
机器学习线性回归:谈谈多重共线性问题及相关算法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自 | 深度学习这件小事


当用最小二乘法进行线性回归时,在面对一堆数据集存在多重共线性时,最小二乘法对样本点的误差极为敏感,最终回归后的权重参数方差变大。这就是需要解决的共线性回归问题,一般思想是放弃无偏估计,损失一定精度,对数据做有偏估计,这里介绍两种常用的算法:脊回归和套索回归。
基本概念
多重共线性(Multicollinearity)是指线性回归模型中的自变量之间由于存在高度相关关系而使模型的权重参数估计失真或难以估计准确的一种特性,多重是指一个自变量可能与多个其他自变量之间存在相关关系。
例如一件商品的销售数量可能与当地的人均收入和当地人口数这两个其他因素存在相关关系。
在研究社会、经济问题时,因为问题本身的复杂性,设计的因素很多。在建立回归模型时,往往由于研究者认识水平的局限性,很难在众多因素中找到一组互不相关,又对因变量 y 产生主要影响的变量,不可避免地出现所选自变量出现多重相关关系的情形。
在前面的介绍中,我们已经知道普通最小二乘法(OLS)在进行线性回归时的一个重要假设就是数据集中的特征之间不能存在严重的共线性。最迫切的是,我们在拿到一堆数据集时,该如何诊断这些特征间是不是存在共线性问题呢?
如何诊断多重共线性
根据已有的参考文献,常用的多重共线性的诊断方法包括:方差膨胀因子法,特征根分析法,相关系数法等,基于这些方法的启发,本文初步地阐述个人的一些方法,不一定准确,仅代表个人的理解。
我们可以绘制每个特征与 y 间的关系图,然后肉眼对比每个特征对 y 的影响情况,关系走势图相近的那些特征就是可能存在共线性的。
例如,下面所示的一个例子是房子的价值与两个影响它的特征:特征1和特征2,方便起见我们选取了10个样本点来进行两个特征间的相关性分析,在 Jupyter notebook中做了测试,代码如下:
#导入两个常用模块
import numpy as np
import matplotlib.pyplot as plt
#2个特征的样本X
X=np.array([[20.5,19.8],[21.2,20.4],[22.8,21.1],
[18.2,23.6],[20.3,24.9],[21.8,26.7],
[25.2,28.9],[30.7,31.3],[36.1,35.8],
[44.3,38.2]])
#标签值 y
y=np.array([7.8,8.6,8.7,7.9,8.4,8.9,10.4,11.6,13.9,15.8])
#绘制特征1和y的散点图
plt.scatter(X[:,0],y)
plt.show()
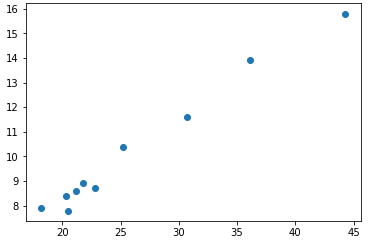
#绘制特征2和y的散点图
plt.scatter(X[:,1],y)
plt.show()
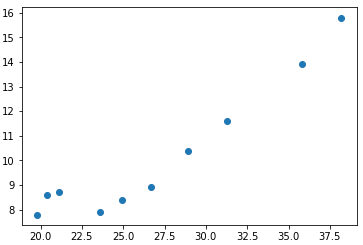
从散点图中可以看出,这两个特征和y的关系趋势很相似,进一步放到一起绘制折线图:
plt.plot(X,y,marker='o')
plt.show()
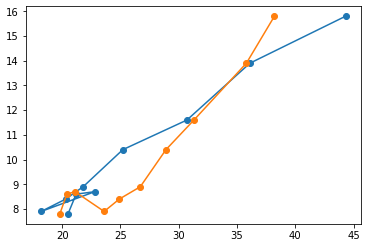
可以看到这两个特征与y的关系呈现出相同的曲线走势,我们初步这两个特征可能具有相关性,这仅仅是在一个观察层面。
怎么进行量化分析呢?我们考虑具有一般性的公式,通常两个变量间的相关系数的定义如下:
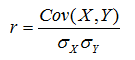
将上述公式,实现为代码,如下所示:
#特征1和特征2的协方差
cov = np.cov(X[:,0],X[:,1])
cov
array([[ 70.44544444, 49.15144444],
[ 49.15144444, 41.24455556]])
#特征1的标准差
sigmaX1 = cov[0,0]**0.5
#特征2的标准差
sigmaX2 = cov[1,1]**0.5
#相关系数
r = cov[0,1]/(sigmaX1*sigmaX2)
r
0.9118565340789303
相关系数为0.911,说明特征1与特征2之间有高度的线性正相关关系。当相关系数为0时,表明没有关系,为负数时,表明特征1与特征2之间有负相关关系,即有一个这样的你增我减,你减我增的趋势。
如果忽略这个问题,还是要采取普通最小二乘法来进行回归,可能导致的问题简单来说是造成权重参数估计值的方差变大。比如,样本的特征如下:
