
AI 框架部署方案之模型转换
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


导读
模型转换是模型部署的重要环节之一,本文会从深度学习训练框架的角度出发,讲一讲作者本人对模型转换的理解。

1 模型转换的意义
模型转换是为了模型能在不同框架间流转。
在实际应用时,模型转换几乎都用于工业部署,负责模型从训练框架到部署侧推理框架的连接。这是因为随着深度学习应用和技术的演进,训练框架和推理框架的职能已经逐渐分化。
分布式、自动求导、混合精度……训练框架往往围绕着易用性,面向设计算法的研究员,以研究员能更快地生产高性能模型为目标。
硬件指令集、预编译优化、量化算法……推理框架往往围绕着硬件平台的极致优化加速,面向工业落地,以模型能更快执行为目标。
由于职能和侧重点不同,没有一个深度学习框架能面面俱到,完全一统训练侧和推理侧,而模型在各个框架内部的表示方式又千差万别,所以模型转换就被广泛需要了。
2 模型转换的技术细节
2.1 计算图生成
目前使用广泛的训练框架 PyTorch,以及商汤自研的训练框架 SenseParrots 使用的都是动态图,这是由于动态图的表达形式更易于用户快速实现并迭代算法。动态图框架会逐条解释,逐条执行模型代码来运行模型,而计算图生成是的本质是把动态图模型静态表达出来。PyTorch 的torchscript、ONNX、fx 模块都是基于模型静态表达来开发的。目前常见的建立模型静态表达的方法有以下三种:
代码语义分析:通过分析用户代码来解析模型结构,建立模型静态表达。 模型对象分析:通过模型对象中包含的成员变量,来确定模型算子组成,建立模型静态表达。 模型运行追踪:运行模型并记录过程中的算子信息、数据流动,建立模型静态表达。
上面这三种方法在适用范围、静态抽象能力等方面各有优劣。目前训练框架都主要使用模型运行追踪的方式来生成计算图:在模型inference 的过程中,框架会记录执行算子的类型、输入输出、超参、参数等算子信息,最后把 inference 过程中得到的算子节点信息和模型信息结合得到最终的静态计算图。
2.2 计算图中的自定义算子
很多时候,用户的一段代码可能涉及非框架底层的计算,例如下面这段代码,涉及外部库的计算,训练框架自身是无法追踪记录到的。
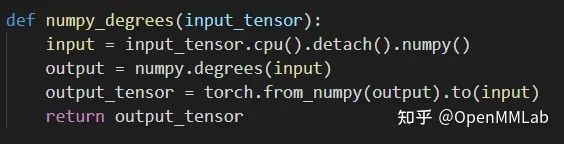
这个时候我们可以把这部分代码作为一个自定义算子,由用户定义这个算子在计算图中作为一个节点所记录的信息。实际实现时,这些计算会被写到一个 Function 或者 Module 中,然后用户在 Function 或者 Module 中定义这个计算对应的计算节点的信息表达,这样每次调用这个定义好的 Function 或者 Module,就能对应在计算图中记录相应的算子信息。
当然还有很多其他场景会产生这种需要,例如你的几个计算组成了一个常见的函数,可以有更高层的表达,这个时候也可以使用自定义算子来简化计算图的表达。
2.3 目标格式(caffe/ONNX)
模型转换往往将模型转换到一种中间格式,再由推理框架读取中间格式。
目前主流的中间格式有 caffe 和 ONNX(Open Neural Network Exchange),两者底层都是基于 protobuf (Google 开发的跨平台协议数据交换格式工具库)实现的。
caffe 原本是一个经典的深度学习框架,不过由于出现较早且不再维护,已经少有人用它做训练和推理了。但是它的模型表达方式却保留了下来,作为中间格式在工业界被广泛使用。
ONNX 是各大 AI 公司牵头共同开发的一个中间表达格式,用于模型格式交换,目前在社区非常活跃,处于不断更新完善的阶段。
由于 caffe 出现较早,在使用上对硬件部署侧比较友好(原生算子列表在推理侧容易实现,而且 caffe 使用 caffe.proto 作为模型格式数据结构的定义,能实现中心化、多对一),目前很多推理侧硬件厂商依然使用 caffe,很多端到端的业务解决方案,也喜欢使用 caffe。
而 ONNX 有丰富的表达能力、扩展性和活跃的社区,深受训练侧开发者、第三方工具开发者的喜爱, PyTorch 早已将 ONNX 作为官方导出格式进行支持,而 TensorFlow 也非官方地支持 ONNX。
