
算力系列:AI服务器催化HBM需求爆发
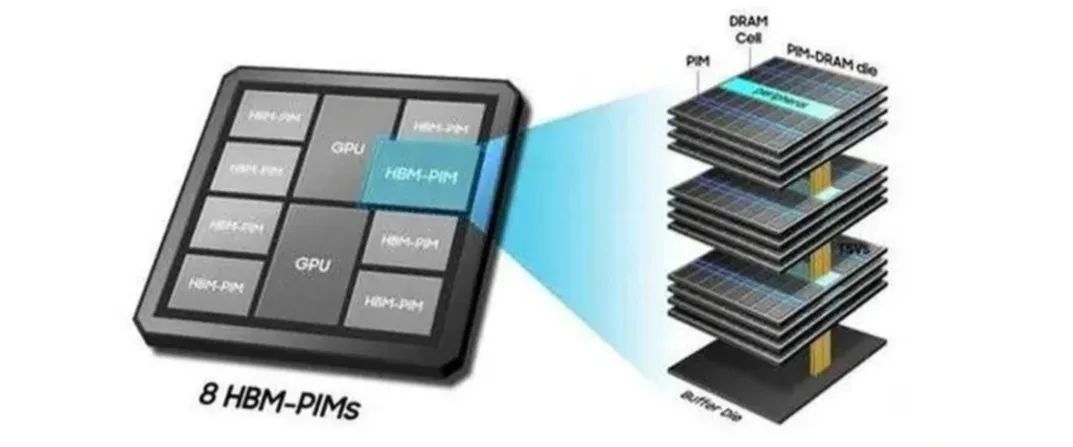

本文来自“AI服务器催化HBM需求爆发,核心工艺变化带来供给端增量(2024)”。HBM即高带宽存储,由多层DRAMdie垂直堆叠,每层die通过TSV穿透硅通孔+μbumps技术实现与逻辑die连接,使得8层、12层die封装于小体积空间中,从而实现小尺寸于高带宽、高传输速度的兼容,成为高性能AI服务器GPU显存的主流解决方案。
目前迭代至HBM3的扩展版本HBM3E,提供高达8Gbps的传输速度和16GB内存,由SK海力士率先发布,将于2024年量。
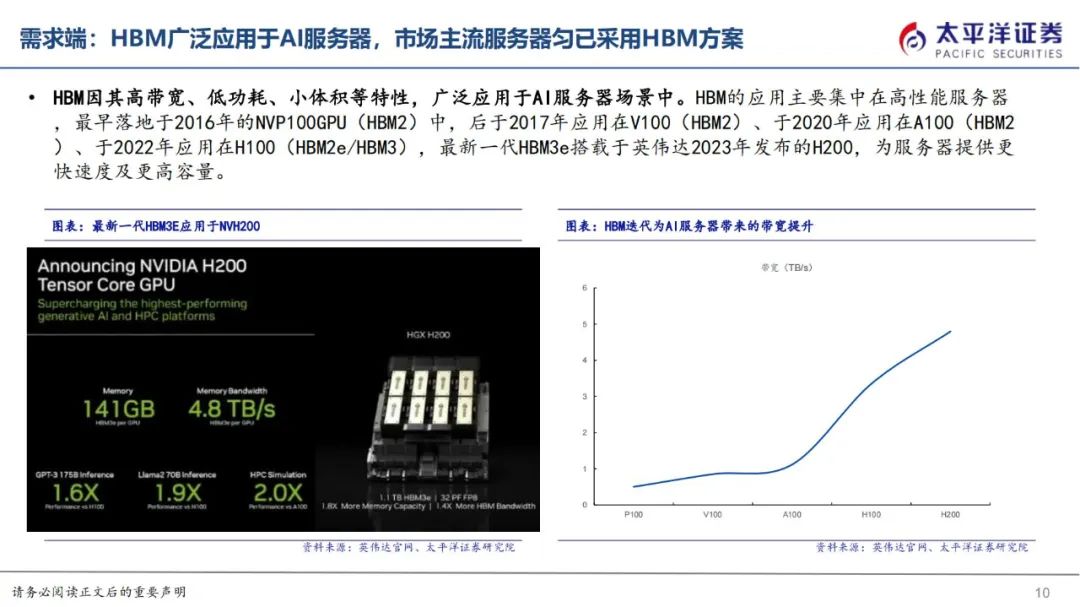
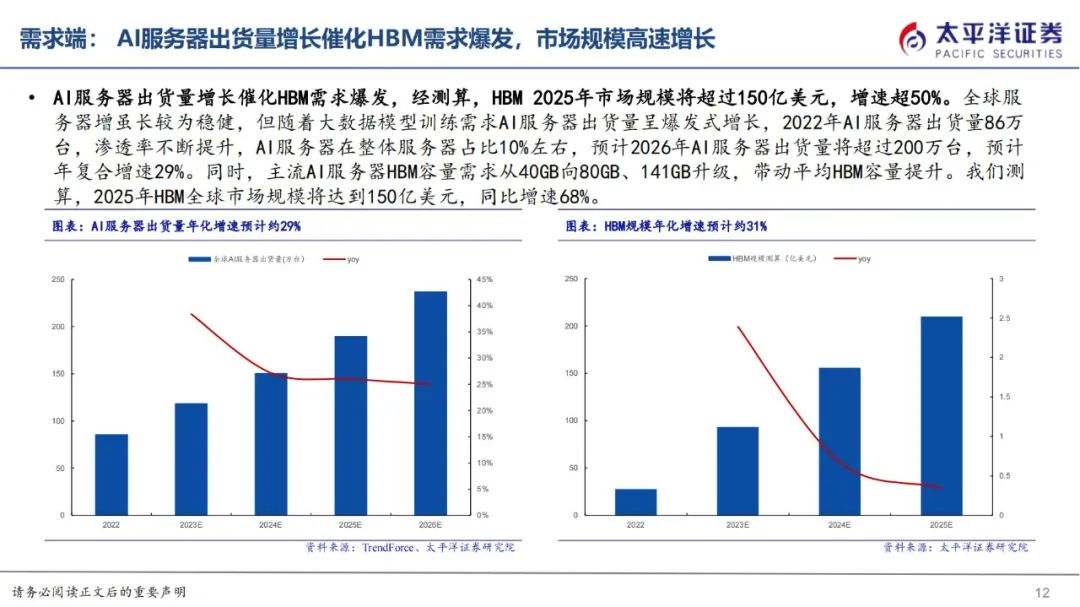
