
AI算力的阿喀琉斯之踵:内存墙
作者 | Amir Gholami
翻译与编辑 | OneFlow社区
这篇文章是我(Amir Gholami), Zhewei Yao,Sehoon Kim,Michael W. Mahoney 和 Kurt Keutzer 等人共同协作完成的。本文中用到的数据可以参考链接https://github.com/amirgholami/ai_and_memory_wall
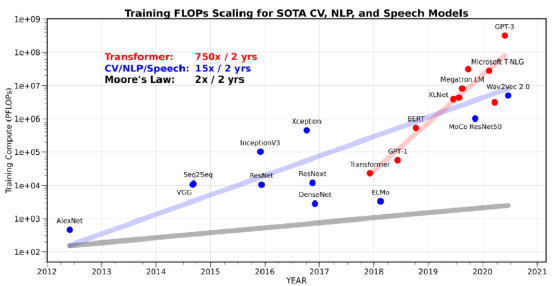
https://github.com/amirgholami/ai_and_memory_wall/blob/main/imgs/pdfs/ai_and_compute.pdf
如图表 1 所示,最近几年,计算机视觉(CV),自然语言处理(NLP)和语音识别领域最新模型的训练运算量,以大约每两年翻15倍数的速度在增长。而 Transformer 类的模型运算量的增长则更为夸张,约为每两年翻 750 倍。这种接近指数增长的趋势驱动了 AI 硬件的研发,这些 AI 硬件更专注于提高硬件的峰值算力,但是通常以简化或者删除其他部分(例如内存的分层架构)为代价。
然而,在应付最新 AI 模型的训练时,这些设计上的趋势已经显得捉襟见肘,特别是对于 NLP 和 推荐系统相关的模型:有通信带宽瓶颈。事实上,芯片内部、芯片间还有 AI 硬件之间的通信,都已成为不少 AI 应用的瓶颈。特别是最近大火的 Transformer 类模型,模型大小平均每两年翻240倍(如图表2所示)。类似的,大规模的推荐系统模型,模型大小已经达到了 O(10) TB 的级别了。与之相比,AI 硬件上的内存大小仅仅是以每两年翻2倍的速率在增长。
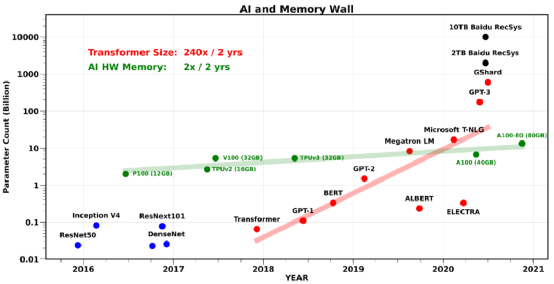
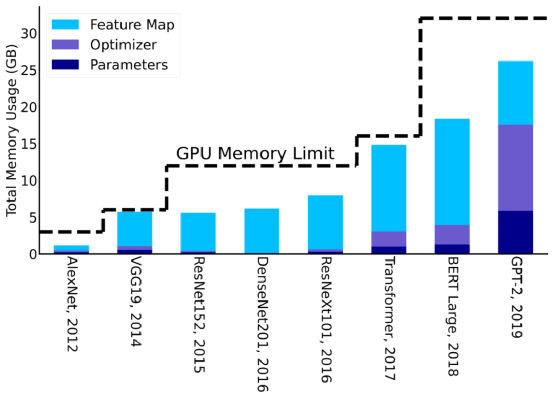
值得注意的是,训练 AI 模型时候所需要的内存一般比模型参数量还要多几倍。这是因为训练时候需要保存中间层的输出激活值,通常需要增加3到4倍的内存占用。图表3中展示了最新的 AI 模型训练时候,内存占用大小逐年的增长变化趋势。从中能清楚地看到,神经网络模型的设计是如何受 AI 硬件内存大小影响的。
这些挑战也就是通常所说的 “内存墙” 问题。内存墙问题不仅与内存容量大小相关,也包括内存的传输带宽。这涉及到多个级别的内存数据传输。例如,在计算逻辑单元和片上内存之间,或在计算逻辑单元和主存之间,或跨不同插槽上的不同处理器之间的数据传输。上述所有情况中,容量和数据传输的速度都大大落后于硬件的计算能力。
大家可能会想到,是否可以尝试采用分布式的策略将训练扩展到多个 AI 硬件(GPU)上,从而突破于单个硬件内存容量和带宽的限制。然而这么做也会遇到内存墙的问题:AI 硬件之间会遇到通信瓶颈,甚至比片上数据搬运更慢、效率更低。和单设备的内存墙问题类似,扩展 AI 硬件之间的网络带宽的技术难题同样还未被攻破。如图表4所示,其中展示了在过去20年中,硬件的峰值计算能力增加了90,000倍,但是内存/硬件互连带宽却只是提高了30倍。而要增加内存和硬件互连带宽[1],需要克服非常大的困难。因此,分布式策略的横向扩展仅在通信量和数据传输量很少的情况下,才适合解决计算密集型问题。
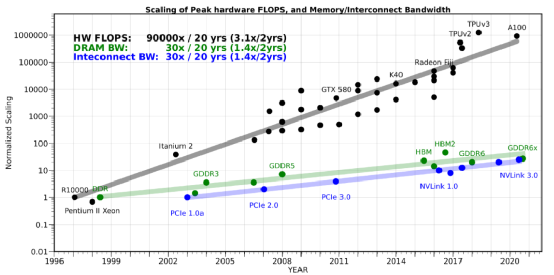
https://github.com/amirgholami/ai_and_memory_wall/blob/main/imgs/pdfs/hw_scaling.pdf
有希望打破内存墙的解决方案
“指数增长不可持续”,即使对于巨头公司来说,以每2年240倍的速度持续指数增长也是不可能的。再加上算力和带宽能力之间的差距越来越大,训练更大的模型的成本将以指数级增长,训练更大模型将更具有挑战性。
为了继续创新和 “打破内存墙”,我们需要重新思考人工智能模型的设计。这里有几个要点:
首先,当前人工智能模型的设计方法大多是临时的,或者仅依赖非常简单的放大规则。例如,最近的大型 Transformer 模型大多是原始 BERT 模型[22]的缩放版本,二者基本架构几乎一样。
