
反爬篇 | 手把手教你处理 JS 逆向之图片伪装

大家好,我是安果!
最近打算更新反爬系列相关的内容,第一篇就从最简单的「 图片伪装 」开始吧
图片伪装是在网页元素中,将文字、图片混合在一起进行展示,以此限制爬虫程序直接获取网页内容
目标对象:
aHR0cHM6Ly93d3cuZ3hyYy5jb20vam9iRGV0YWlsL2Q2NmExNjQxNzc2MjRlNzA4MzU5NWIzMjI1ZWJjMTBi
1 - 分析
打开页面,分析页面发现网页源码中的电话号码默认是隐藏保护的
并且要查看电话号码,必须先通过账号进行登录操作

完成登录后,点击页面上的查看按钮会调用一个接口,随后电话号码就完全展示出来了
https://**/getentcontacts/b2147f6a-6ec7-403e-a836-62978992841b
PS:该 URL 地址中 b2147f6a-6ec7-403e-a836-62978992841b 在网页源码中可以获取,与企业一一对应
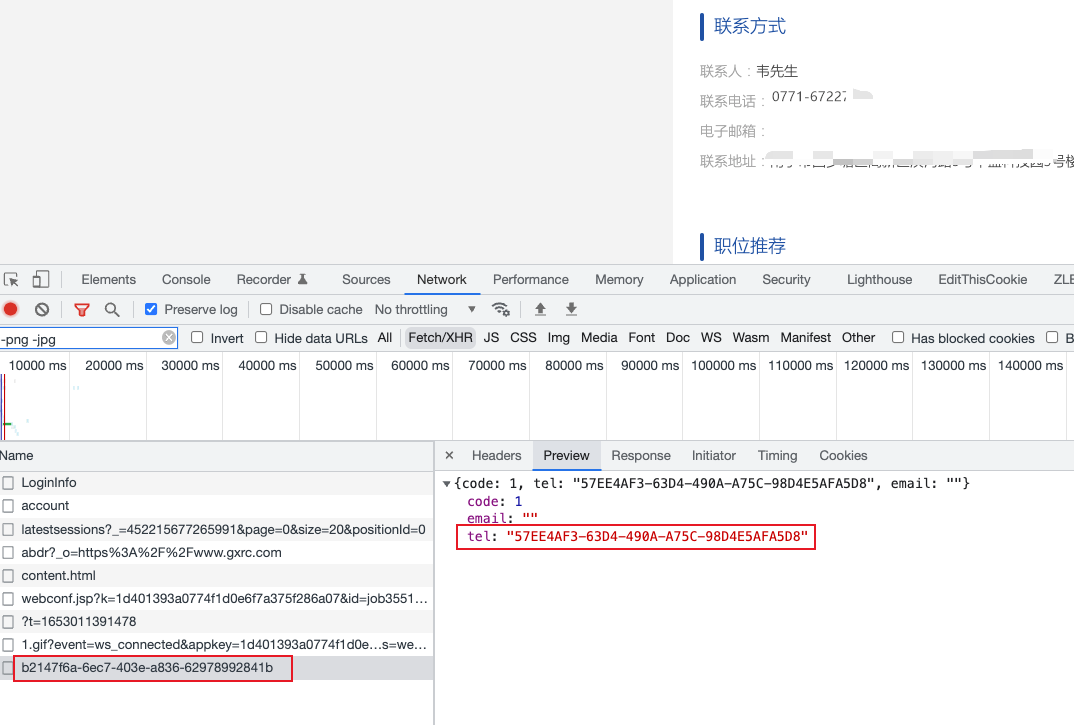
通过下图,我们发现上面接口响应值中的「 tel 」字段可以拼接成一张图片,该图片中的内容与电话号码一致
因此,我们只需要下载这张图片,利用 OCR 进行识别即可以
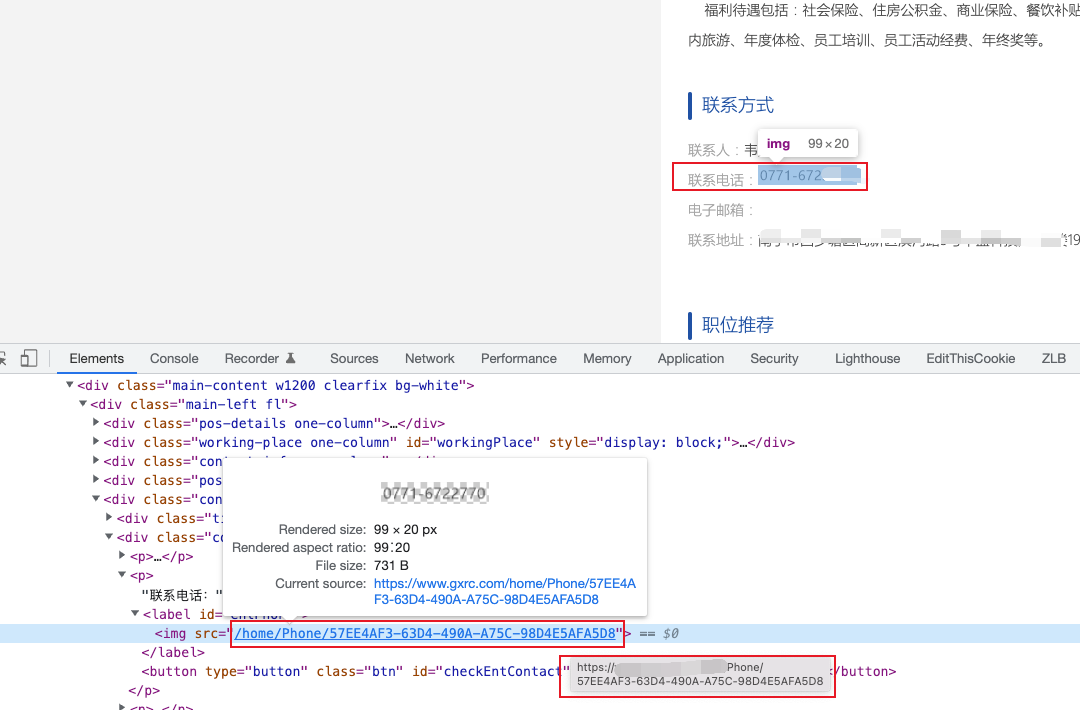
2 - 实现
由于该网站上的文字图片背景很干净,因此不需要额外的训练来提升文字识别率
首先,我们调用接口获取电话号码一一对应的 tel 字段
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36',
'Cookie': '***'
}
# 获取手机号码对应的tel字段id(一一对应)
def get_tel_id():
# b2147f6a-6ec7-403e-a836-62978992841b对应企业,也是一一对应关系(网页源码)
url = "https://**/getentcontacts/b2147f6a-6ec7-403e-a836-62978992841b"
payload = {}
resp = requests.request("GET", url, headers=headers, data=payload).json()
tel_id = resp.get("tel")
return tel_id
然后,利用上面的 tel 字段组成图片 URL 地址
最后,就可以对图片进行文字识别了
这里介绍 2 种方式:
百度 OCR
pytesseract
2-1 百度 OCR
首先,安装依赖包
# 安装依赖包
pip3 install baidu-aip
然后,创建一个用于文字识别的应用,获取应用的 APP_ID、API_KEY、SECRET_KEY 数据
