
爬虫 | 五八字体反爬
作者丨木下瞳来源丨木下学Python
前言
58二手车:
https://sz.58.com/ershouche/pn2/?PGTID=0d100000-0000-4e81-5801-e3cfbaae2802&ClickID=120
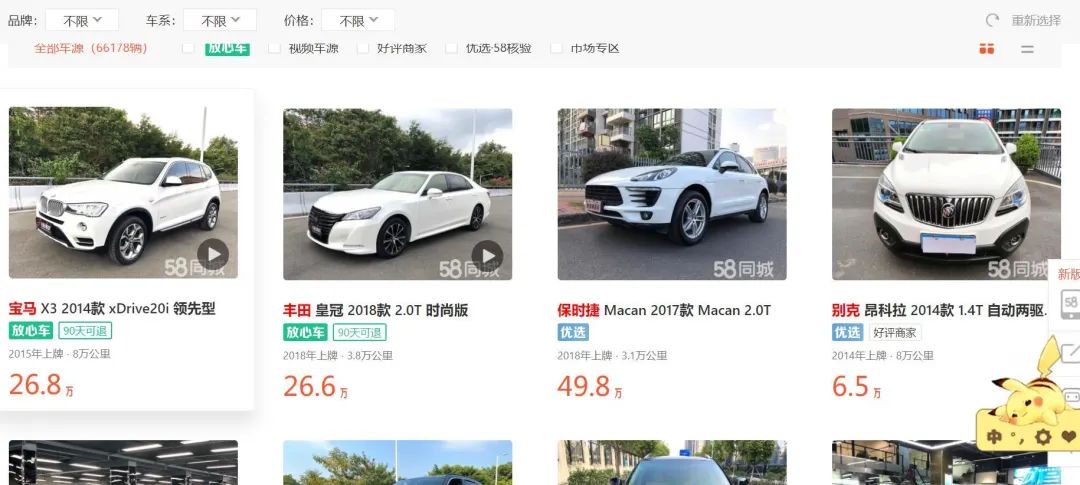
小编想爬一爬58同城的二手车,了解一下,爬取过程中在二手车的信息详情页,发现交易价的数字是加密过的:
我们来看一看怎么获取正确的数字。
字体文件获取
查看源代码发现,源代码里面返回的和我们右键检查的不一样:
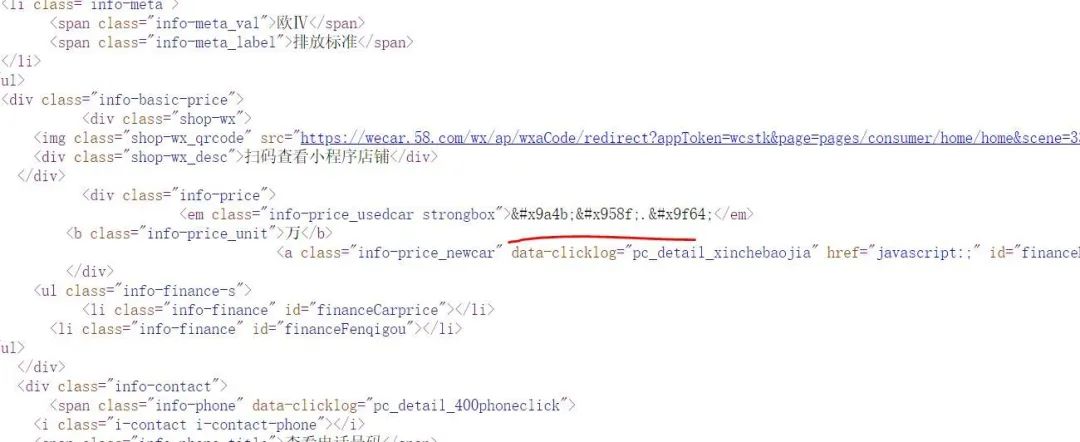
这是因为现实源代码里的数字加密了后,渲染到前端,以那些牛鬼蛇神的样子出现的。
字体加密,就会涉及到字体文件,字体文件后缀一般为 woff,ttf,我们在源代码里面搜索,由于太长,分两张图:


