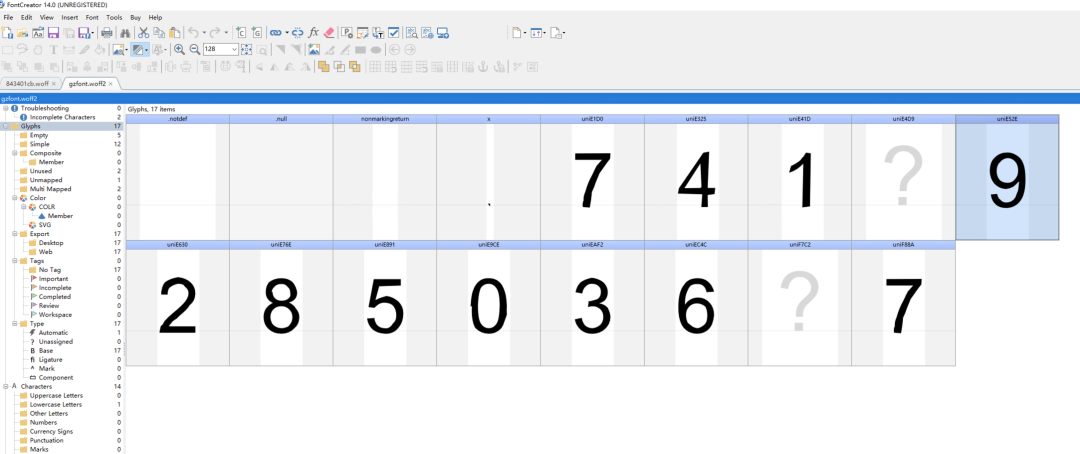
我们发现字体映射关系很简单,数目也很少,并且映射关系是固定的
PS:每次重新加载页面,字体 URL 地址、映射关系都是固定的
所以,我们可以通过一个字典定义它们的映射关系
# 字体映射关系
# PS:由于字体数目很少,所以可以直接写死字体的映射关系
font_relation_map = {
'uniE9CE': 0,
'uniE41D': 1,
'uniE630': 2,
'uniEAF2': 3,
'uniE325': 4,
'uniE891': 5,
'uniEC4C': 6,
'uniE1D0': 7,
'uniE76E': 8,
'uniE52E': 9
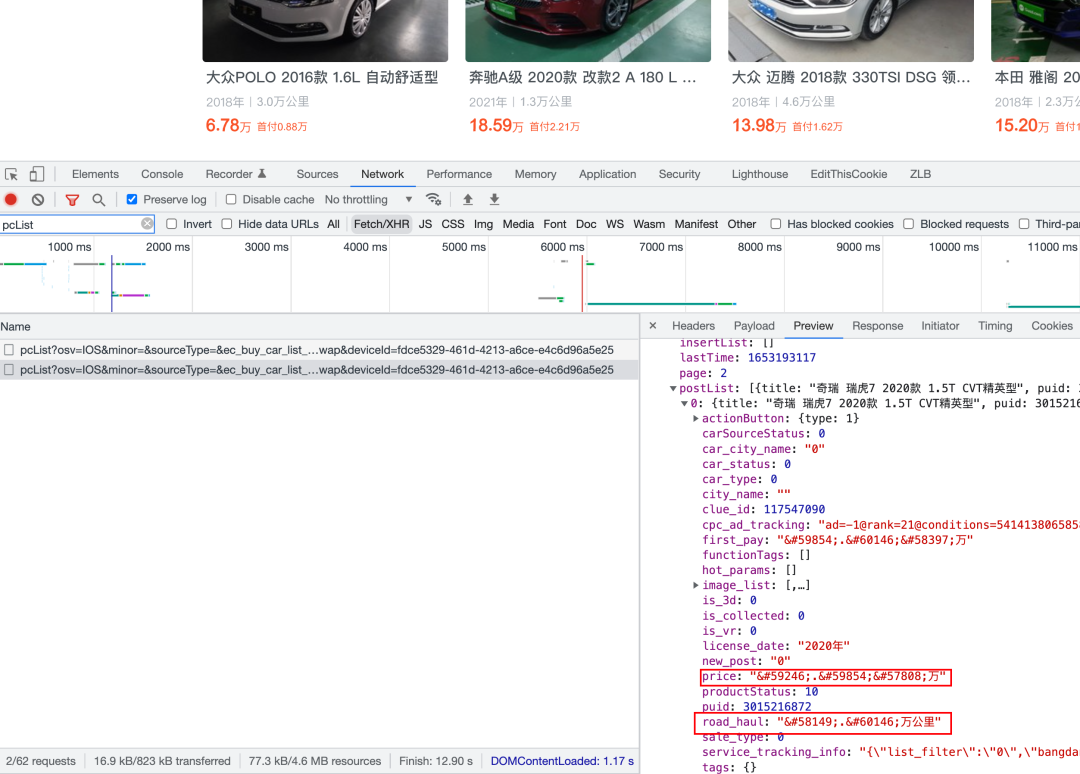
}最后,我们分析发现页面数据都是通过下面的网络请求获取的
我们只需要将里面的乱码数据根据字体映射关系替换为正常的数据即可
2、具体实现
下面,我们聊聊爬取网页内容的步骤
首先,我们需要安装字体解析的依赖库 fonttools
# 安装依赖
pip3 install fonttools
然后,解析字体文件,根据上面响应数据中的数据格式,重新组成一个新的字典数据
def get_font_map():
"""
获取字体映射关系
:return:
"""
font = TTFont(r'gzfont.woff2')
# 字体文件转为xml文件
# font.saveXML(r"font.xml")
font_map = font.getBestCmap()
font.close()
# print(font_map)
new_font_map = {}
# 遍历字典,重新组成一个新的映射字典
for index, key in enumerate(font_map):
value = font_map[key]
# 捕获异常
try:
temp = font_relation_map[value]
except:
temp = ''
if temp != '':
# 根据响应结果中字体反爬数据格式,将键值前面添加字符串&#,用于匹配
new_font_map['&#' + str(key) + ";"] = temp
return new_font_map接着,模拟上面的网络请求获取响应数据;遍历上面的字典键值对,判断键 key 是否包含在响应结果中
如果包含,就将响应结果中的键 key 全部替换该键对应的值 value
import json
import time
import requests
def get_car_list(pagenum: int, new_font_map: dict):
"""
获取车列表数据
:param new_font_map:
:return:
"""