HBM主要应用场景为AI服务器,最新一代HBM3e搭载于英伟达2023年发布的H200。根据Trendforce数据,2022年AI服务器出货量86万台,预计2026年AI服务器出货量将超过200万台,年复合增速29%。AI服务器出货量增长催化HBM需求爆发,且伴随服务器平均HBM容量增加,经测算,预期25年市场规模约150亿美元,增速超过50%。
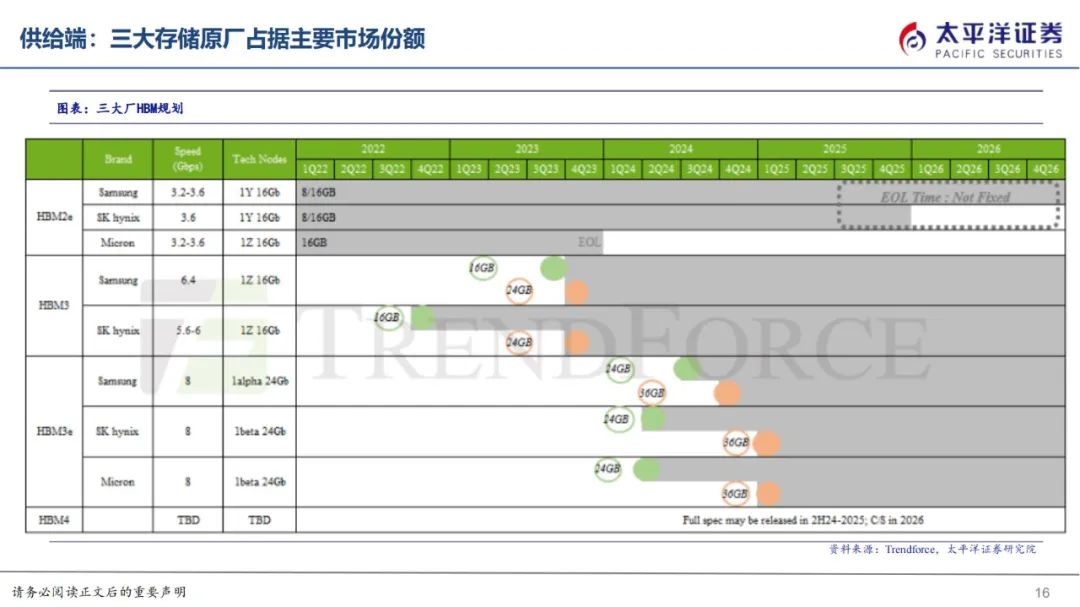
HBM供给厂商主要聚集在SK海力士、三星、美光三大存储原厂,根据Trendforce数据,2023年SK海力士市占率预计为53%,三星市占率38%、美光市占率9%。HBM在工艺上的变化主要在CoWoS和TSV。
下载链接:2024 数字科技前沿应用趋势:智能科技,跨界相变 2023年AIGC移动市场洞察报告 虚拟数字人研究报告:溯源、应用、发展(2024) AI服务器催化HBM需求爆发,核心工艺变化带来供给端增量(2024) 2024计算机行业策略:落地为王 2023年度全球十大技术关键词报告 多样性算力技术愿景白皮书 《AI算力芯片产业链及全景图》 1、AI算力产业链梳理(2023) 2、国产AI算力芯片全景图 芯片未来可期:数据中心、国产化浪潮和先进封装(精华)