最后,参考官方文档调用下面的方法识别图片,获取手机号码数据
官网文档:
https://cloud.baidu.com/doc/OCR/s/wkibizyjk
from aip import AipOcr
def get_phone(tel_id):
"""
百度OCR识别图片,获取文字内容
:param tel_id:
:return:
"""
url = f'https://www.**.com/home/Phone/{tel_id}'
APP_ID = '262**'
API_KEY = '1btP8uUSzfDbji**'
SECRET_KEY = 'NGm6NgAM5ajHcksKs0**'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
result = client.basicGeneralUrl(url)
# {'words_result': [{'words': '0771-672**'}], 'words_result_num': 1, 'log_id': 1527210***}
print('识别到的手机号码为:', result)
2-2 pytesseract
同样,我们需要先安装文字识别、图片处理的依赖包
# 安装依赖包
pip3 install pillow
pip3 install pytesseract
然后,根据图片 URL 地址获取图片字节流,最后利用 pytesseract 识别图片中文字即可
import io
import pytesseract
import requests
from PIL import Image
if __name__ == '__main__':
# 获取手机号码的URL地址
image_url = f'https://www.**.com/home/Phone/{get_tel_id()}'
resp = requests.get(image_url, headers=headers)
# images.content: 获取图片的二进制字节流
# io.BytesIO(): 操作处理二进制数据
# Image.open(): 打开图片字节流,得到一个图片对象
images_c = Image.open(io.BytesIO(resp.content))
# 利用pytesseract识别出图片中的字符串,即为手机号码
phone = pytesseract.image_to_string(images_c)
print(f'联系方式: {phone}')以上就是应用图片伪装常规的处理方式,我们只需要找出图片的生成规则,然后利用 OCR 进行识别成文本,最后组装在一起即可
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
END