
1个字,绝! -- CNN中十大令人拍案叫绝的操作
前言
近十年是深度学习飞速发展的十年,自LeNet、AlexNet发展至今,通道注意力、空间注意力、生成对抗网络等技术层出不穷,最近大火的Transformer技术也在屠杀各种深度学习比赛的榜单,经过科学家的不懈努力,网络深度越来越深,网络模型的精度逐渐上升,网络的参数逐渐减少,模型越来越轻量化。该篇文章可以看作是我在研一的学习过程中所看上百部论文的精华所在,纯干货,建议收藏起来慢慢品味!

一、残差神经网络
残差神经网络(ResNet)是CVPR2016的最佳论文,说它是CVPR近二十年最佳论文也不为过,被引频次达70000+,这是我把残差神经网络排在第一位的原因。 另外,残差神经网络发现了深度神经网络中“退化”的问题,在ResNet出现之前,人们普遍认为神经网络深度越深,性能会越好,但ResNet的横空出世给了这些科学家当头一棒,随着网络层次越来越深,网络会出现“退化”的现象,什么是“退化”现象呢?简单来说,就是随着网络层次的加深,网络模型性能反而会出现下降的现象。ResNet的提出在一定程度上解决了深度神经网络中梯度消失和梯度爆炸的问题,对卷积神经网络的发展起到了非常重要作用。
另外,残差神经网络发现了深度神经网络中“退化”的问题,在ResNet出现之前,人们普遍认为神经网络深度越深,性能会越好,但ResNet的横空出世给了这些科学家当头一棒,随着网络层次越来越深,网络会出现“退化”的现象,什么是“退化”现象呢?简单来说,就是随着网络层次的加深,网络模型性能反而会出现下降的现象。ResNet的提出在一定程度上解决了深度神经网络中梯度消失和梯度爆炸的问题,对卷积神经网络的发展起到了非常重要作用。
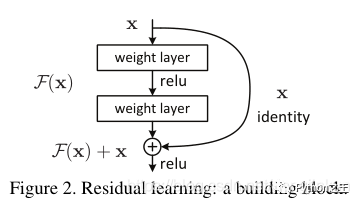 推荐论文:
推荐论文:
《https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html》
二、2个叠加的3*3卷积 <=> 5*5卷积
3*3卷积最早出现在VGGNet、GoogleNet中,之前的CNN中卷积核的大小一般为5*5或者7*7,这样的卷积核虽然会在一定程度上获得比3*3卷积核更大的感受野,但随之而来的是网络参数的剧增,使得网络层次难以叠加,网络难以运行。于是在VGG和GoogleNet中,使用叠加的3*3卷积获得的感受野与一个5*5卷积获得的感受野相同,但是参数却降低了,由 5×5×1+1 -->3×3×2+1。所以,之后出现的CNN网络模型中,很大再见到大的卷积核,绝大部分都是3*3卷积核了。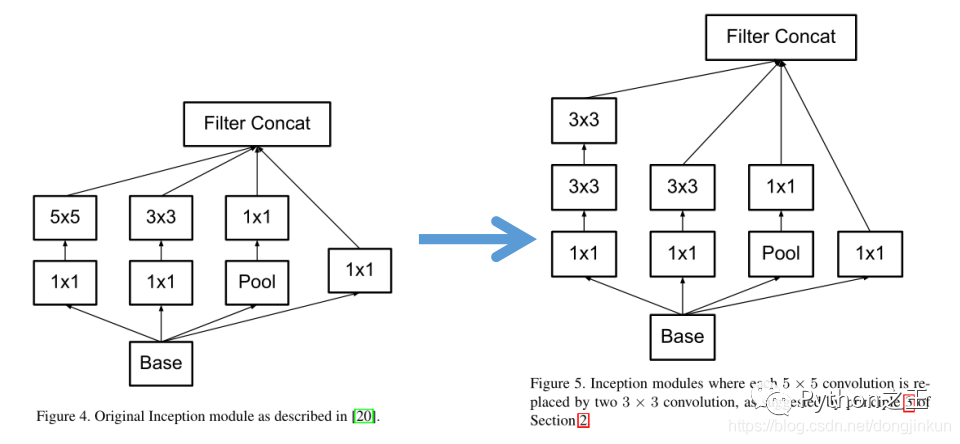 推荐论文:
推荐论文:
《https://arxiv.org/abs/1409.1556》
三、Inception结构
