编辑:好困 yaxin
【新智元导读】算力就是生产力,得算力者得天下。千亿级参数AI模型预示着算力大爆炸时代来临,不如织起一张「算力网」试试?
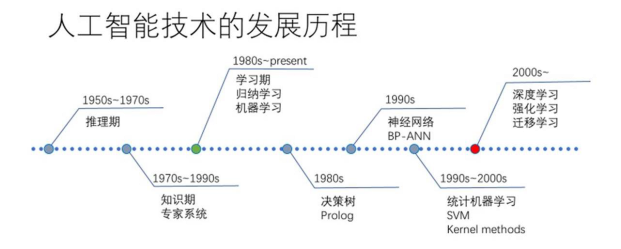
人工神经网络在上世纪80年代早已提出,却受制于有限的计算力历经数年寒冬。以深度学习计算模式为主人工智能算力需求呈指数级增长。从16年的AlphaGo,到17年的AlphaZero,再到18年的AlphaFold,人工智能演化发展的速度进一步加快。而2020年发布的GPT-3更是把人工智能的水平提到了一个新的高度。
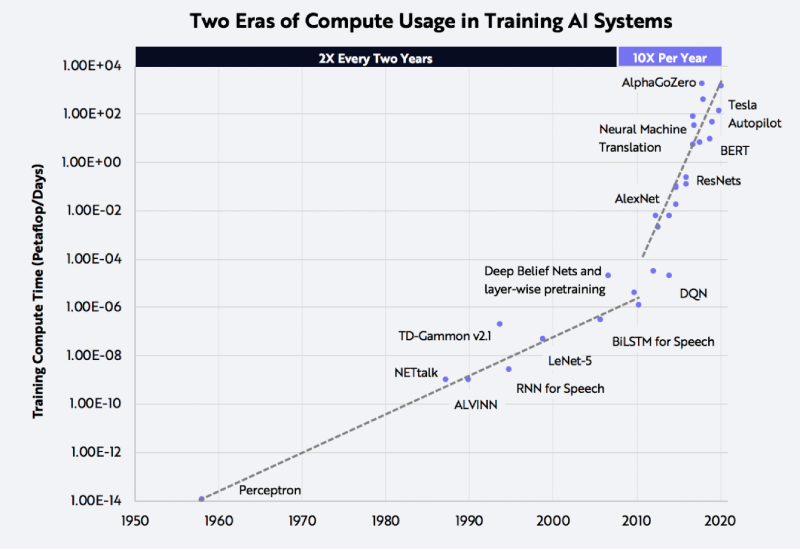
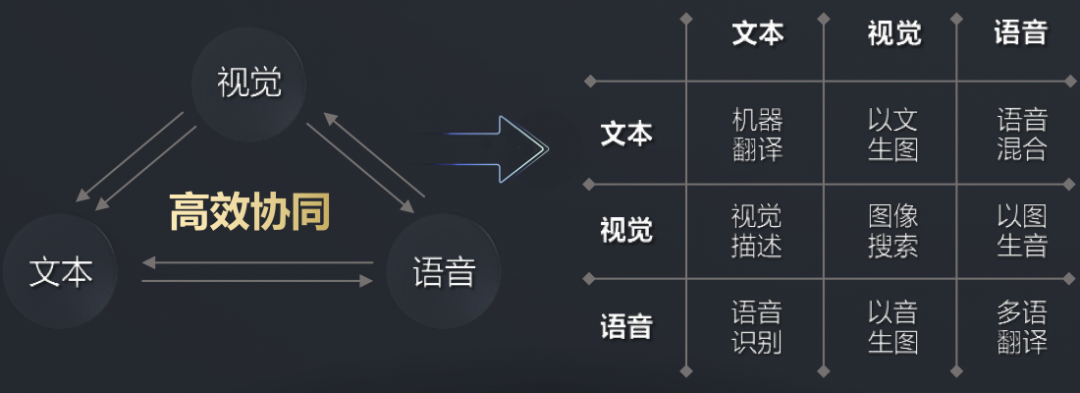
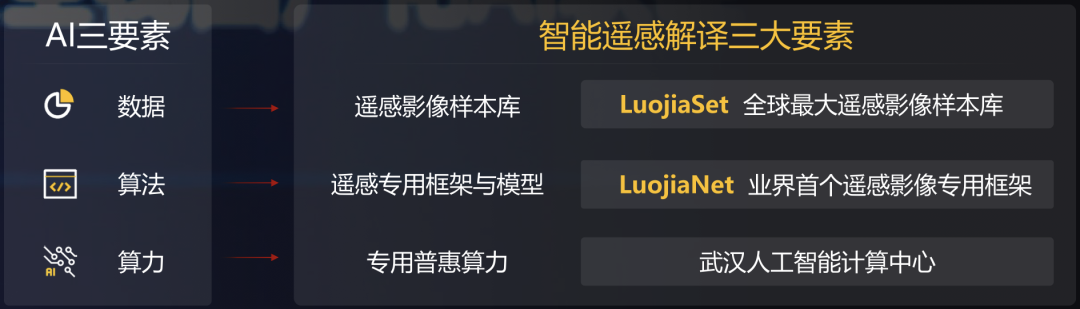
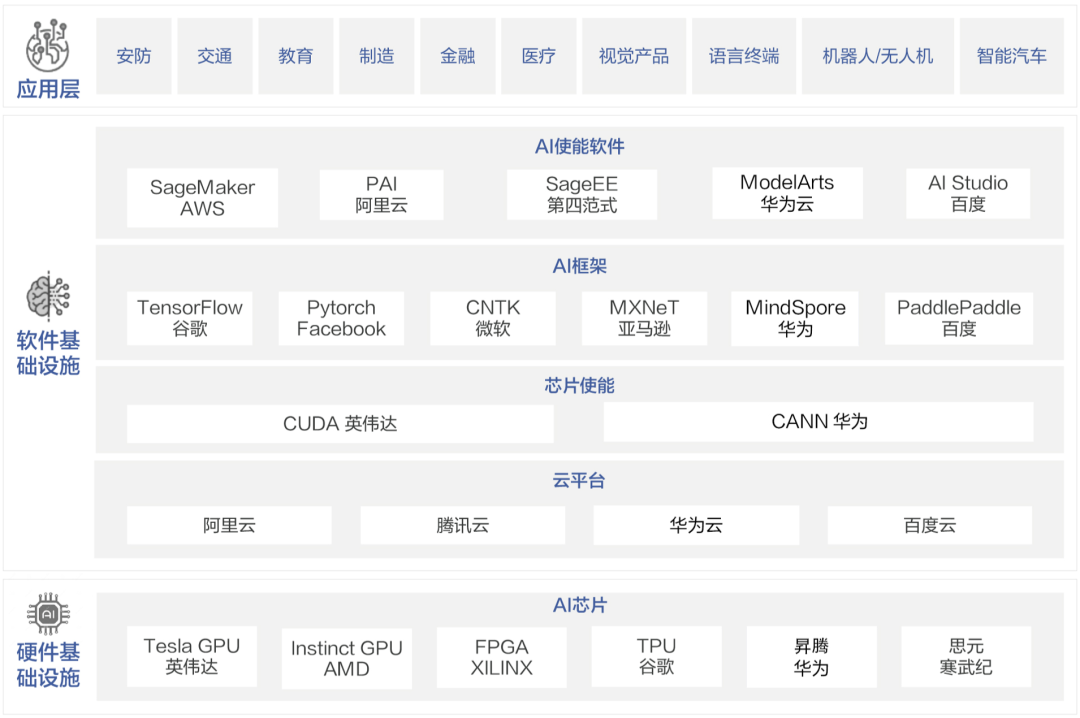
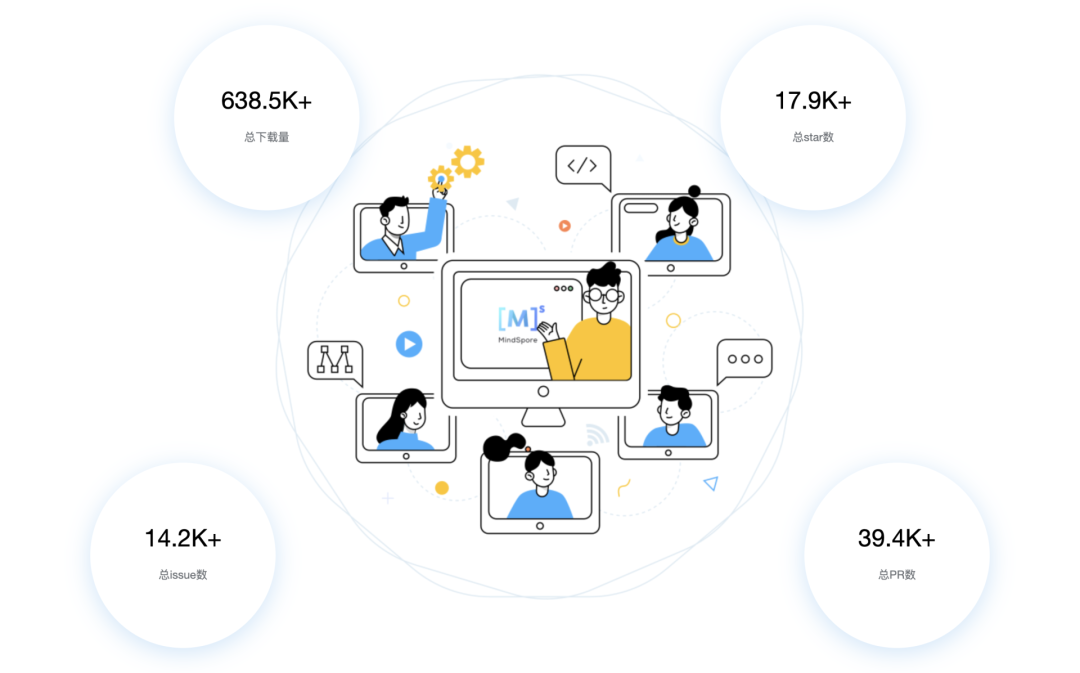
为了训练GPT-3,微软新建了一个搭载了1万张显卡,价值5亿美元的算力中心。模型在训练上则消耗了355个GPU年的算力,而成本超过460万美元。其成果是显而易见的,GPT-3不仅在NLP方面取得了惊人的成就。其衍生版,侧重于代码生成Codex,不仅仅是模仿以前见过的代码,而且还会分析文档中的字符串、注释、函数名称以及代码本身,从而生成新的匹配代码,包括之前调用的特定函数。此外,DALL·E作为另一个GPT-3的120亿参数衍生版本,它能创建绘画、照片、草图等等,基本上涵盖了所有可以用文字描述的东西。GP从11亿参数的GPT到150亿参数的GPT-2,再到1750亿参数的GPT-3。通过自动混合并行模式实现了在2048卡算力集群上的大规模分布式训练。在预训练阶段,模型学习了40TB中文文本数据,并通过行业数据的样本调优提升模型在场景中的应用性能。