整个事件,还是要从这篇在3月26日上传至arXiv的「A Roadmap for Big Model」说起。不得不说,如此大规模的「作者团」也就能在Nature、Science等顶刊中偶尔瞥见。而近一半的共同一作,和四分一的共同通讯作者则实属罕见。随后,作者又分别在3月30日和4月2日对版本进行了更新,这其中也涉及到了作者名单的变动。这篇论文不仅谈到了大模型技术本身,还有训练大模型的前提条件。研究分为四个部分:资源、模型、关键技术以及应用。并介绍了16个有关大模型,分别是:数据、知识、计算系统、平行训练系统、语言模型、视觉模型、多模块模型、理论&可解释性、常识推理、可靠性&安全、治理、评估、机器翻译、文本生成,以及对话和蛋白质研究。在论文的最后,研究人员从更加宏观的角度总结了大模型未来的发展。而这,只是一切的开始。
被抄的谷歌研究员亲自爆料抄袭
2022年4月8日,来自谷歌大脑的研究员Nicholas Carlini在其个人博客上贴出文章「机器学习研究中的剽窃事例」(A Case of Plagiarism in Machine Learning Research)。其中条分缕析、清楚克制地指明了「大模型路线图」(A Roadmap for Big Model)的抄袭实迹:「大模型路线图」一文确实抄袭了他所在研究组2021年7月发表在预印本网站上的论文「复制训练数据让语言模型更优」(Deduplicating Training Data Makes Language Models Better)。此外,「大模型」一文还涉嫌抄袭十余篇其他论文。Nicholas Carlini含蓄地表示:「大模型」一文「复制粘贴」了一篇关于数据复制效果的论文,此举实在讽刺到无法被忽视。不过Nicholas Carlini也忠厚地体谅了有关涉事者:「从大局来看,这次复制粘贴并不是最恶劣的事。这又不是此论文直接抄袭了过往研究的方法与结论、然后自称这是开创性新研究成果。不过即便如此,领域总括性综述的价值在于如何重新表述/定义研究领域。直接复制粘贴之前其他论文内容的长篇总括性综述,并不比简短的引用列表的用处更大。」4月13日,在事件被更多人了解并关注后,Nicholas Carlini在此文中补充了更新内容:本文受到了我预期外的太多关注。本文的每小时新增浏览量都多过我博客上周的一周全站浏览量。所以在此恳求,不要让此事发酵成一场猎巫迫害。我看到已有人称应该马上把肇事论文相关人等全部开除、预印本网站应对他们完全禁入等等。我并不假装了解肇事论文何以如此广泛抄袭的幕后原因,因此我不多做论断。可能是一些初级作者并无恶意,以为有引用来源就可以复制粘贴。也可能是学生们受到来自导师的压力,觉得要按时交稿就只好走捷径。高级作者们可能只读了遍文本,认为无大碍就小修小补后放行,不清楚文本的来源为何。关键在于,此事幕后因由现在仍未公开。此论文有过百名作者,任何事都有可能发生。我发布此贴文的愿望,是想给学界常见的积弊招来更多关注。学界有近1%的已发表和被接受的论文,其数据复制粘贴比率比「大模型」一文还要高。我该在写此贴的一开始就说清这个背景。所以再次请大家不用对肇事论文过苛。抄袭是学界常见之弊,我对此事更警醒,是因为被抄袭的是我的论文。希望大家可以将此作为提高学界整体质量的严肃学习经验。
