
AI 框架基础技术之自动求导机制 (Autograd)
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
AI编辑:我是小将
本文作者:OpenMMLab @小P家的 900420
https://zhuanlan.zhihu.com/p/347385418
本文已由原作者授权转载
0 前言
可以把神经网络看作一个复合数学函数,网络结构设计决定了多个基础函数如何复合成复合函数,网络的训练过程确定了复合函数的所有参数。为了获得一个“优秀”的函数,训练过程中会基于给定的数据集合,对该函数参数进行多次迭代修正,重复如下几个步骤:
前向传播
计算损失
反向传播(计算参数的梯度)
更新参数
这里第 3 步反向传播过程会根据输出的梯度推导出参数的梯度,第 4 步会根据这些梯度更新神经网络的参数,这两步是神经网络可以不断优化的核心。反向传播过程中需要计算出所有参数的梯度,这当然可以由网络设计者自己计算并且通过硬编码的方式实现,但是网络模型复杂多样,为每个网络都硬编码去实现参数梯度计算将会耗费大量精力。因此,AI 框架中往往会实现自动求导机制,以自动完成参数的梯度计算,并在每个 iter 中自动更新梯度,使得网络设计者可以将注意力放到网络结构的设计中,而不必关心梯度是如何计算的。
本文的内容基于我们自研的 AI 框架 SenseParrots,介绍框架自动求导的实现方式。本次分享将分为如下两部分:
自动求导机制介绍
SenseParrots 自动求导实现
1 自动求导机制介绍
从数学层面上看求导这个问题,有很多种分类方法:按照求导结果来分,可以分为数值求导和符号求导;按照求导顺序来分,可以分为 forward mode 和 reverse mode;按照导数阶数来分,可以分为一阶导和高阶导。在 AI 框架中实现自动求导,最终目标是拿到数值导数,这里有两种方式:第一种是直接进行数值导数的计算;第二种是先求出符号导数,再把数值带入进去。基于这个思路,目前主流 AI 框架中有两种完全不同的自动求导机制:
基于对偶图变换的自动求导机制
基于 reverse mode 的自动求导机制
1.1 基于对偶图的自动求导机制
