
CNN中神奇的1x1卷积
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

我们知道在CNN网络中,会有各种size的卷积层,比如常见的3x3,5x5等,卷积操作是卷积核在图像上滑动相乘求和的过程,起到对图像进行过滤特征提取的功能。但是我们也会遇见1x1的卷积层,比如在GoogleNet中的Inception模块,如下图:
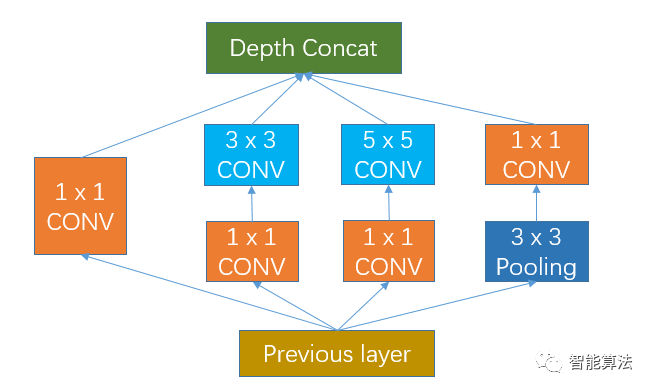
我们看到上图中有4个1x1的卷积,那么他们起着什么作用呢?为什么要这样做呢?
设计思路:考虑到有些物体比较大,有些物体比较小,所以用不同size的卷积核进行特征提取。其实最简单的可以看做是全连接,它的计算方式跟全连接是一样的。
增加非线性
1x1的卷积核的卷积过程相当于全链接层的计算过程,并且还加入了非线性激活函数,从而可以增加网络的非线性,使得网络可以表达更加复杂的特征。
特征降维
增加非线性好理解,通过控制卷积核的数量来达到通道数的缩放也好理解,那么怎么减少计算量和减少参数呢?我们从一个实例来看:假如前一层输入大小为28 x 28 x 192,输出大小为28 x 28 x 32,如下:
减少计算量:
不引入1x1卷积的卷积操作如下:
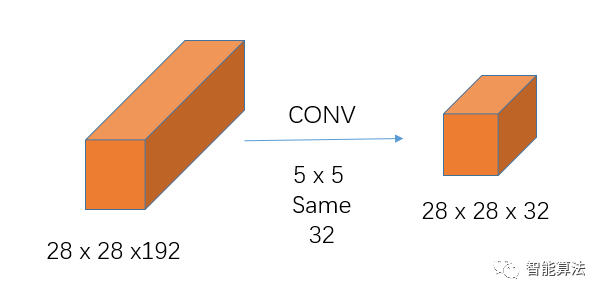
上图计算量为:
28 x 28 x 192 x 5 x 5 x 32 = 120,422,400次
引入1x1卷积的卷积操作:
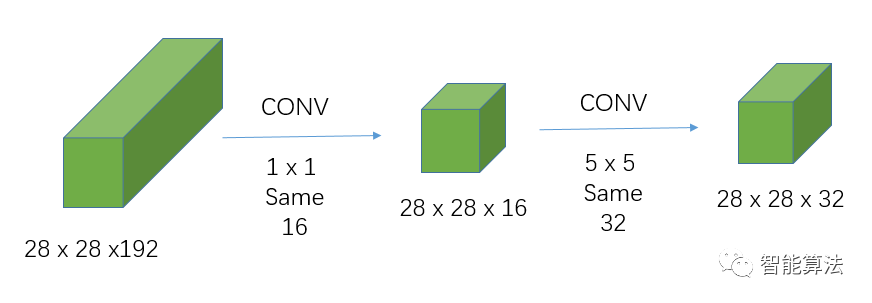
引入1x1卷积后的计算量为:
28 x 28 x 192 x 1 x 1 x 16 + 28 x 28 x 16 x 5 x 5 x 32 = 12,443,648次