Inception结构的提出可以说在很大程度上打破了人们的思维定势的“陋习”,人类之前一直以为一层卷积上只能有一个尺寸的卷积核,也就是认为网络是一层一层堆积起来的,但Inception结构的提出打破了这一规则,同一层上可以有多个不同的卷积核来提取不同感受野的特征信息,使不同感受野的特征信息融合在一块,提升模型的性能。自我认为,该结构的提出也在一定程度上促进了何凯明大神金字塔池化的产生。但这个结构会存在一个致命的问题:参数量比单个尺寸的卷积核要多多,如此庞大的计算量会使得模型效率低下,一般的GPU上难以运行,这就引出了一个新的结构。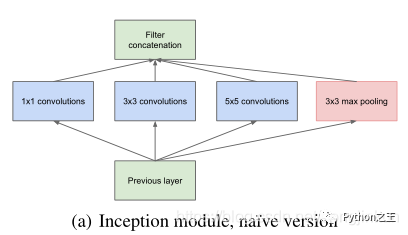 推荐论文:
推荐论文:
《Rethinking the Inception Architecture for Computer Vision》
四、Bottleneck(1*1卷积)
这一结构是针对上述Inception结构的弊端而提出,但我选进Bottleneck到这个榜单里的理由绝不仅于此。自我认为,Bottleneck提出的最大意义在于它发现了11卷积这个“万能”的卷积核,该卷积核不仅可以减少参数量,改变特征图通道的数量、而且还可以增加网络模型的非线性。因此,1×1卷积核也被认为是影响深远的操作,之后大型的网络模型为了降低参数量都会应用上1×1卷积核,以我目前的深度学习经验来讲,11卷积核几乎存在于任何一个可运行的网络模型中,它是一个网络模型必不可少的组成部分。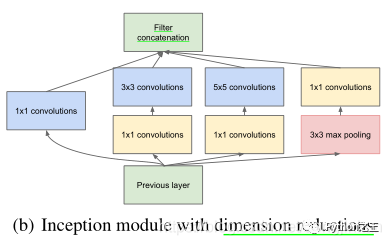
推荐论文:
《Going deeper with convolutions》
五、密集连接
DenseNet是2017CVPR上的最佳论文,对后来的卷积神经网络也有很大的贡献,首先,DenseNet重新定义了一种新的跳过连接(skip connection)-- 密集跳过连接。DenseNet让网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别「窄」,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。如果没有密集连接,DenseNet是不可能把网络设计得太窄的,否则训练会出现欠拟合(under-fitting)现象。
DenseNet的优势简单来说有三点:
①减少参数- ②节省计算资源- ③抗过拟合 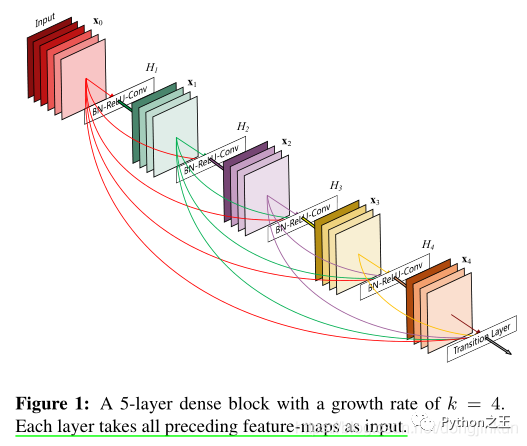 推荐论文:
推荐论文:
《Densely Connected Convolutional Networks》
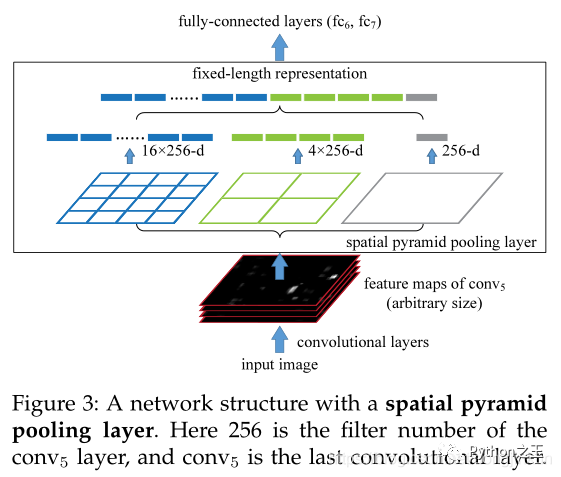
六、空间金字塔池化
空间金字塔池化是深度学习大神何凯明的又一力作,在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的神经元数目是固定的,所以在网络输入的时候,会固定输入的大小(fixed-size)。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小。然而通常的手法就是裁剪和拉伸。但是裁剪和拉伸会破坏原始图像的特征信息,而空间金字塔池化能够很好地解决这个问题。 具体内容可以参考这位大神的一篇文章[空间金字塔池化网络SPPNet详解]。(https://cloud.tencent.com/developer/article/1441559)