视觉方面则包含超过30亿参数,兼顾了图像判别与生成能力,从而能够同时满足底层图像处理与高层语义理解需求。模型在16个下游任务中大部分指标优于SOTA模型,其中零样本学习任务11个任务领先,单样本学习任务12个任务领先,小样本学习任务13个任务领先。现实中的网络数据,有90%以上是图像与视频,其中蕴含了更多的知识。而人类的信息获取、环境感知、知识学习与表达,都是采用跨模态的输入输出方式。为此,中科院自动化所推出了全球首个三模态大模型:紫东.太初。其兼具跨模态理解和生成能力,可以同时应对文本、视觉、语音三个方向的问题。与单模态和图文两模态相比,其采用一个大模型就可以灵活支撑图-文-音全场景AI应用。具有了在无监督情况下多任务联合学习、并快速迁移到不同领域数据的强大能力。此外,紫东.太初还获得了MM2021视频描述国际竞赛的第一名,ICCV2021视频理解国际竞赛第一名。在图文跨模态理解与生成方面的性能领先SOTA,而在视频理解与描述上甚至可以称得上世界第一的水平。与此同时,在1960到2010年间,人工智能的计算复杂度每两年翻一番;在2010到2020年间,人工智能的计算复杂度每年猛增10倍。那么该如何面对如此之大的模型和如此之复杂的计算呢?毕竟,人工智能发展的三要素:数据、算法和算力中,无论是数据还是算法,都离不开算力的支撑。随着人工智能模型的逐渐成熟,以及各个行业的智能化转型,越来越多的企业都体验到了AI带来的便捷。AI的应用必定会涉及到算力的需求,然而让每个企业都去搭建「人工智能计算中心」显然是不现实的。因此,建造标准化且自主可控的「人工智能计算中心」的需求也就迫在眉睫了。除了需求的牵引之外,再加上政策扶持,人工智能计算中心「落地潮」也在深圳、武汉、西安等地被快速掀起。作为全国第三个人工智能计算中心,它的应用场景更为广泛——自动驾驶、智慧医疗、智慧城市、智慧交通、智慧矿山等多种场景。西安电子科技大学人工智能研究院院长焦李成院士被聘为该人工智能计算中心专家。