
如何衡量AI/HPC算力的“FLOPS”?
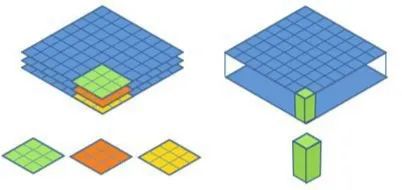

什么是FLOPS
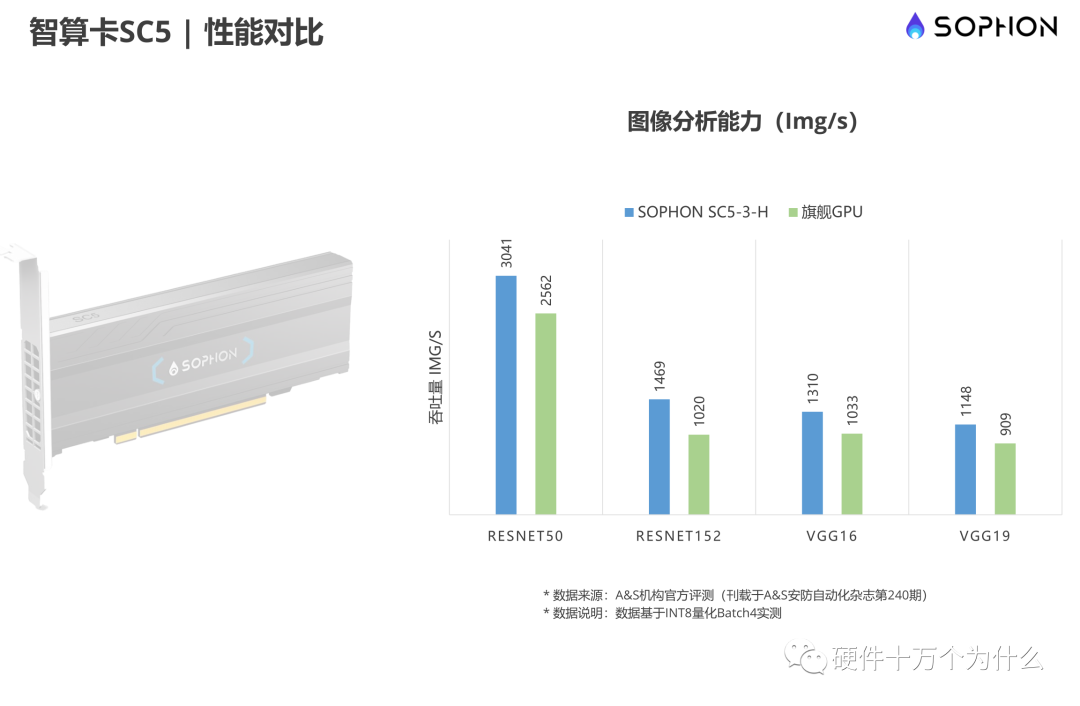
例如:算能公司的“基于SOPHON第三代智算芯片 BM1684”芯片。该款芯片FP32 精度算力也达到 2.2 TFlops,INT8算力可高达17.6Tops,在Winograd卷积加速下,INT8算力更提升至35.2 Tops,是一颗低功耗、高性能的SoC芯片。
BM1684还内置了张量计算模块TPU,该TPU模块包含64个NPU运算单元,每个NPU包括16个EU单元,总共有1024个EU运算单元。
1TFlops=1024GFlowps,即1T=1024G。各种FLOPS的含义:
1) 一个MFLOPS(megaFLOPS)等于每秒1百万(=10^6)次的浮点运算; 2) 一个GFLOPS(gigaFLOPS)等于每秒10亿(=10^9)次的浮点运算; 3) 一个TFLOPS(teraFLOPS)等于每秒1万亿(=10^12)次的浮点运算; 4) 一个PFLOPS(petaFLOPS)等于每秒1千亿(=10^15)次的浮点运算。
关于 Linpack
AI算力评估为什么不用 Linpack
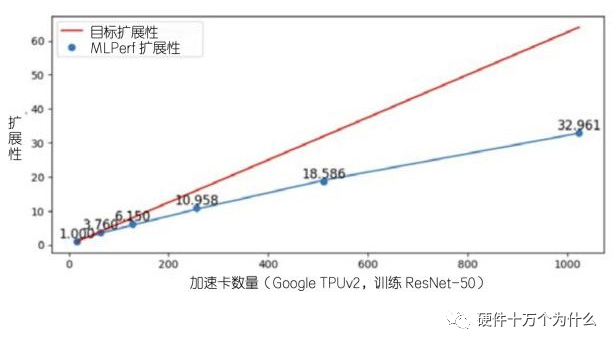
经典芯片的算力
GFLOPS
Intel Xeon 3.6 GHz: <1.8 GFLOPS
Intel Pentium 4 HT 3.6Ghz: 7 GFLOPS
Intel Core 2 Duo E4300 14 GFLOPS
Intel Core 2 Duo E8400 24 GFLOPS
AMD Phenom 9950: 29.05 GFLOPS
Intel Core 2 Quad Q8200: 37 GFLOPS
Intel Core 2 QX9770: 39.63 GFLOPS
AMD Phenom II x4 955: 42.13 GFlopS
Intel Core i7-965: 69.23 GFLOPS
Intel Core i7-980 XE : 107.6 GFLOPS
Intel Core i5-2500K @4.5GHz: 123.35 GFLOPS (w/AVX instruction set)
IBM POWER7: 264.96GFLOPS[2]
nVIDIA Geforce 8800 Ultra(G80-450 GPU):393.6 GFLOPS
nVIDIA Geforce GTX 280(G200-300 GPU):720 GFLOPS
AMD Radeon HD 3870(RV670 GPU):497 GFLOPS
AMD Radeon HD 4870(RV770 GPU):1008 GFlops
TFLOPS
nVIDIA Geforce GTX 580(GF110-375 GPU):2.37 TFLOPS