判定流程
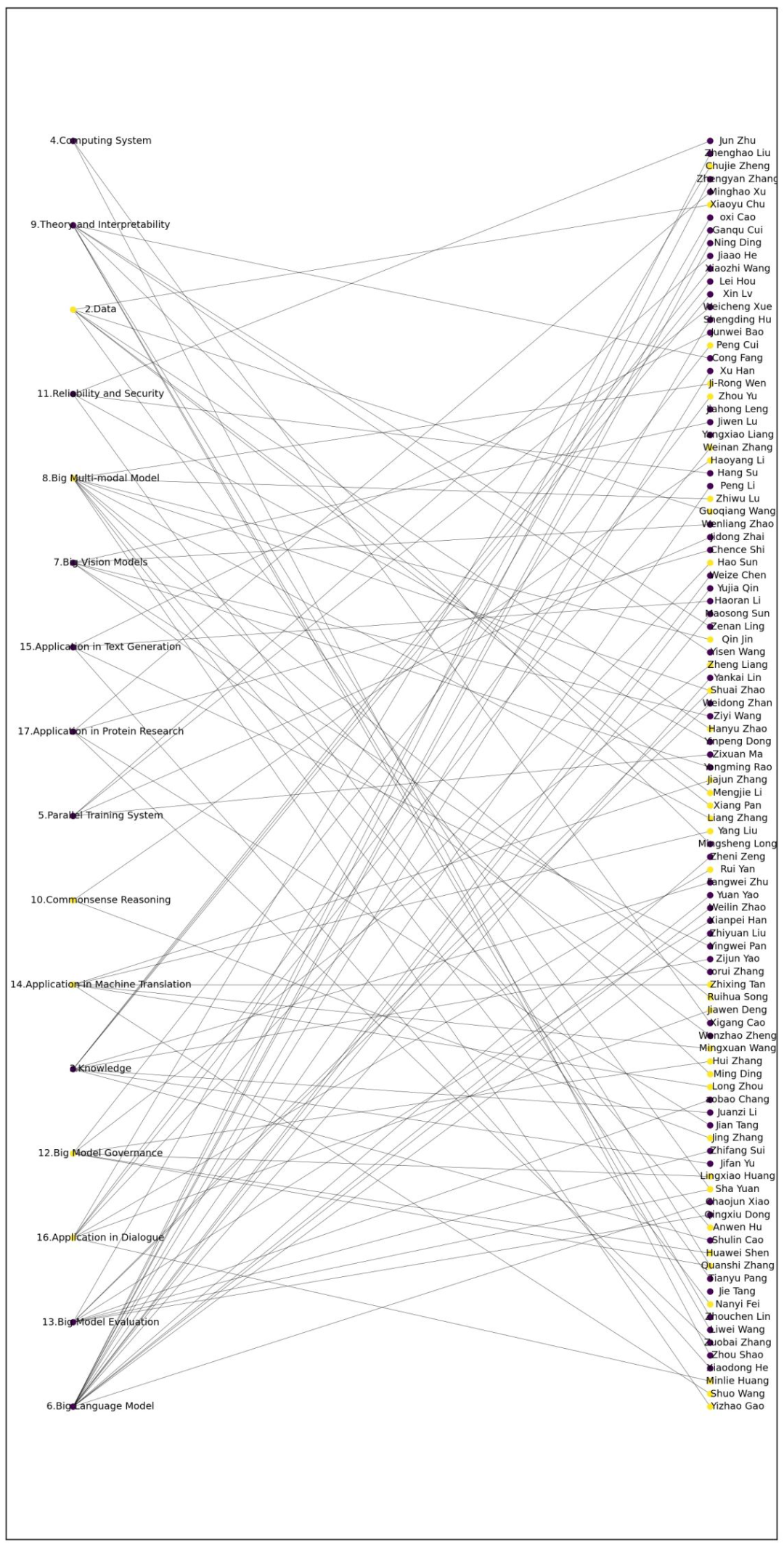
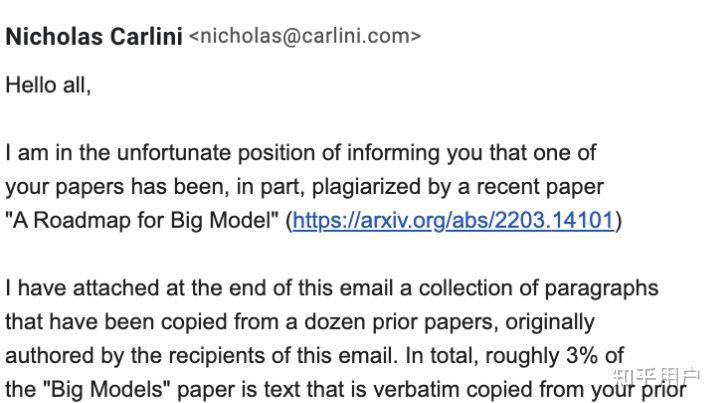
Nicholas Carlini在其博客文章中称,在发现「大模型」一文有抄袭后,他与研究组同事将几乎所有机器学习领域的顶会、顶刊论文的PDF文件下载、然后提取所有其中的文本、再录入单个txt文档中,获得对比用的数据集。最后Nicholas Carlini与同事使用-自家被抄袭论文中的-数据集复制工具,将「大模型」一文与对比数据集一跑,发现了「大模型」一文的抄袭部分。博客文章中列举了十处抄袭最昭彰的部分,其中五处的主干部分已被智源研究院的致歉信承认。以下是Nicholas Carlini博文中列举的、智源研究院承认的抄袭处与原文对比的示例,左侧标绿部分为抄袭后的文本,右侧为原文对照文本。为了避免假阳性,Nicholas Carlini列举了自己认定抄袭的标准:1、在文本空格规范化后,至少有十个字词以上的抄袭雷同处;2、在「大模型」一文中依顺序出现;3、在之前的其他论文中有出现;4、但不在之前一篇以上的论文中出现。如此可以避免软件工具将论文的版权声明部分、此前论文对更前论文的引用、此前各篇论文的作者这些理应出现雷同处的部分认作抄袭。Nicholas Carlini称,他们的软件工具还跑出来不少「大模型」一文作者们自我抄袭的部分。不过相较于对他人论文的肆意赤裸抄袭,「我抄我自己」简直不算什么大事了。Nicholas Carlini还表示,由于筛选工具的急就性质、和对比数据集的不完备性(只包括已在学刊上发表的论文,不包括预印本网站论文),很可能还有更多的抄袭部分尚未被发现。无论如何,现有程度已经很令人伤感了。「大模型」一文随后也被arXiv官方做了标注:与其他作者的文字「重合」。此外,也有国内的网友对文章进行了源头对比,其中紫色的是无抄袭的,黄色的是涉嫌抄袭的。部分作者没有出现在具体章节里但是在总作者名单里。除了对自己文章进行了一波排查以外,Nicholas也与其他可能被抄袭的作者取得了联系。其中一个收到邮件的网友表示,现在很多人对于抄袭的重视和了解程度是不够的。copy-past是抄袭,copy-paste-edit是抄袭,截图是抄袭,复制别人arxiv上的latex公式也是抄袭。这次的事件影响之大,对整个华人学者的声誉都带来了沉重的打击。AI业界的研究者纷纷在社交网站上表示疑惑:即使有任务分工、或者挂名现象,百多号作者没一个细读过自己要挂名的东西么?





















 下载APP
下载APP