可以看到,这就是字体文件的链接内容,我们需要得到字体文件内容。
在这里看到了 base64,说明它后面这一串,也就是两个箭头之间的字符串的 base64 编码过的,这些字符串就是字体映射的内容。
src:url 后面一直到第二个箭头这段字符串是一个 url,访问这个链接,就会下载字体文件,由于 58 每一页的字体映射都不一样,这样每次请求会增加网络请求的时间。
所以我们采取 base64 解码,把两个箭头之间的字符串解码,解码的结果是二进制的,写入文件,后缀为 woff:
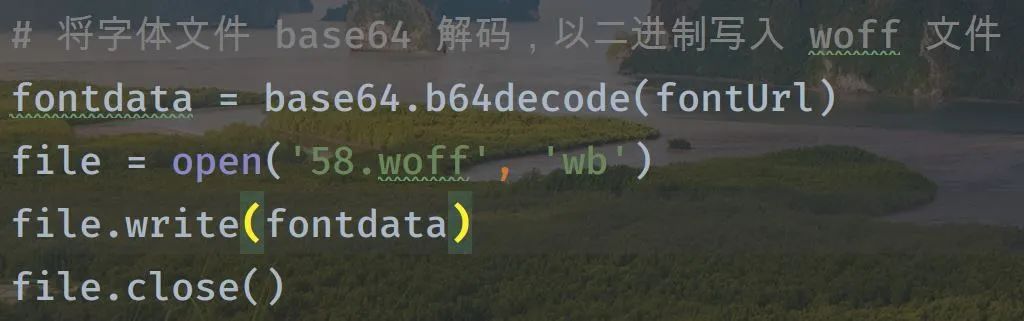
这样我们就获得了字体文件。
字体映射
由于我们不经过字体破解,直接爬取源代码得到的字体是:
驋閏.齤
这样的形式,我们就以这个来说明怎么转为正确的数字。
我们得到的字体文件,可以用 fontTools 库打开,我们需要另存为 xml 文件,这样是方便打开 xml 文件分析映射:
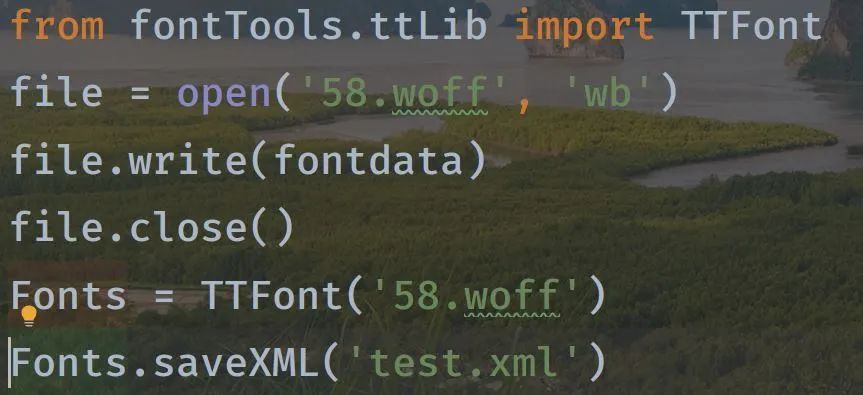
打开 xml 文件,有两个重要的部分:

驋 我们来看,&# 对应 code 属性的 0
0x9a4b 对应 name 属性的 glyph00003
name 的值为 glyph00003 对应的 id 属性为 3
由于是从上往下是从 1 开始,所以需要减一,才是映射的数字
可以通过 xml 库读取 xml 文件来进行字体映射转换:
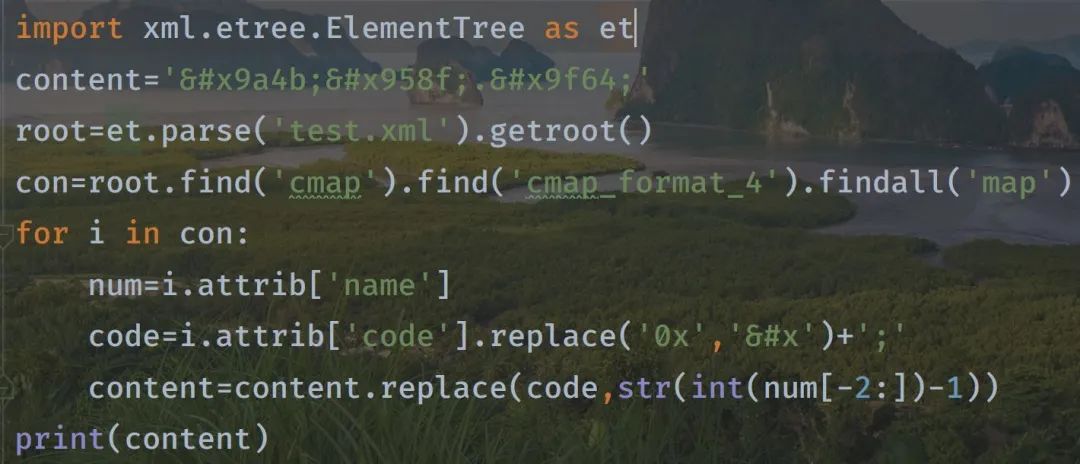
我们看看是否对应上了:
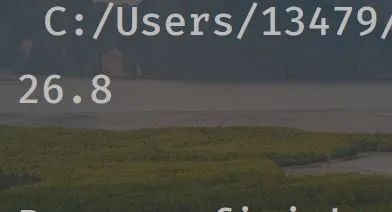

这样我们字体反爬就破解了。
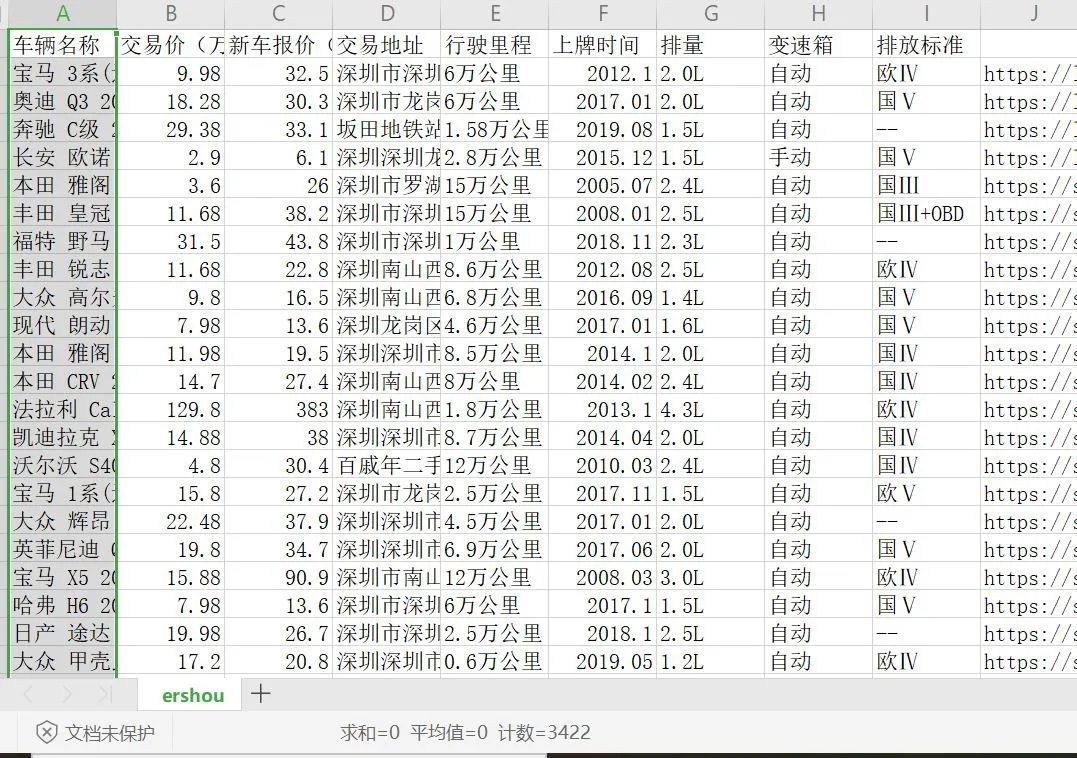
小编爬取的是深圳二手车的数据,爬虫已写好,想要爬虫的小伙伴可以去获取,来看看小编爬取的结果:

近期精彩内容推荐:


在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