他并表示:未来人工智能计算中心的上线,能够加快实现人工智能对经济社会发展的带动和支撑作用,能够更快形成国家新一代人工智能试验区的西安方案。据悉,西安未来人工智能计算中心算力规模一期在300P FLOPS FP16,具备每秒30亿亿次半精度浮点计算的能力。相当于24小时内能处理30亿张图像或3000万人DNA,或300万小时语音,或10年自动驾驶数据。此外,西安未来人工智能计算中心上线之初,便签约了众多项目。如西安电子科技大学遥感项目、西北工业大学语音大模型项目、陕西师范大学「MindSpore研究室」等。而早在5月底已经投入运营的武汉人工智能计算中心,则提供了高达100P的算力,相当于每秒10亿亿次的计算速度。仅在试运行期间,就有联影、兴图新科等企业发出了算力申请,而人工智能计算中心也帮助企业完成了图像识别、语音识别等场景的应用。在科研创新方面,依托武汉人工智能计算中心的算力,武汉大学打造了全球首个遥感专用框架武汉.LuojiaNet。LuojiaNet针对「大幅面、多通道」遥感影像,在整图分析和数据集极简读取处理等方面实现了重大突破。在产业方面,倍特威视已经开发了170多种算法,可以应用在工地、水利、农业等多种复杂的环境。通过将模型迭代训练任务迁移到武汉人工智能计算中心,在算法的迭代速度上比独立部署训练服务器提升10倍。目前,武汉人工智能计算中心已为40家企业、4家高校与科研院所提供算力和产业服务,而这些仅仅是一个开始。往大了说是让人工智能产业能有进一步的发展,往小了说是让大家能够更好地体验到人工智能带来的便利,这些都离不开人工智能计算中心的算力。那么再具体一点,又是什么给这些「人工智能计算中心」提供这些算力的?还是回到最初的模型上,这其中主要涉及到的有三个大类:图像处理,决策和自然语言处理。那么在复杂模型的训练过程中,需对上千亿个浮点参数进行微调数十万步,需要精细的浮点表达能力。因此,人工智能计算中心在「训练」模型阶段,就需要极高的计算性能和较高的精度,需要能处理海量的数据,以便完成各种各样的学习任务。而在「推理」阶段,则是利用训练好的模型,使用新数据推理出各种结论。