基于对偶图的自动求导机制的实现思路是,首先通过一些模型解析手段获得目标函数对应的前向计算图,然后遍历前向计算图,使用计算图中每一个前向算子节点对应的反向算子节点构造出反向计算图,进而实现自动求导。这里获得的反向计算图相当于目标函数符号导数结果,与原函数无差别的,可以将反向计算图也用一个函数表示,传入不同的参数进行正常的调用。TVM 中基于对偶图实现了一套自动求导机制,这里给出一段代码示例:
s = (5, 10, 5)
t = relay.TensorType((5, 10, 5))
x = relay.var("x", t)
y = relay.var("y", t)
z = x + y
fwd_func = run_infer_type(relay.Function([x, y], z))
bwd_func = run_infer_type(gradient(fwd_func))
x_data = np.random.rand(*s).astype(t.dtype)
y_data = np.random.rand(*s).astype(t.dtype)
intrp = relay.create_executor(ctx=ctx, target=target)
op_res, (op_grad0, op_grad1) = intrp.evaluate(bwd_func)(x_data, y_data)1.2 基于 reverse mode 的自动求导机制
基于对偶图的自动求导机制实现思路清晰,且有一些优势:1、只需要实现一次符号倒数的求解,后续只需要用不同的数值多次调用就可以得到目标数值导数;2、高阶导的实现方式非常明显,只需要在求导结果函数上进一步调用自动求导模块。但是该方案对计算图和算子节点定义有比较严格的要求,前向算子节点和反向算子节点基本上要一一对应;另一方面,该方案需要先完成前向计算图的完整解析,才能开始反向计算图的生成,整个过程具有滞后性,所以适用于基于静态图的 AI 框架。在基于动态图的 AI 框架,如 PyTorch、SenseParrots 中,我们一般使用基于 reverse mode 的自动求导机制。