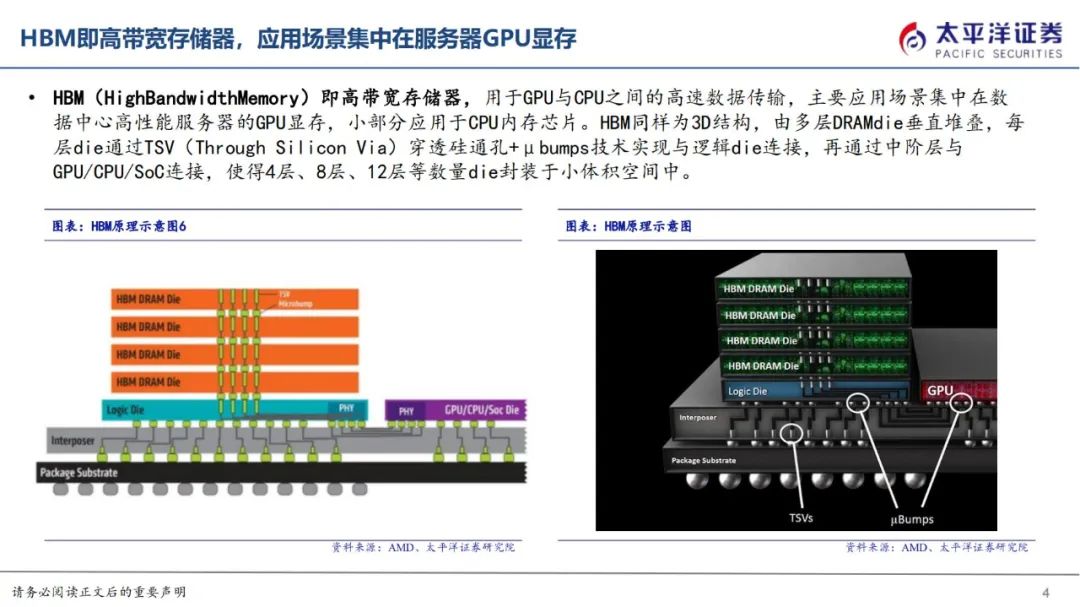
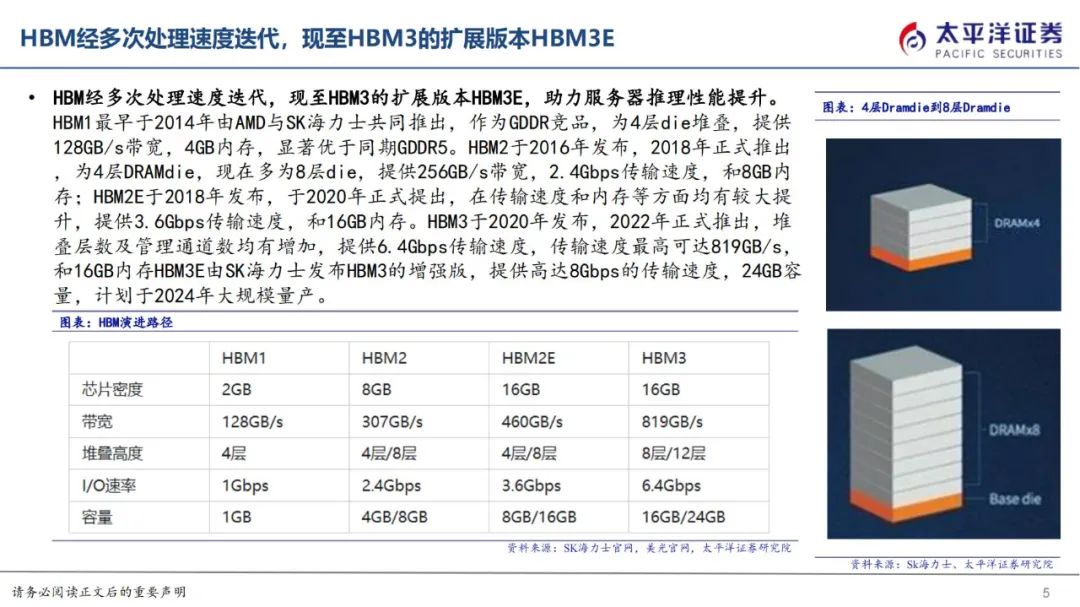
HBM1最早于2014年由AMD与SK海力士共同推出,作为GDDR竞品,为4层die堆叠,提供128GB/s带宽,4GB内存,显著优于同期GDDR5。
HBM2于2016年发布,2018年正式推出,为4层DRAMdie,现在多为8层die,提供256GB/s带宽,2.4Gbps传输速度,和8GB内存;HBM2E于2018年发布,于2020年正式提出,在传输速度和内存等方面均有较大提升,提供3.6Gbps传输速度,和16GB内存。HBM3于2020年发布,2022年正式推出,堆叠层数及管理通道数均有增加,提供6.4Gbps传输速度,传输速度最高可达819GB/s,和16GB内存HBM3E由SK海力士发布HBM3的增强版,提供高达8Gbps的传输速度,24GB容量,计划于2024年大规模量产。