也就是借助现有神经网络模型进行运算,利用新的输入数据来一次性获得正确结论的过程。推理相对来说对性能的要求并不高,对精度要求也要更低,在特定的场景下,对通用性要求也低,能完成特定任务即可。但因为推理的结果直接提供给终端用户,所以更关注用户体验方面的优化。这也就意味着人工智能计算中心需要具有全栈性这个特点,覆盖到各种不同的算力需求。当实现了从建造到维护,再到日常运营这样的「一站式服务」,才能让大家把人工智能计算中心真正的用起来。然而,中国科学技术信息研究所在《人工智能计算中心发展白皮书》里指出,目前我国在人工智能计算中心的发展上遇到的一个重要的问题是:不管是作为算力的AI芯片,还是实现算法的模块化封装的AI开发框架,95%以上都被外国的公司所垄断。而这其中的AI开发框架,在人工智能领域是相当于一个操作系统的存在。AI开发框架是所有算法模型的开发基础,其中有90%的人工智能应用开发是在AI框架上进行的。因此,开发一个自主可控的AI框架在这个处处都有可能被「卡脖子」的领域就显得尤为重要了。以MindSpore(昇思)来说,作为一个自研的AI框架,已经在2020年3月全面开源。MindSpore(昇思)提供了一个统一的API,为全场景Al的模型开发、模型运行、模型部署提供端到端能力。MindSpore(昇思)可以支持数据并行、模型并行和混合并行训练,具有很强的灵活性。而且还有「自动并行」能力,它通过在庞大的策略空间中进行高效搜索来找到一种快速的并行策略。除了支持模型跨平台免转换以外,MindSpore(昇思)还可以让并行代码数量下降80%,调优时间降低60%。此外,它最重要的特点就是具备安全可信、高效执行、一次开发多次部署的能力。越来越多的企业和开发者开始采用MindSpore(昇思),开源社区累计下载量超过60万,有超过百家高校选择昇思进行教学。人工智能计算中心具有了训练、推理能力以及供AI开发的平台,自然也就有了能够向外输出的强大算力了。那么问题又来了,建设这么一堆人工智能计算中心就够了么?