这里对 reverse mode 概念进行详细介绍。reverse mode,即依据[链式法则]的反向模式,指在进行梯度计算过程中,从最后一个节点开始,依次向前计算得到每个输入的梯度。基于 reverse mode 进行梯度计算,可以有效地把各个节点的梯度计算解耦开,每次只需要关注计算图中当前节点的梯度计算。
基于reverse mode进行梯度计算的过程可以分为三步,以下列复合函数计算为例:


1. 首先创建计算图:
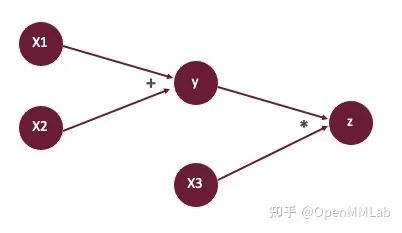
2. 然后计算前向传播的值,即  。
。
3. 在进行反向传播时,基于给定的输出  的梯度
的梯度  ,依次计算:
,依次计算:



在基于动态图的 AI 框架中,计算图的创建发生在前向传播过程中,于是基于 reverse mode 的自动求导机制,整体过程可以简化为两步:第一步是在前向传播过程中构建出计算图,与基于对偶图的自动求导机制的滞后性相反,这里在前向传播过程中就可以构造出的反向计算图;第二步是基于输出的梯度信息对输入自动求导。更多的细节将在下一章节展开。
2 SenseParrots 自动求导实现
2.1 自动求导机制组件
SenseParrots 是一个基于动态图的AI框架(在线编译功能部分进行了局部静态化,并不影响自动求导的整体机制),自动求导机制采用上述的反向模式,整个自动求导机制主要依赖于以下三个部分:
DArray: 计算数据的数据结构, 可以想象成多维数组, 其中包含参与运算的数据、其梯度及以其作为输出的 GradFn。
Function: 一个基本的运算单元,包括一个操作的正向计算函数及其反向计算函数,每个计算过程对应一个 Function。比如一个 ReLU 激活函数的 Function 包括如下两部分
Class ReLU : Function {
DArray forward(const DArray& x) {
DArray y = ...; // ReLU正向计算过程
return y;
}
DArray backward(const DArray& dy) {
DArray dx = ...; // ReLU反向计算过程
return dx;
}
};
GradFn: 计算图中的节点,每个 Function 在执行正向计算的时候会产生一个 GradFn 对象,保存了输入和输出的梯度信息的指针、Function 指针以确定反向计算要调用的函数、后继 GradFn 节点指针,该对象保存在该 Function 前向计算的输出 DArray 中。