其次,我们需要设计更有效的数据方法来训练 AI 模型。目前的网络训练非常低效,需要大量的训练数据和数十万次的迭代。有些人也指出,这种训练方式,不同于人类大脑的学习方式,人类学习某个概念或分类,往往只需要很少的学习例子。
第三,现有的优化和训练方法需要大量的超参调整(如学习率、动量等) ,在设置好参数从而训练成功前,往往需要数以百计次的试错。这样看来,图1中只是展示了训练成本的下限,实际成本通常要高得多。
第四,SOTA 类网络规模巨大,使得光部署它们就极具挑战。这不仅限于 GPT-3 等模型。事实上,部署大型推荐系统(类似于 Transformers ,但 embedding 更大且后接的 MLP 层更少)是巨头公司所面临的主要挑战。最后,AI 硬件的设计主要集中在提高算力上,而较少关注改善内存。这让训练大模型、探索新模型都变得困难。例如图神经网络(GNN)就常常受限于带宽,不能有效地利用当前硬件(的算力)。
以上几点都是机器学习中的重要基础问题。在这里,我们简要讨论最近针对后三点(包括我们自己)的研究。
高效的训练算法
训练模型时的一大困难是需要用暴力探索的方法调整超参。寻找学习率以及其配套的退火策略,模型收敛所需的迭代次数等等,这给训练 SOTA 模型带来了不少额外开销(overhead)。这些问题大多是由于训练中使用的是一阶 SGD 优化方法。虽然 SGD 超参容易实现,却没有稳健的方法去调试超参,特别是对于那些还没得到正确超参集合的新模型,调参就更加困难了。一个可能的解决方法是使用二阶 SGD 优化方法,如我们最近发表的 ADAHESSIAN 方法[4]。这类方法在超参调优时往往更加稳健,从而达到可以达到 SOTA。但是,这种方法也有亟待解决的问题:目前占用的内存是原来的3-4倍。微软关于 Zero 论文中介绍了一个很有前景的工作:可以通过删除/切分冗余优化器状态参数[21, 3],在保持内存消耗量不变的前提下,训练8倍大的模型。如果这些高阶方法的引入的 overhead 问题可以得到解决,那么可以显著降低训练大型模型的总成本。
另一种很有前景的方法是提高优化算法的数据本地性(data locality)并减少内存占用,但是这会增加计算量。一个简单的例子是,在前向 forward 期间,不保存所有的激活参数(activations),而只保存它的子集,这样可以减少图3所示的用于特征映射内存占用。未保存的激活参数可以在需要的时候进行重计算,尽管这个方法会增加计算量,但只增加 20% 的计算量,可以减少高达5倍 [2]的内存占用。
还有另一个重要的解决方案是设计足够稳健的、适用于低精度训练的优化算法。事实上,AI 硬件的主要突破之一是支持了半精度(FP16)运算,用以替代单精度运算[5,6]。这使得算力提高了10倍以上。接下来的挑战是,如何在保证准确度不降低的前提下,进一步将精度从半精度降低到 INT8。
高效部署
当部署最新的 SOTA 模型,如 GPT-3 或大型推荐系统模型时,为了推理,常常需要做分布式部署,因此相当具有挑战性。可能的解决方案是,通过降低精度(如量化)或移除冗余参数(如剪枝)来压缩推理模型。量化方法,既可以用于训练,也可以用于推理。虽然量化用于推理是可能做到超低精度级别的,但是用于训练时,想要将精度做到远低于 FP16 的级别是非常困难的。目前,在最小限度影响准确率的前提下,已经可以相对容易地将推理精度量化至 INT4 级别,这使得模型所占空间及延时,减少至原有的 1/8。然而,如何将精度量化至低于 INT4 级别,是一个颇具挑战的问题,也是当前研究的热门领域。
除量化外,剪枝掉模型中冗余的参数也是高效部署的一种办法。在最小限度影响准确率的前提下,目前已经可以使用基于 structured sparsity 的方法剪枝掉高达 30% 的神经元,使用基于 non-structured sparsity 的方法可以剪枝掉高达 80% 的神经元。然而,如果要进一步提高剪枝的比率,则非常困难,常常会导致准确度下降非常多,这该如何解决,还是一个开放问题。
AI 硬件设计的再思考