2.4 计算图转换到目标格式
计算图转换到目标格式就是去解析静态计算图,根据计算图的定义和目标格式的定义,去做转换和对齐。这里的主要的工作就是通用的优化和转换,以及大量 corner case 的处理,相信看过 PyTorch 的 ONNX 导出源码,或者自己做过相关工作的人都深有体会。
2.4.1 计算图转换到 caffe
一般支持 caffe 的推理框架都是在原生 caffe 的基础上自己额外定义了一些算子(有的还会修改一些原生 caffe)的算子,这些改动都能体现在caffe.proto上:例如下图所示例子就是Mean(PartialMean)在 caffe.proto 中的定义。使用这样的 proto 文件和 protobuf,才能生成带 Mean 算子的 caffe 格式模型(.prototxt, .caffemodel)。
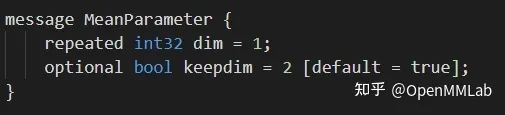
这是一个以推理框架为中心的生态,不同的推理框架提供不同的 caffe.proto,就可以形成各自的算子定义和约束,平时我们把推理框架自己定义的 caffe 格式称为 caffe 后端。
计算图转换到 caffe,就是将计算图的算子进行分发映射,转换到不同的 caffe 后端,计算图的算子和 caffe 中的算子可能存在一对多、多对一的映射关系。我们遍历现有的计算图算子列表,能够很自然地去处理一对多的转换映射,而多对一的映射关系就需要针对每个 caffe 后端配置各自的计算图优化pass去预处理计算图。
2.4.2 计算图转换到 ONNX
ONNX 官方定义了算子集 opset,并且随着 ONNX 的演进,在写下这篇文章的时候,版本已经迭代到了 opset15。opset 版本的迭代伴随着算子支持列表和算子表达形式的改动,因此针对不同的 opset 也需要有多后端 ONNX 的支持。另一方面,对于在 opset 之外的算子,用户需要自己注册定义算子在 ONNX 的表达信息(输入、输出、超参等)。
另一方面,推理框架对于 ONNX 官方 opset 往往也不是完全支持,会有自己的一些取舍。所以对于 ONNX 模型,往往需要用相关的 simplifier 进行模型预处理优化,围绕这一方面模型转换或者部署框架的工程侧也有不少的相关工作。
2.4.3 onnxruntime 和 caffe 的推理能力
和五花八门的芯片等端侧硬件相比,x86 和 CUDA 平台是普及率最高的平台,因此如果是出于部署测试、转换精度确认、量化等需要,一个能够在 x86 或者 CUDA 平台运行的 runtime 是非常必要的。
对此,支持 ONNX 格式的部署框架一般会基于 onnxruntime(微软出品的一个具有 ONNX 执行能力的框架)进行扩展,支持 caffe 格式的部署框架一般会基于原生 caffe 进行扩展。通过 onnxruntime 和 caffe 的推理运行能力,来提供在 x86 或者 CUDA 平台上和硬件平台相同算子表达层次的运行能力。
当然还有一些生态较好的部署框架,他们自己提供算子表达能力和计算精度与硬件一致的 x86 或 CUDA 平台的模拟器。
2.5 端到端的模型转换
还有一些模型转换是直接从框架到框架对接一步到位的,相比使用中间格式的方案非常定制化。
例如由英伟达官方出品的 CUDA 平台的部署框架 TensorRT,支持用户编写转换代码,直接从 PyTorch 转换到 TensorRT。
这种端到端的模型转换,是一种抛弃了中间格式的中心化转换方法,省去了很多麻烦,往往在整个平台完全自研自主使用,或者业务构成本身比较单一(解决方案的训练框架和部署框架完全确定)等实际情况下落地使用。
3 总结
模型转换是一个由现有的深度学习技术格局和业务需求衍生出的工程方向,作者这里只是从训练框架部署的角度介绍了一下自己的意见,相信很多来自其他方向或者接触其他业务的人会有着自己的实践和理解,也非常欢迎大家积极分享交流。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!