A =np.array([[0.9999,2],[2,4],[4,8]]),y = np.array([1,2,3]),可以看到此时是强线性相关的,直接用直接求权重公式la.inv((A.T.dot(A))).dot(A.T).dot(y),得出参数:
array([-1999.9998031, 1000.3999014]),
再降低一些线性相关强度:
A =np.array([[0.9900,2],[2,4],[4,8]]),得出参数:
array([-20. , 10.4])
再降低,A =np.array([[0.900,2],[2,4],[4,8]]),得出参数:
array([-2. , 1.4])
再降低A =np.array([[0.8,2],[2,4],[4,8]]),得出参数:
array([-1. , 0.9])
再降低A =np.array([[0.5,2],[2,4],[4,8]]),得出参数:
array([-0.4, 0.6])
画出以第一个权重参数随着线性相关性的增加的趋势图:可以看到在0.9999时骤降,表明方差突然变大,变化幅度为2000左右。
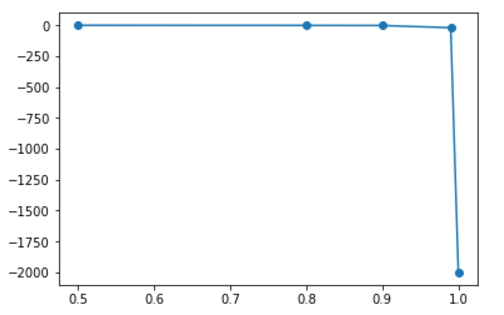
拿掉0.9999这个特征取值后,变化幅度为20。
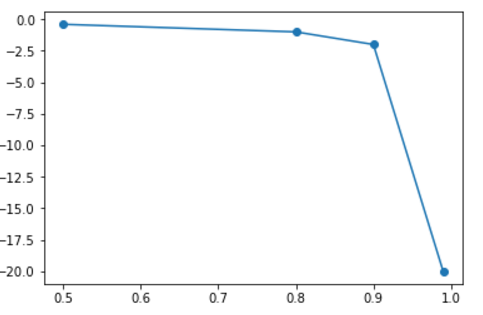
因此验证了多重共线性越强,造成的后果:参数方差越大。
接下来,尝试改进普通最小二乘法来解决共线性问题。
添加正则化项解决共线性
正则化在机器学习中扮演者重要的角色,一方面它有可能解决经常出现的过拟合问题,另一方面能解决上文提到这种病态矩阵,也就是不适定问题。对于正则化的理解,将会是以后机器学习需要反复仔细体会的一项重要技术。
在普通最小二乘法的基础上,将代价函数加一个正则化项,就可以解决共线性问题,这个方法牺牲了权重参数的精度,带来的收益是解决了共线性带来的不稳定。如果添加一个L1正则项,算法称为套索回归,如果添加一个L2正则化项,称为脊回归,公式分别表示为:
套索回归
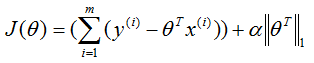
脊回归
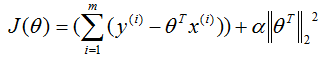
下面在Jupyter Notebook,直接调用sklearn库中的回归分析的API,分析上面的共线性数据在使用普通最小二乘,L1最小二乘(套索),L2最小二乘(脊回归)下回归样本后,对新来的数据的预测精度。
我们用上节例子来阐述正则化项的作用,用的测试样本如下所示:
X =np.array([[0.9999,2],[2,4],[4,8]])
y = np.array([1,2,3])
直接调用sklearn的接口:
from sklearn import linear_model
#OLS
reg = linear_model.LinearRegression()
reg.fit(X,y)
得到的权重参数:
array([ 5000.00000002, -2499.75000001])
#脊回归
ridreg = linear_model.Ridge (alpha = .5)
ridreg.fit (X, y)
得到的权重参数:
array([ 0.12589929, 0.25173425])
#套索回归
ridreg = linear_model.Lasso(alpha = 0.1)
ridreg.fit (X, y)
得到的权重参数:
array([ 0. , 0.30535714])
可以看到脊回归和套索回归由于正则化项不同,最终导致的权重参数也一样,最令人印象深刻的是,套索回归由于使用了L1正则化,直接将特征1的权重参数置为0,也就是将强线性相关项中的某一个直接抛弃掉,只取其中一个特征项作为主特征项进行分析计算。
OLS算法得出的权重参数在上节已经验证过,稍微改变一下线性相关的强度,导致的权重参数改变巨大,也就是参数的方差很大,这说明它的不稳定性。
总结
在上节中,我们阐述了如何诊断多重共线性问题,以及通过添加正则化项为什么可以解决这个问题,在本文的论证中我们举的例子是两个特征间的共线性,这种方法简单直观地进一步验证了OLS权重参数的方差和共线性的关系,以及脊回归和套索回归加上正则化项后发挥的作用。
在本文论述中有些术语可能不够精确,还请各位多包涵。谢谢各位的阅读。
—完—
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论