PS: SenseParrots 完全兼容 PyTorch,也为了方便大家理解,后文中涉及到的代码采用 Torch 接口。
2.2 自动求导机制的控制选项
DArray 的 requires_grad 属性标志该数据是否需要求梯度。requires_grad 设置为 True 时计算梯度,并且会生成 LeafGradFn(GradFn 的子类)来标识该节点为叶子节点,计算图的构造依赖于输入的 requires_grad 属性;
框架是否开启求导。默认情况下框架是开启求导的,也提供了显示的开关求导的接口:torch.no_grad()、torch.enable_grad(),在框架关闭求导功能的情况下,不会构造计算图。
2.3 前向传播过程中构造计算图
SenseParrots 在前向计算过程中,会根据用户定义的计算过程,依次调用每个 Function 中的前向计算函数来完成计算。在调用每一个 Function 时,首先判断输入中是否有需要求梯度的:
如果输入都不需要求梯度,则不会构造计算图,直接调用函数计算得到输出, 并将输出的 requires_grad 设置为 False;
如果输入中有需要求梯度的,则调用函数计算得到输出, 并将输出的 requires_grad 设置为 True, 同时会相应生成一个 GradFn 对象,并完成如下关联工作(“保存”都是以 shared_ptr 方式):
将该 Function 记录进该 GradFn 对象,以表明在反向求导时,用 GradFn 中记录的 Function 的反向计算函数来进行梯度计算;
将该 Function 前向计算函数的输入 DArray 的梯度记录进 GradFn 对象,将该 Function 前向计算函数的输出 DArray 的梯度记录进 GradFn 对象;
将该 Function 前向计算函数的输入 DArray 中所记录的 GradFn 记录为 GradFn 的后继节点;
将该 GradFn 保存进 Function 前向计算函数的所有输出当中。
由最初的输入数据(叶子节点)开始,依次执行 Function,便可以构造得到一张完整的计算图。下面举例子介绍计算图的构造过程(框架默认启用求导功能的情况下):