其实就像是电网和天然气网,算力对于有些地方来说是完全不够用的,而对于有的地方则是空有一手的「算力」却无处使。简单来说,兴建人工智能计算中心之后会面临三点问题:不同区域AI算力使用存在波峰波谷,各地独立的人工智能计算中心无法实现跨域的动态调配;
全国人工智能发展不均衡,不同区域有各自优势,各地独立的人工智能计算中心无法实现跨区域的联合科研和应用创新、资源互补;
各地独立的人工智能计算中心产生的AI模型、数据,难以实现全国范围内顺畅流动、交易,以产生更大的价值。
那么,既然有「西气东输」和「西电东送」的成功经验,为何不把「算力」也连点成线,编织成一个人工智能算力网络呢?
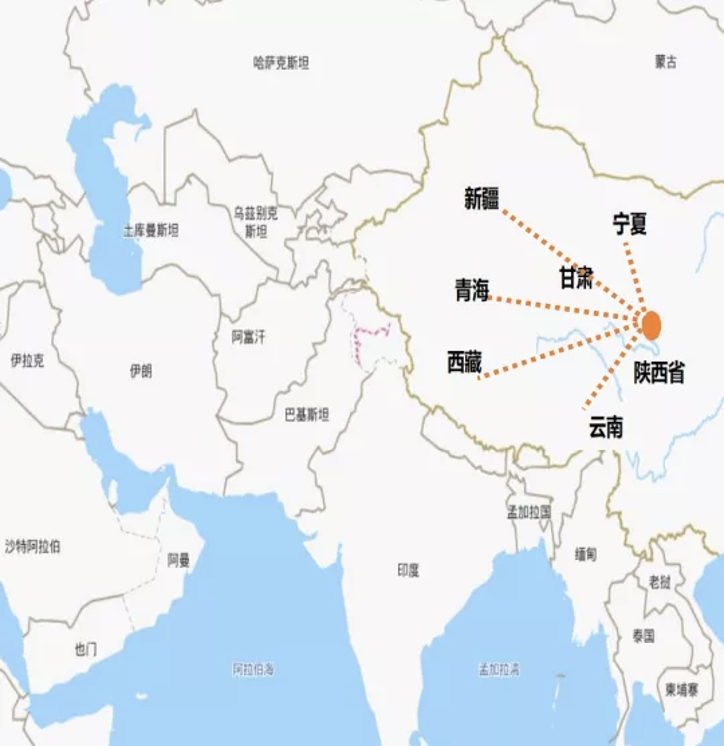
人工智能算力网络可以将各地分布的人工智能计算中心节点连接起来,动态实时感知算力资源状态。进而实现统筹分配和调度计算任务,构成全国范围内感知、分配、调度人工智能算力的网络,在此基础上汇聚和共享算力、数据、算法资源。例如,在西安建设的未来人工智能计算中心可以辐射宁夏、甘肃、新疆、青海、云南五省,从而推动西部整体的人工智能产业发展。那么具体来说,构建人工智能算力网络最终要实现的是「一网络,三汇聚」。网络:将人工智能计算中心的节点通过专线连接起来形成人工智能算力网络。算力汇聚:连接不同节点的高速网络,实现跨节点之间的算力合理调度,资源弹性分配,从而提升各个人工智能计算中心的利用率,实现对于整体能耗的节省,后续可支持跨节点分布学习,为大模型的研究提供超级算力。数据汇聚:政府和企业共同推进人工智能领域的公共数据开放,基于人工智能计算中心汇聚高质量的开源开放的人工智能数据集,促进算法开发和行业落地。生态汇聚:采用节点互联标准、应用接口标准,实现网络内大模型能力开放与应用创新成果共享,强化跨区域科研和产业协作。各地算力中心就像大脑中数亿个突触,人工智能算力网络正如神经网络。如此看来,算力网络的重要意义之一便是通过汇聚大数据+大算力,使能了大模型和重大科研创新,孵化新应用。最终打造一张覆盖全国的算力网络,实现算力汇聚、生态汇聚、数据汇聚,进而达到各产业共融共生。
参考资料:
http://gov.cnwest.com/jczw/a/2021/09/09/19944392.html
https://mp.weixin.qq.com/s/6oX0FdnIeyWGX5iXlmauew
https://mp.weixin.qq.com/s/M2oN3-MdaffnpiygrkBg3g
https://mp.weixin.qq.com/s/VQnPpyFprfFeYCBm_wE0wg
https://www.bilibili.com/read/cv12369433
https://www.istic.ac.cn/isticcms/html/1/istic-ai/result4.html
https://www.mindspore.cn/