url = f"https://mapi.**.com/car-source/carList/pcList?osv=IOS&minor=&sourceType=&ec_buy_car_list_ab=**"
payload = {}
headers = {
'authority': 'mapi.**.com',
'accept': 'application/json, text/plain, */*',
'origin': 'https://www.**.com',
'platform': '5',
'referer': 'https://www.**.com/',
'token': '',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'
}
resp_str = requests.request("GET", url, headers=headers, data=payload).text
# 全局替换
for key, value in new_font_map.items():
if key in resp_str:
resp_str = resp_str.replace(key, str(value))最后就可以进行数据提取了
...
# 数据解析
resp = json.loads(resp_str)
postList = resp.get("data").get("postList")
for item in postList:
title = item.get("title")
road_haul = item.get("road_haul") # 公里
license_date = item.get("license_date") # 购买时间
price = item.get("price") # 价格
first_pay = item.get("first_pay") # 首付
print(f'车型:{title},公里数:{road_haul},购买时间:{license_date},价格:{price},首付:{first_pay}')
...
运行爬虫,我们发现爬取到的数据不存在乱码,都正常显示了

3、总结一下
在日常工作中,应对字体反爬的常规步骤如下:
检查网页控件的字体名称
通过网页源码、Network 面板(Font)、Source 面板(关键字搜索)及调试的方式获取字体地址
在 PC 端通过软件查看字体的映射关系
通过页面刷新、下载查看字体,判断字体文件是否动态生成
使用依赖库 fonttools 解析字体,根据元素内容生成新的键值对
对响应结果根据键值对进行内容替换
我已经将文中所有源码上传到后台,回复关键字「 字体反爬 」即可以获取完整源码
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
END