import torch
x1 = torch.randn((2,3,4), requires_grad=True)
x2 = torch.randn((2,3,4), requires_grad=True)
x3 = torch.randn((2,3,4))
x4 = torch.randn((2,3,4))
y1 = x1 + x2
y2 = x3 + x4
z = y1 * y2
z += x2首先我们计算的输入数据为 x1、x2、x3、x4,当前计算图中 x1、x2 需要计算梯度,已经创建 LeafGradFn 节点,而 x3、x4的 GradFn 都为空指针,因此,最初的计算图中包含两个节点,即 x1、x2 的 LeafGF1、LeafGF2。

以 x1、x2 作为输入,调用 "+" Function 的正向计算函数,得到输出 y1,因为 x1、x2 都需要计算梯度,设置 y1 的 requires_grad=True,同时生成 GradFn,GF1, 将 "+" Function 记录到 GF1 中,将输入 x1、x2 的梯度记录到 GF1 中,将输出 y 的梯度记录在 GF1 中,将 x1、x2 的 GradFn 记录为 GradFn 的后继节点,将 GF1 保存在 y1 中;当前计算图中有 3 个节点:LeafGF1、LeafGF2、GF1。
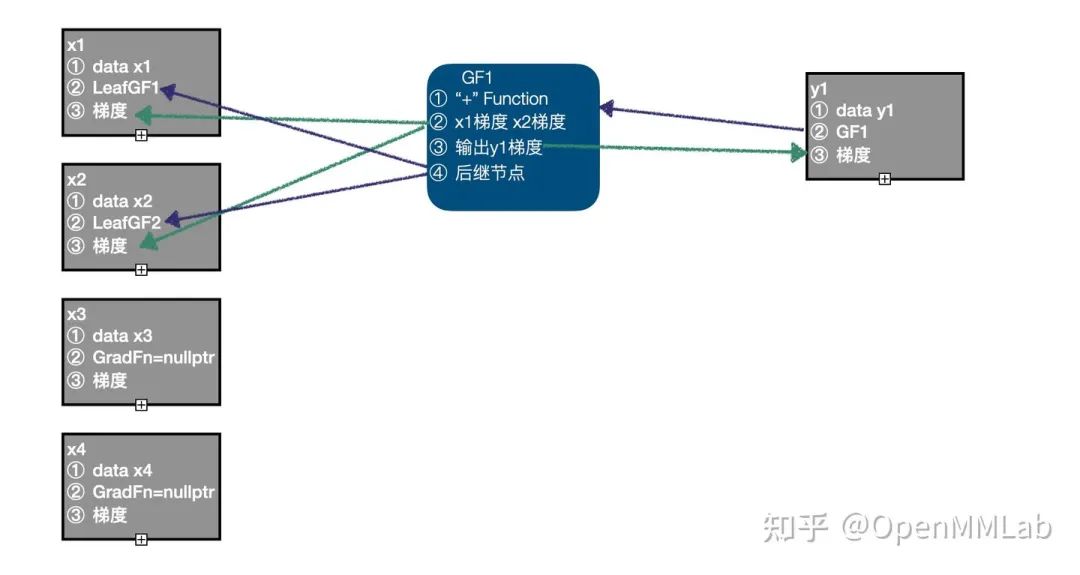
以 x3、x4 作为输入,调用 "+" Function 的正向计算函数,得到输出 y2, 因为 x3、x4 都不需要计算梯度,y2 的 requires_grad=False, 此时计算图中仍然只有 3 个节点:LeafGF1、LeafGF2、GF1。
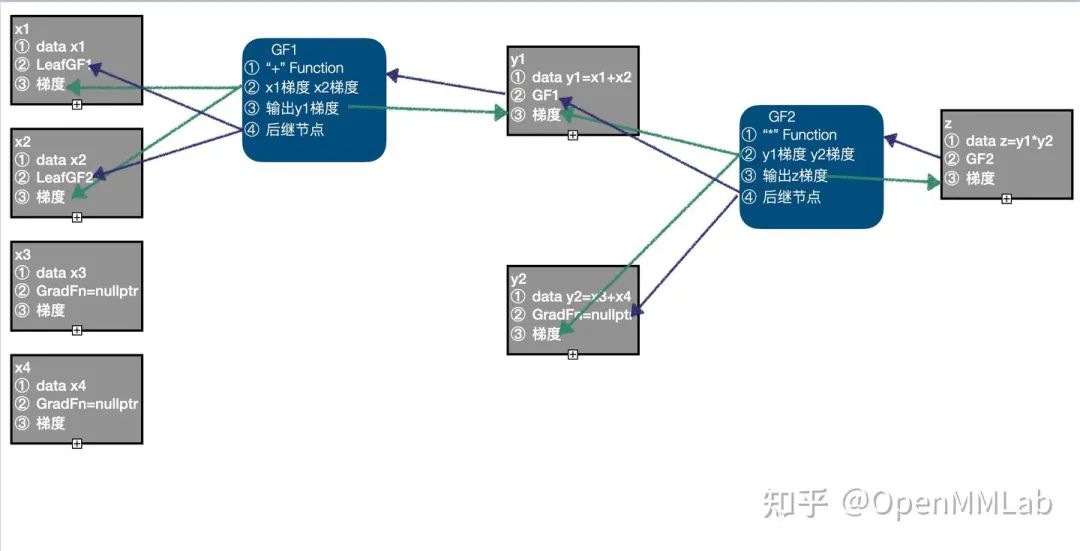
以 y1、y2 作为输入,调用 "*" Funtcion 的正向计算函数,得到输出 z,由于输入 y1 需要计算梯度,设置 z 的 requires_grad=True,同时生成 GradFn GF2,并且完成相应信息的关联,当前计算图中有 4 个节点:LeafGF1、LeafGF2、GF1、GF2。