具体内容可以参考这位大神的一篇文章[空间金字塔池化网络SPPNet详解]。(https://cloud.tencent.com/developer/article/1441559)
 推荐论文:
推荐论文:
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
七、空洞卷积
空洞卷积也被称为膨胀卷积。感受野是卷积神经网络中非常重要的概念,空洞卷积的目的就在于扩大感受野,以提升模型的性能。空洞卷积的运行原理跟卷积非常类似,唯一不同之处在于空洞卷积引入了一个**扩张率(dilated rate)**的概念,可以认为,普通卷积是空洞卷积的一种情形,普通卷积的扩张率默认为1。
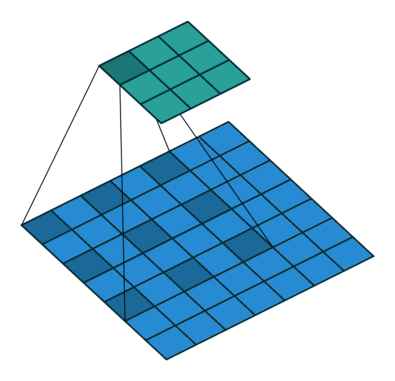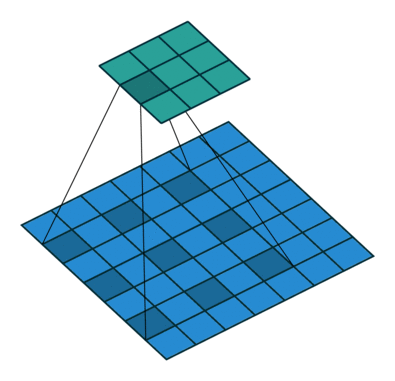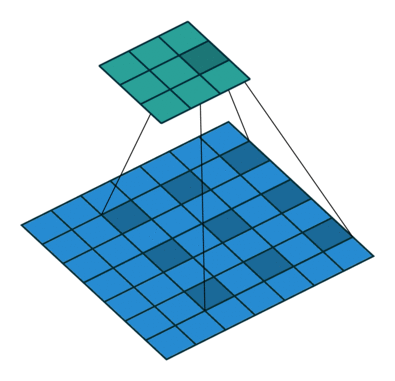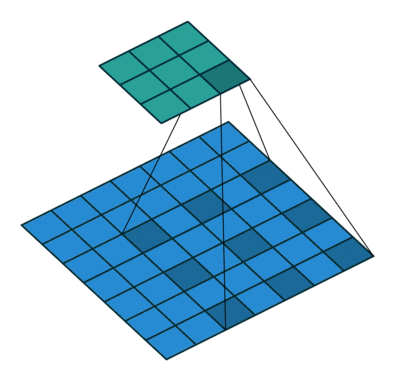 以下分别是dilated rate=1、dilated rate=6、dilated rate=24的空洞卷积。
以下分别是dilated rate=1、dilated rate=6、dilated rate=24的空洞卷积。
推荐论文:
《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》 《Rethinking Atrous Convolution for Semantic Image Segmentation》
八、注意力机制
在SENet横空出世之前,所有的网络模型都认为通道是等权重的,即没有重要与非重要之分,SENet的工作就是对各个通道进行加权,以分辨出哪些通道包含更重要的特征,哪些通道包含不太重要的特征就显而易见了。之后陆陆续续出现了各种各样的注意力,例如CBAM、Criss-Cross Attention、空间注意力等等,
①第一条支路直接让特征图通过- ②第二条首先进行Squeeze操作(Global Average Pooling),把每个通道2维的特征压缩成一个1维,从而得到一个特征通道向量(每个数字代表对应通道的特征)。然后进行Excitation操作,把这一列特征通道向量输入两个全连接层和sigmoid,建模出特征通道间的相关性,得到的输出就是每个通道对应的权重,然后把每个通道对应的特征权重与输入特征图(即第一条路)进行相乘,这样就完成了特征通道的权重分配。更加详细的过程请参考论文! 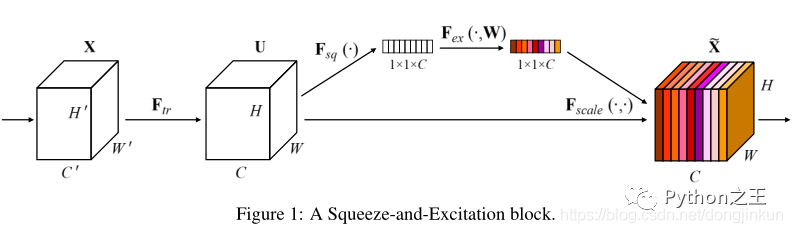 推荐论文:
推荐论文:
《》
九、Batch Normalization
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。
而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
除去BN之外,之后出现了很多归一化的方法,例如GN、LN、SN、IN等,关于归一化的方法,会在我的【都2021年了,不会还有人不了解深度学习吧?】中陆续更新,请大家多多关注! 推荐论文:
推荐论文:
《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
十、全卷积神经网络
CNN能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体,在2015年之前还是一个世界难题。直到神经网络大神Jonathan Long发表了FCN,在图像语义分割挖了一个坑,于是无穷无尽的人往这个坑里面跳。之所以把FCN选进这个榜单,是因为FCN的识别是像素级的识别 ,对输入图像的每一个像素在输出上都有对应的判断标注,标明这个像素最可能是属于一个什么物体/类别。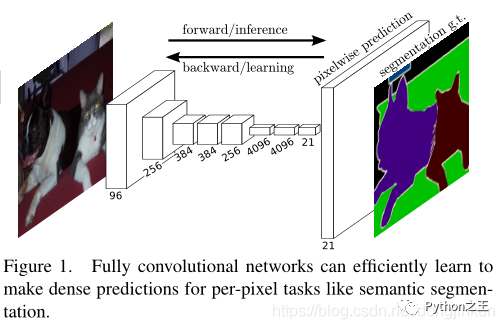
推荐论文:
《Fully Convolutional Networks for Semantic Segmentation》
参考文献
《Deep Residual Learning for Image Recognition》 《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》 《Rethinking the Inception Architecture for Computer Vision》 《Going deeper with convolutions》 《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》 《Rethinking Atrous Convolution for Semantic Image Segmentation》 《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》 《Squeeze-and-Excitation Networks》 《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》 《Fully Convolutional Networks for Semantic Segmentation》 https://blog.csdn.net/qqliuzihan/article/details/81217766 https://cloud.tencent.com/developer/article/1441559
以上纯属个人意见,如有不同看法,欢迎在评论区留言!