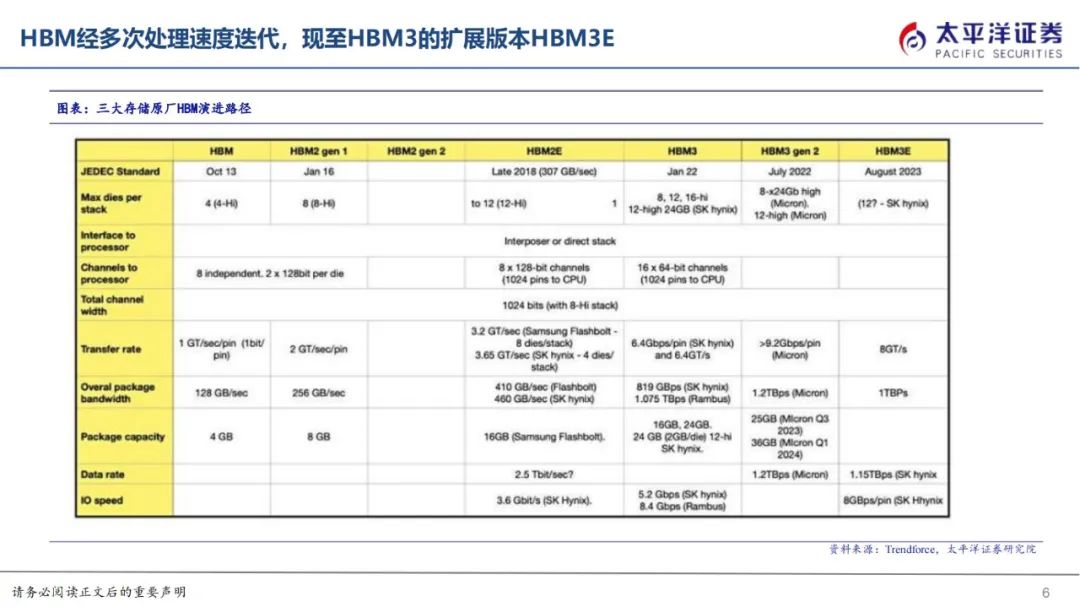
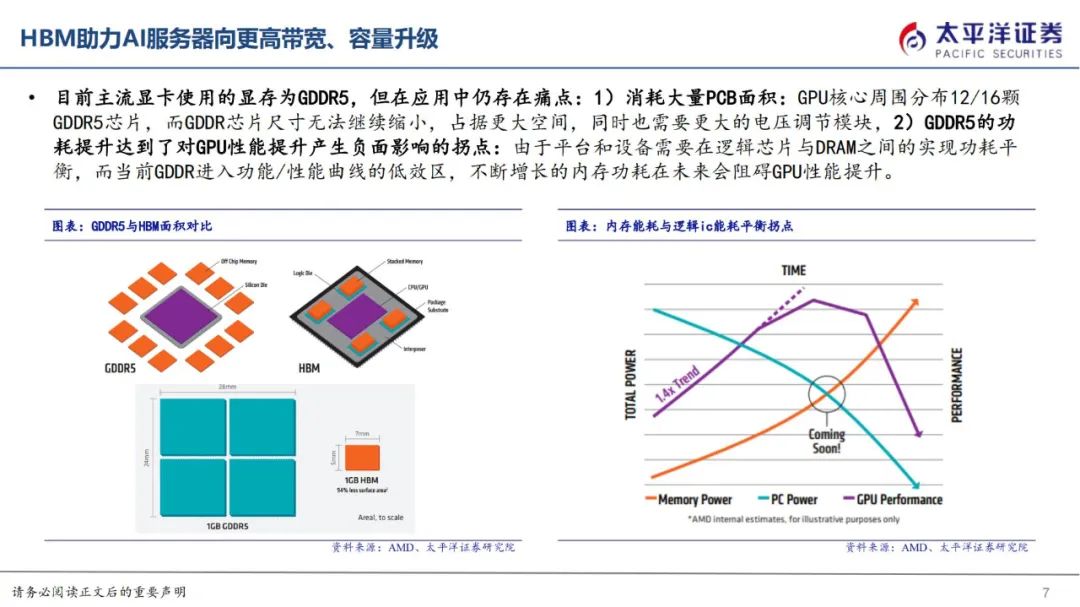

HBM因其高带宽、低功耗、小体积等特性,广泛应用于AI服务器场景中。HBM的应用主要集中在高性能服务器,最早落地于2016年的NVP100GPU(HBM2)中,后于2017年应用在V100(HBM2)、于2020年应用在A100(HBM2)、于2022年应用在H100(HBM2e/HBM3),最新一代HBM3e搭载于英伟达2023年发布的H200,为服务器提供更快速度及更高容量。
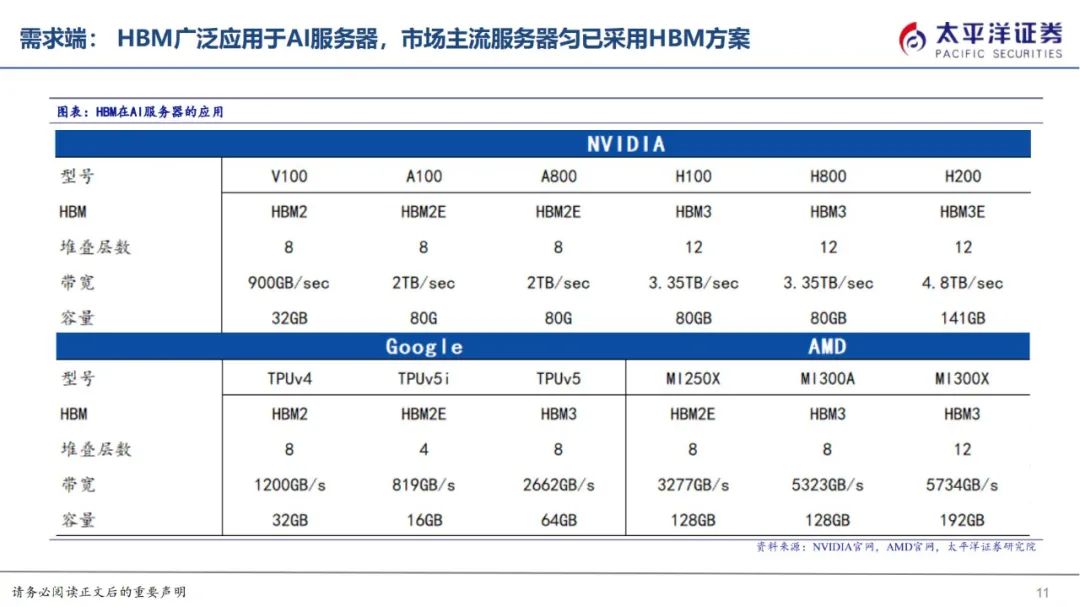
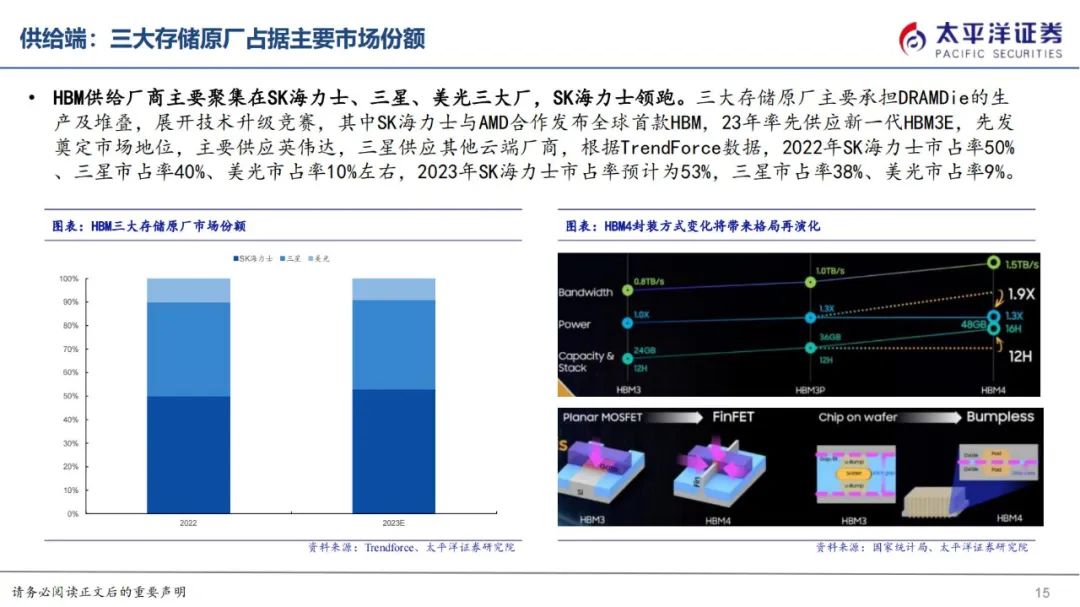
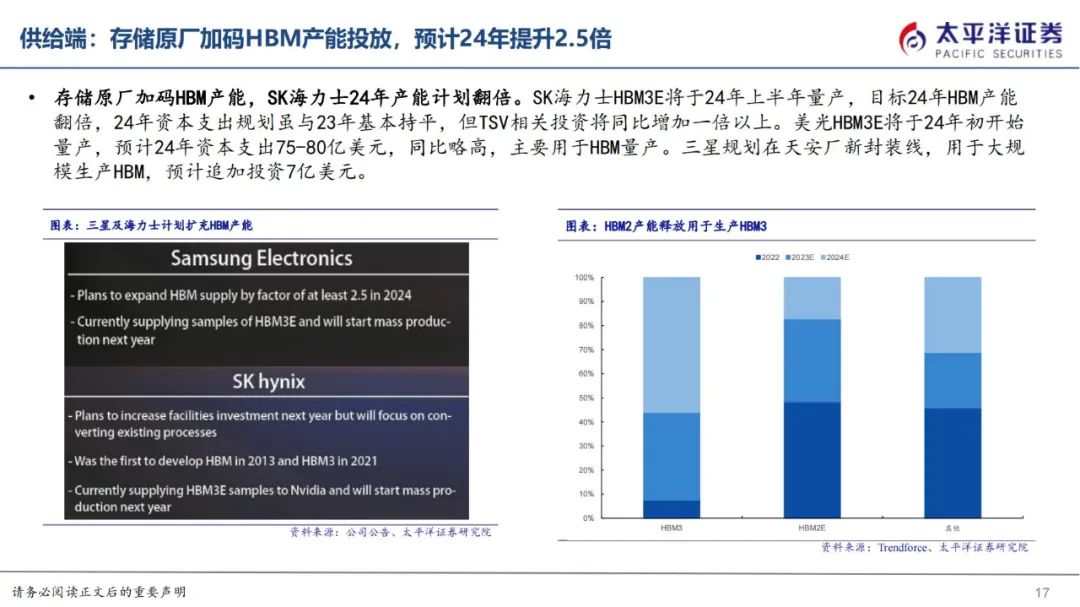