AMD Radeon HD 6990(R900 GPU):4.98 TFLOPS
nVIDA Geforce GTX 1070: 6.5 TFLOPS
nVIDA Geforce GTX 1080: 9 TFLOPS
nVIDA Geforce GTX 1080Ti: 10.8 TFLOPS
nIVIDIA Titan Xp : 12.1 TFLOPS
ASCI White:12.3TFLOPS
AMD Vega Frontier Edition : 13.1 TFLOPS
Earth Simulator: 35.61 TFLOPS
Blue Gene/L: 135.5 TFLOPS
中国曙光Dawning 5000A: 230 TFLOPS
PFLOPS
IBM Roadrunner:1.026 PFLOPS
Jaguar:1.75 PFLOPS
天河一号:2.566 PFLOPS
Folding@home运算平台:4.769 PFLOPS
BOINC运算平台:6.282 PFLOPS (持续增加中)
IBM Mira: 8.16 PFLOPS
京:10.51 PFLOPS
IBM Sequoia:16.32 PFLOPS
Cray Titan:17.59 PFLOPS
天河二号:33.86PFLOPS
神威·太湖之光:125PFLOPS
参考“2020年HPC市场总结和预测报告(附下载)”,2020年HPC市场总结和预测报告。美国在3大超算系统(Aurora、Frontier和EI Capitan)近两年投入预算均超过18亿美元。

Aurora:英特尔推迟推出7纳米的Ponte Vecchio GPU,计划在Aurora与英特尔Xeon CUP集成,算力>1EF。
Focus on Frontier (CORAL-2):美国第一个Exascale System (由于Aurora延期),第二代AI系统;
日本Fugaku超算系统在2020年6月TOP500榜单中位居榜首。基于Fujitsu A64 ARMv8.2处理器,无GPU加速,Linpack (HPL) 测试基准达 415.5 petaflops。
中国三个超算原型机(NUDT、Sugon和Sunway)在开发中,其中一个或多个原型可能被选择为充分生产。

欧洲EuroHPC项目于2018年启动,欧盟32个参与国开发欧盟范围内高性能计算系统,选择芬兰卡贾尼,西班牙巴塞罗那和意大利博洛尼亚,投资6.5亿欧元实施150,200Pflops系统,投资1.8亿欧元建设中规模HPC系统(~4Pflops)

此外,在2022-2023将从采购3个大型系统,至少有一个采用欧盟技术(特别是使用EPI处理器);大约在2027年部署首个混合高性能计算/量子基础设施(Post Exascale System)。
更多内容参考2021 HPC China大会因特尔方案资料(下)和2021 HPC China大会因特尔方案资料(上)
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