如何同时提高硬件带宽和算力是一个极具挑战的基本问题,不过,通过牺牲算力来谋求更好的“算力/带宽”平衡点是可行的。事实上,CPU 架构包含了充分优化后的缓存架构,因此在内存带宽受限类问题(如大型推荐系统)上,CPU 的性能表现要明显优于 GPU。然而,当前 CPU 的主要问题是,它的计算能力(FLOPS)与 GPU 和 TPU 这类 AI 芯片相比,要弱一个数量级。个中原因之一,就是 AI 芯片为追求算力最大化,往往在设计时,就考虑移除了一些组件(如缓存层级)来增加更多的计算单元。我们有理由想象,可以有一种架构,处于以上两种极端架构之间:它将使用更高效的缓存,更重要的是,使用更高容量的 DRAM(设计 DRAM 层次结构,不同层次拥有不同带宽)。后者对于解决分布式内存通信瓶颈将非常有帮助。
结论
目前 NLP 中的 SOTA Transformer 类模型的算力需求,以每两年750倍的速率增长,模型参数数量则以每两年240倍的速率增长。相比之下,硬件算力峰值的增长速率为每两年3.1倍。DRAM 还有硬件互连带宽增长速率则都为每两年1.4倍,已经逐渐被需求甩在身后。深入思考这些数字,过去20年内硬件算力峰值增长了90000倍,但是DRAM/硬件互连带宽只增长了30倍。在这个趋势下,数据传输,特别是芯片内或者芯片间的数据传输会迅速成为训练大规模 AI 模型的瓶颈。所以我们需要重新思考 AI 模型的训练,部署以及模型本身,还要思考,如何在这个越来越有挑战性的内存墙下去设计人工智能硬件。
感谢 Suresh Krishna 跟 Aniruddha Nrusimha 给出的非常有价值的回答。
[1] Patterson DA. Latency lags bandwidth. Communications of the ACM. 2004 Oct 1;47(10):71–5.
[2] Jain P, Jain A, Nrusimha A, Gholami A, Abbeel P, Keutzer K, Stoica I, Gonzalez JE. Checkmate: Breaking the memory wall with optimal tensor rematerialization. arXiv preprint arXiv:1910.02653. 2019 Oct 7.
[3] Rajbhandari S, Rasley J, Ruwase O, He Y. Zero: Memory optimizations toward training trillion parameter models. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis 2020 Nov 9 (pp. 1–16). IEEE.
[4] Yao Z, Gholami A, Shen S, Keutzer K, Mahoney MW. ADAHESSIAN: An adaptive second order optimizer for machine learning. arXiv preprint arXiv:2006.00719. 2020 Jun 1.
[5] Ginsburg B, Nikolaev S, Kiswani A, Wu H, Gholaminejad A, Kierat S, Houston M, Fit-Florea A, inventors; Nvidia Corp, assignee. Tensor processing using low precision format. United States patent application US 15/624,577. 2017 Dec 28.
[6] Micikevicius P, Narang S, Alben J, Diamos G, Elsen E, Garcia D, Ginsburg B, Houston M, Kuchaiev O, Venkatesh G, Wu H. Mixed precision training. arXiv preprint arXiv:1710.03740. 2017 Oct 10.