HBM供给厂商主要聚集在SK海力士、三星、美光三大厂,SK海力士领跑。三大存储原厂主要承担DRAMDie的生产及堆叠,展开技术升级竞赛,其中SK海力士与AMD合作发布全球首款HBM,23年率先供应新一代HBM3E,先发奠定市场地位,主要供应英伟达,三星供应其他云端厂商,根据TrendForce数据,2022年SK海力士市占率50%、三星市占率40%、美光市占率10%左右,2023年SK海力士市占率预计为53%,三星市占率38%、美光市占率9%。
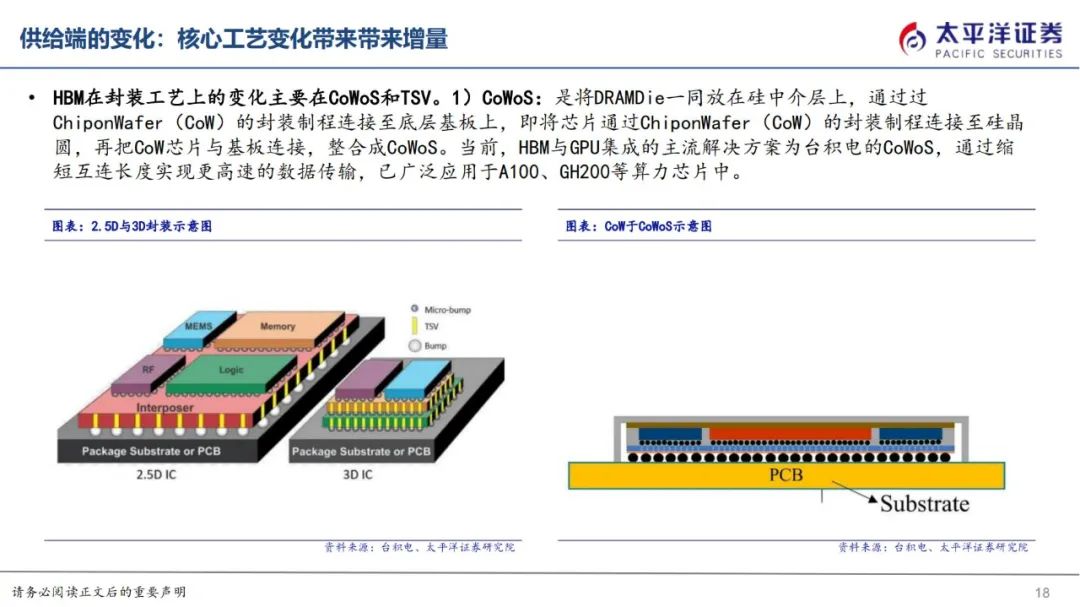
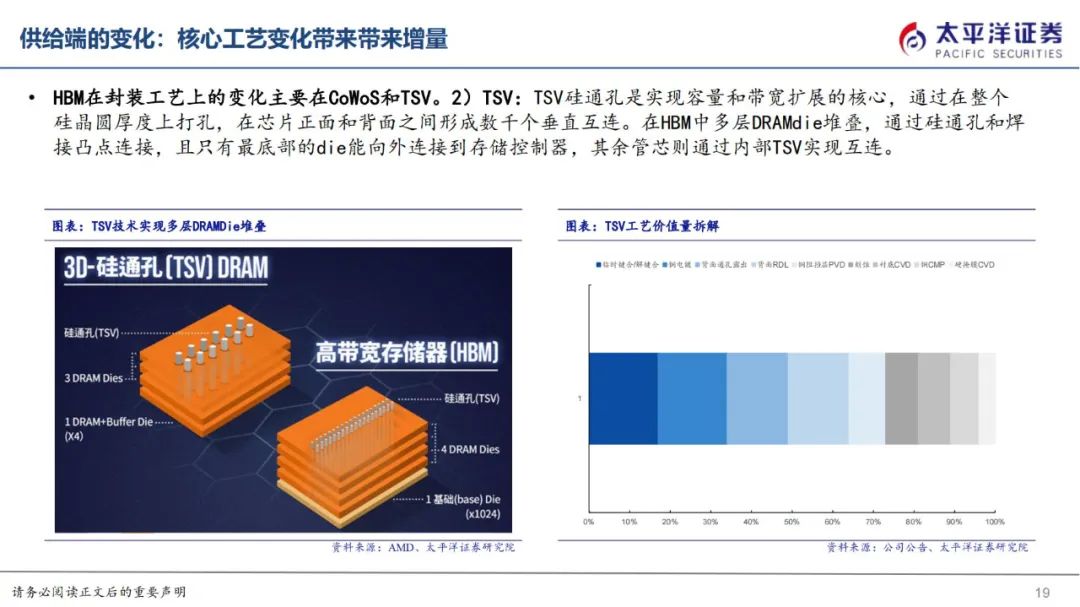
HBM在封装工艺上的变化主要在CoWoS和TSV。
1)CoWoS:是将DRAMDie一同放在硅中介层上,通过过ChiponWafer(CoW)的封装制程连接至底层基板上,即将芯片通过ChiponWafer(CoW)的封装制程连接至硅晶圆,再把CoW芯片与基板连接,整合成CoWoS。