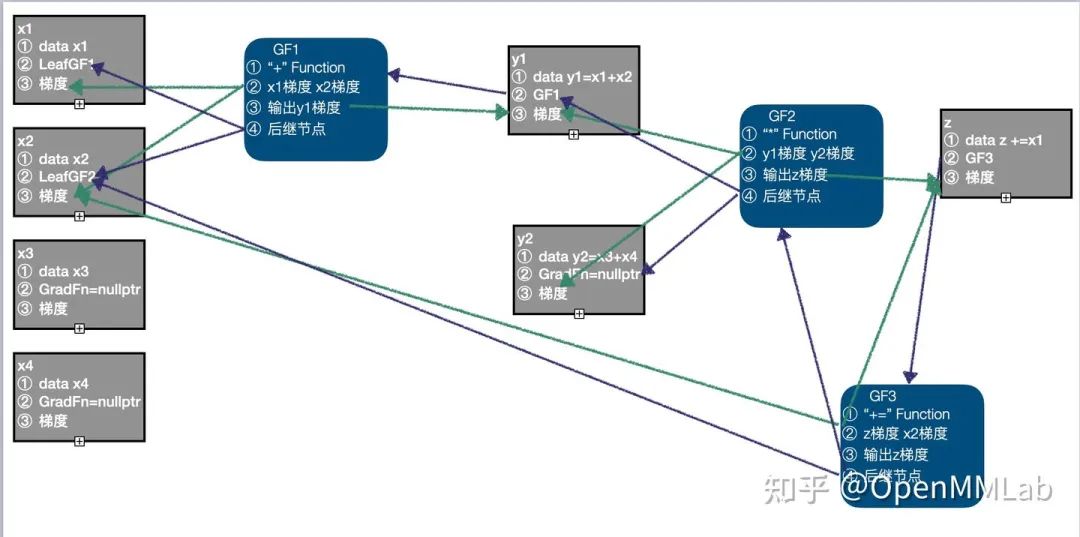
需要注意的是,最后一个计算 "+=" 是一个 inplace 的计算,即以 z、x2 为输入,计算结果 z,在处理 inplace 计算时,仍然遵循同样的 GradFN 构造方式即可,同时构造 GF3,将 "+=" Function、输入 x1 梯度、z 梯度、输出 z 梯度、后继节点 GF2、LeafGF1 记录进 GF3,需要注意的是,这里将 z 中的 GradFn 更新为 GF3,而原来z中保存的 GF2 作为 GF3 的后继节点了,此时计算图中有 5 个节点:LeafGF1、LeafGF2、GF1、GF2、GF3。
由此得到了完整的计算图,并且完成了相关信息的关联,完整的计算图如下:
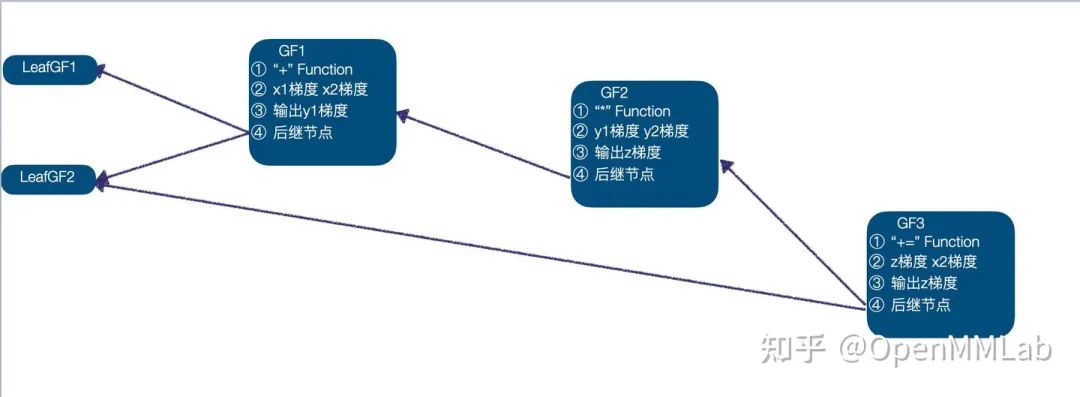
2.4 基于输出的梯度信息对输入自动求导
z.backward(torch.ones_like(z))在基于动态图的 AI 框架中,反向求导过程通常是由上述的.backward(梯度)函数触发的。SenseParrots 的反向求导过程,首先根据给定的输出梯度,更新最终输出的梯度值;然后对计算图中节点进行拓扑排序,获得满足依赖关系的 GradFn 的执行顺序;依次执行 GradFn 中所记录 Function 的反向计算函数,根据输出的梯度,计算并更新输入的梯度。
首先看一下上述例子,其中 x1 只与一个 GradFn 相关,其梯度只会被计算一次,这种输入只影响单个输出的情况,是反向求导中最简单的一种情况;x2 与两个 GradFn 相关,这是反向求导中,一个输入影响多个直接输出的情况,需要注意,输入 x2 的梯度也会被计算两次,在梯度更新时,需要将多次计算得到的梯度进行累加;z 的计算涉及到 inplace 操作,我们在 2.3 的第 5 步中说明了该情况的处理。下面介绍上述例子的反向求导过程:
基于给定的 z 的梯度信息,更新z中的梯度值;
基于计算图进行拓扑排序,获得 GradFn 的执行队列(一个可能的序列为:GF3 -> GF2 -> GF1 -> LeafGF1 -> LeafGF2);