从上面计算可以看出,相同的输入,相同的输出,引入1x1卷积后的计算量大约
是不引入的1/10。
Inception的初始版本就是没有加入1x1卷积的网络,如下图:
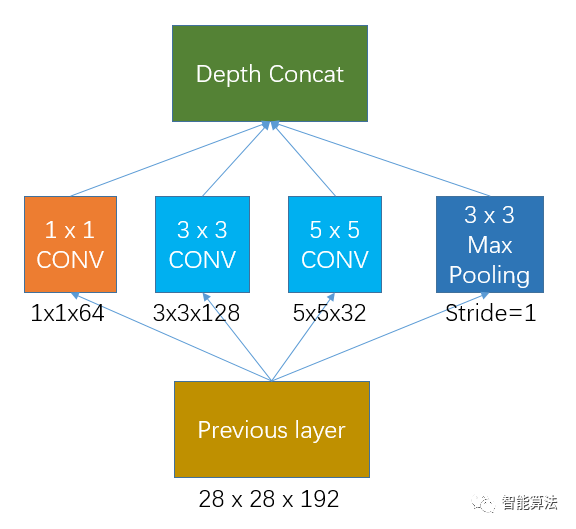
假如previous layer的大小为28x28x192,那么上面网络的权重个数为:
1 x 1 x 192 x 64 + 3 x 3 x 192 x 128 + 5 x 5 x 192 x 32 = 387072个
其输出的特征图大小为:
28 x 28 x 64 + 28 x 28 x 128 + 28 x 28 x 32 + 28 x 28 x 192 = 28 x 28 x 416
加入1x1卷积的Inception网络如下图,那么该网络的权重参数是多少呢?
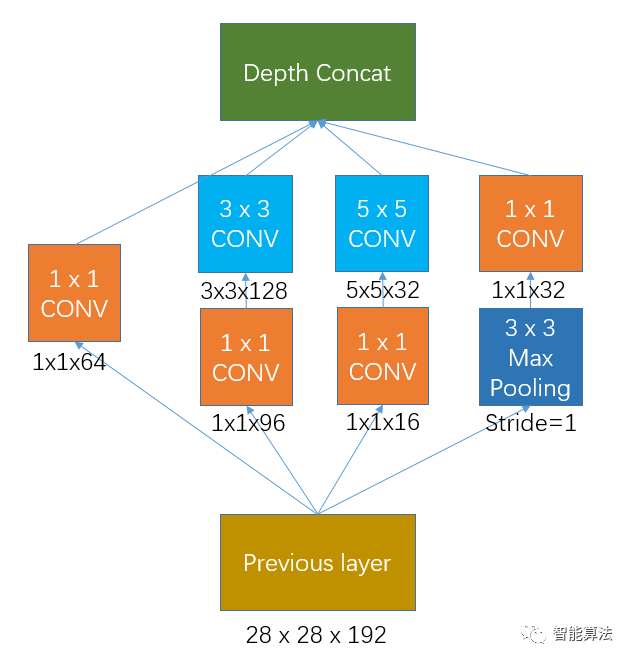
如果previous layer的大小为28x28x192,那么上面网络的权重个数为:
1 x 1 x 192 x 64 + (1 x 1 x 192 x 96 + 3 x 3 x 96 x 128) + (1 x 1 x 192 x16 + 5 x 5 x 16 x 32) + 1 x 1 x 192 x 32 = 163328个
可见加上1x1卷积后,权重个数从38.7万个左右降到16.3万个左右,同时增加了网络的非线性。
其输出的特征图大小为:
28 x 28 x 64 + 28 x 28 x 128 + 28 x 28 x 32 + 28 x 28 x 32 = 28 x 28 x 256
这样,1x1卷积的增加在增加网络非线性的同时,减少了网络的计算量和权重个数。你Get到了吗?
小白团队出品:零基础精通语义分割↓↓↓
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