当前,HBM与GPU集成的主流解决方案为台积电的CoWoS,通过缩短互连长度实现更高速的数据传输,已广泛应用于A100、GH200等算力芯片中。
2)TSV:TSV硅通孔是实现容量和带宽扩展的核心,通过在整个硅晶圆厚度上打孔,在芯片正面和背面之间形成数千个垂直互连。在HBM中多层DRAMdie堆叠,通过硅通孔和焊接凸点连接,且只有最底部的die能向外连接到存储控制器,其余管芯则通过内部TSV实现互连。
相关阅读:- GPU分析:全球竞争格局与未来发展
- 2023年GPU显卡技术词条报告
- 英伟达GPU龙头稳固,国内逐步追赶(详解)
- GPU/CPU领域散热工艺的发展与路径演绎
- 探析ARM第五代GPU架构
- 新型GPU云桌面发展白皮书
- 十大国产GPU产品及规格概述
- GPU平台生态:英伟达CUDA和AMD ROCm对比分析
- GPU竞争壁垒:微架构和平台生态
- GPU微架构、性能指标、场景、生态链及竞争格局(2023)
- 大模型训练,绕不开GPU和英伟达
- Nvidia/AMD竞争:GPU架构创新和新兴领域前瞻探索
- 走进芯时代:AI算力GPU行业深度报告
- 独立GPU市场,AMD份额大跌?
- CPU渲染和GPU渲染优劣分析
- NVIDIA Hopper GPU:芯片三围、架构、成本和性能分析
- 国内GPU厂商及细分行业前景(2023)
- ChatGPT对GPU算力的需求测算与分析
- AMD RDNA2 GPU架构详解
- 算力竞赛,开启AI芯片、光模块和光芯片需求
- AI算力租赁行业深度研究(2023)
- 大模型算力:AI服务器行业(2023)
- 计算设备算力报告(2023年)
- UCIe封装与异构算力集成
- 算力技术未来发展路径概述(2023)
- AI算力研究框架:时势造英雄,谋定而后动(2023)
- 算力网络:在网计算(NACA)技术
- 一文理解“高广深”先进算力网络
- 联邦学习算力加速方案(2023)
- 中国AI服务器算力市场规模及空间测算(2023)
- 多样性算力:新一代超异构计算架构
- 大模型AI算力剧增,谁来扛国产GPU大旗?
- 超级芯片GH200发布,AI算力是H100两倍
- 中国绿色算力发展研究报告(2023年)
- 详解:算力网络基础知识(2023)
- AIGC算力全景与趋势报告(2023)
- AI科普报告(2023):算法、算力、数据和应用
- 国内外AI芯片、算力综合对比
- 华为算力编年史(2023)
- AI算力研究框架(2023)
- 大模型训练,英伟达Turing、Ampere和Hopper算力分析
- AI大语言模型原理、演进及算力测算
- 大算力模型,HBM、Chiplet和CPO等技术打破技术瓶颈
- 走进芯时代:AI算力GPU行业深度报告
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明: 本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。