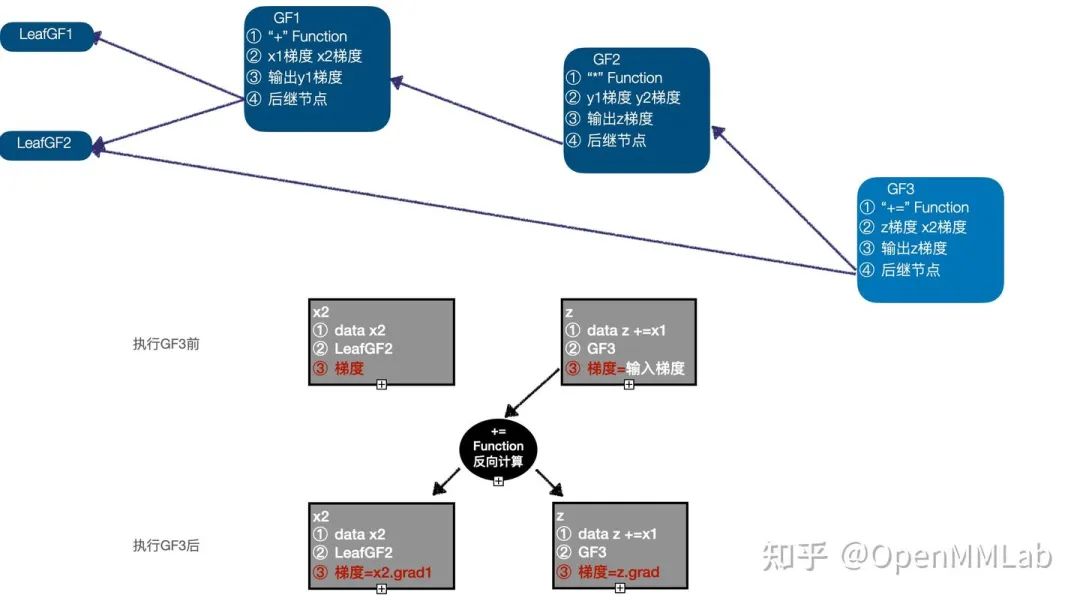
开始反向求导,首先执行 GF3,GF3 是一个 inplace 操作,以 z 的梯度作为输入,调用 "+=" Function 的反向计算函数,计算并更新 z、x2 的梯度,此时执行队列为(GF2 -> GF1 -> LeafGF1 -> LeafGF2);
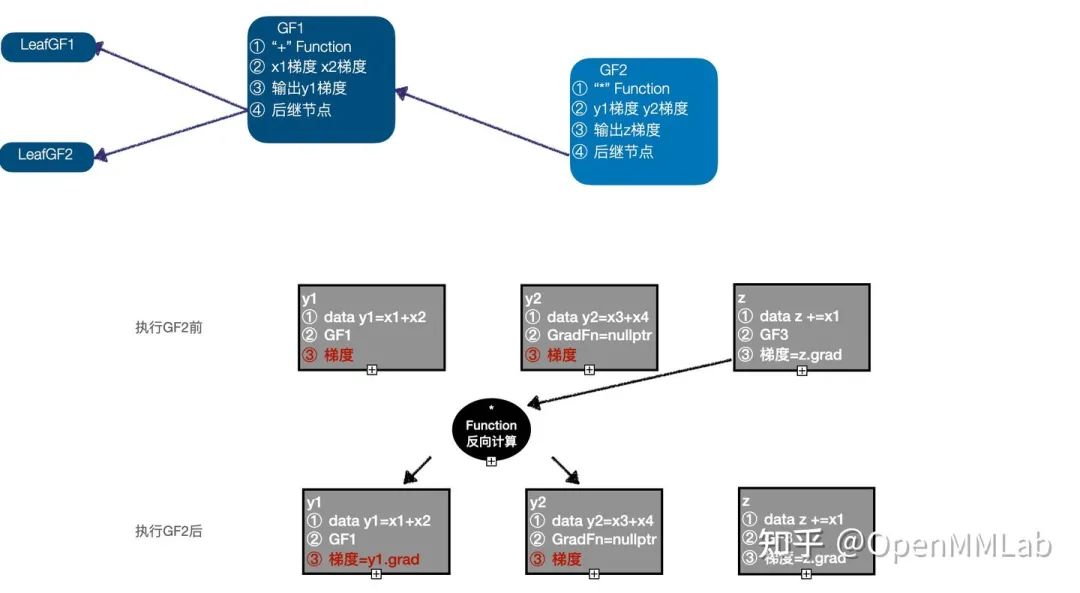
4. 执行 GF2,以 GF3 计算之后的 z 的梯度作为输入,调用 "*" Function的反向计算函数,计算 y1、y2 的梯度, 更新 y1 的梯度,因为 y2 不需要求梯度,所以其梯度信息舍弃, 此时执行队列为(GF1 -> LeafGF1 -> LeafGF2);
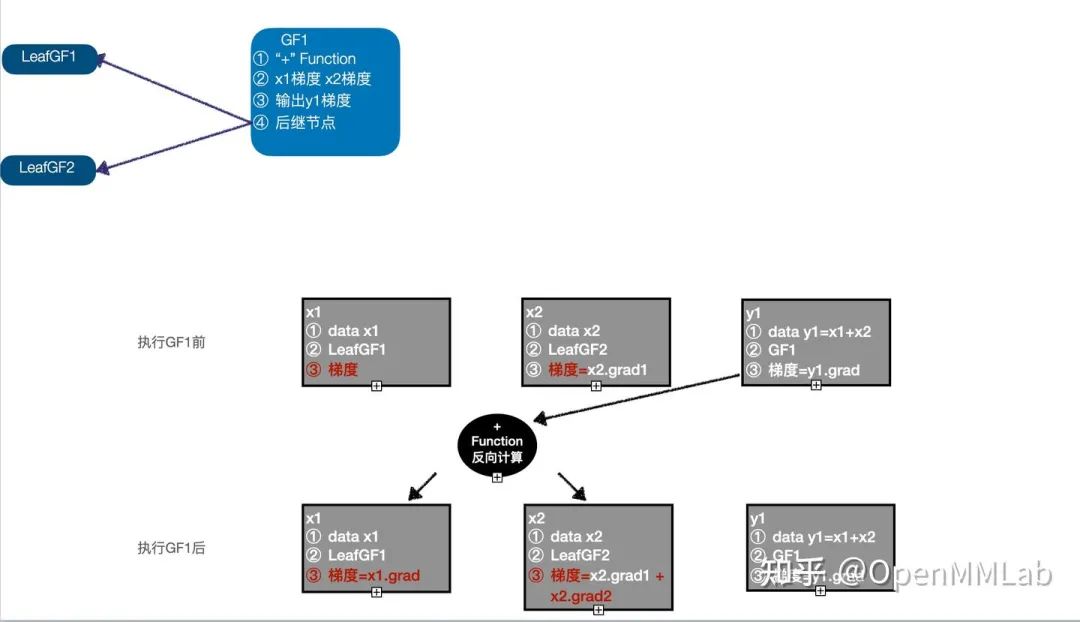
5. 执行 GF1,以 y1 的梯度作为输入,调用 "+" Function 的反向计算函数,计算 x1、x2 的梯度,更新 x1 的梯度,而 x2 的梯度信息需要在之前计算结果的基础上累加,此时执行队列为(LeafGF1 -> LeafGF2);
6. 依次执行 LeafGF1、LeafGF2。

7. 执行队列为空,反向求导过程结束,默认情况下计算图会被清空,非叶子节点的梯度信息清空。由此得到了需要的计算梯度。

推荐阅读
谷歌提出Meta Pseudo Labels,刷新ImageNet上的SOTA!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
CondInst:性能和速度均超越Mask RCNN的实例分割模型
mmdetection最小复刻版(十一):概率Anchor分配机制PAA深入分析
MMDetection新版本V2.7发布,支持DETR,还有YOLOV4在路上!
无需tricks,知识蒸馏提升ResNet50在ImageNet上准确度至80%+
不妨试试MoCo,来替换ImageNet上pretrain模型!
mmdetection最小复刻版(七):anchor-base和anchor-free差异分析
mmdetection最小复刻版(四):独家yolo转化内幕
机器学习算法工程师
一个用心的公众号