[7] Yao Z, Dong Z, Zheng Z, Gholami A, Yu J, Tan E, Wang L, Huang Q, Wang Y, Mahoney MW, Keutzer K. HAWQV3: Dyadic Neural Network Quantization. arXiv preprint arXiv:2011.10680. 2020 Nov 20.
[8] Gholami A, Kim S, Yao Z, Dong Z, Mahoney M, Keutzer K, A Survey of Quantization Methods for Efficient Neural Network Inference, arxiv preprint, arxiv:arXiv:2103.13630, 2021.
[9] Gale T, Elsen E, Hooker S. The state of sparsity in deep neural networks. arXiv preprint arXiv:1902.09574. 2019 Feb 25.
[10] Hoefler T, Alistarh D, Ben-Nun T, Dryden N, Peste A. Sparsity in Deep Learning: Pruning and growth for efficient inference and training in neural networks. arXiv preprint arXiv:2102.00554. 2021 Jan 31.
[11] Iandola FN, Han S, Moskewicz MW, Ashraf K, Dally WJ, Keutzer K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv preprint arXiv:1602.07360. 2016 Feb 24.
[12] Gholami A, Kwon K, Wu B, Tai Z, Yue X, Jin P, Zhao S, Keutzer K. Squeezenext: Hardware-aware neural network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops 2018 (pp. 1638–1647).
[13] Wu B, Iandola F, Jin PH, Keutzer K. Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops 2017 (pp. 129–137).
[14] Shaw A, Hunter D, Landola F, Sidhu S. SqueezeNAS: Fast neural architecture search for faster semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops 2019 (pp. 0–0).
[15] Wu B, Wan A, Yue X, Keutzer K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In2018 IEEE International Conference on Robotics and Automation (ICRA) 2018 May 21 (pp. 1887–1893). IEEE.
[16] Iandola FN, Shaw AE, Krishna R, Keutzer KW. SqueezeBERT: What can computer vision teach NLP about efficient neural networks?. arXiv preprint arXiv:2006.11316. 2020 Jun 19.
[17] Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, Andreetto M, Adam H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861. 2017 Apr 17.
[18] Krishna S, Krishna R. Accelerating Recommender Systems via Hardware” scale-in”. arXiv preprint arXiv:2009.05230. 2020 Sep 11.
[19] Kim S, Gholami A, Yao Z, Mahoney MW, Keutzer K. I-BERT: Integer-only BERT Quantization. arXiv preprint arXiv:2101.01321. 2021 Jan.
[20] Patrick Judd, Senior Deep Learning Architect, Integer Quantization for DNN Acceleration, Nvidia, GTC 2020.
[21] Bottou L, Curtis FE, Nocedal J. Optimization methods for large-scale machine learning. Siam Review. 2018;60(2):223–311.
[22] Devlin J, Chang MW, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. 2018 Oct 11.
[23] Naumov M, Mudigere D, Shi HJ, Huang J, Sundaraman N, Park J, Wang X, Gupta U, Wu CJ, Azzolini AG, Dzhulgakov D. Deep learning recommendation model for personalization and recommendation systems. arXiv preprint arXiv:1906.00091. 2019 May 31.
[24] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE. 1998 Nov;86(11):2278–324.
本文由oneflow社区团队翻译编辑,并已获得作者授权。
原文链接:https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8
作者简介: Amir Gholami is a senior research fellow atICSI and Berkeley AI Research (BAIR). He received his PhD from UT Austin,working on large scale 3D image segmentation, a research topic which receivedUT Austin’s best doctoral dissertation award in 2018. He is a Melosh Medalfinalist, the recipient of best student paper award in SC'17, Gold Medal in theACM Student Research Competition, as well as best student paper finalist inSC’14. He was also part of the Nvidia team that for the first time made lowprecision neural network training possible (FP16), enabling more than 10xincrease in compute power through tensor cores. That technology has been widelyadopted in GPUs today. Amir's current research focuses on efficient AI at theEdge, and scalable training of Neural Network models.
Amir Gholami is a senior research fellow atICSI and Berkeley AI Research (BAIR). He received his PhD from UT Austin,working on large scale 3D image segmentation, a research topic which receivedUT Austin’s best doctoral dissertation award in 2018. He is a Melosh Medalfinalist, the recipient of best student paper award in SC'17, Gold Medal in theACM Student Research Competition, as well as best student paper finalist inSC’14. He was also part of the Nvidia team that for the first time made lowprecision neural network training possible (FP16), enabling more than 10xincrease in compute power through tensor cores. That technology has been widelyadopted in GPUs today. Amir's current research focuses on efficient AI at theEdge, and scalable training of Neural Network models.