
【学术相关】清北等单位 100 位大佬署名论文,被曝 10 处抄袭,第一单位致歉:追责到人
来源:Retraction

"
"
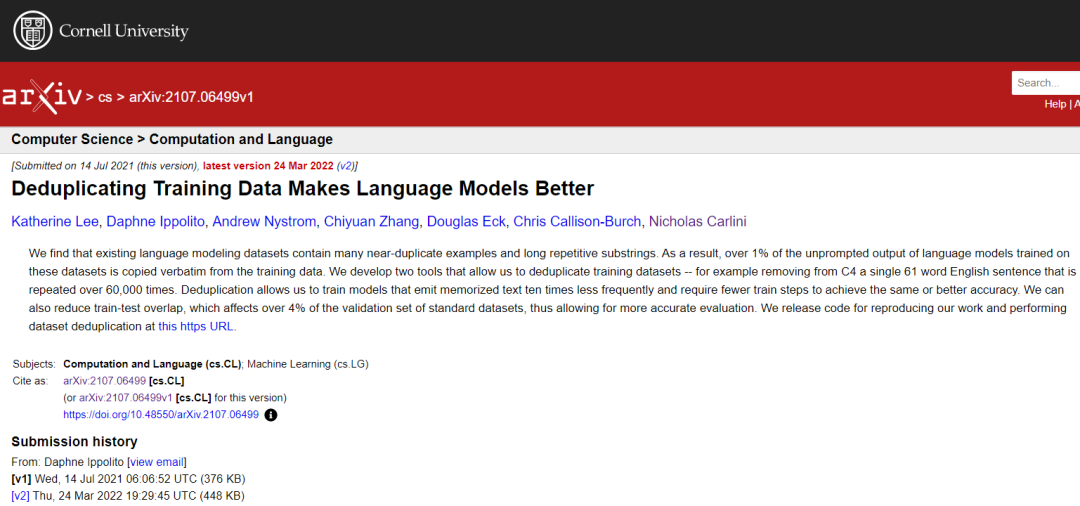
2021年7月14日,Katherine Lee等人在预印版平台arXiv 在线发表题为“Deduplicating Training Data Makes Language Models Better”的研究文章,该研究开发了两种工具,允许研究人员对训练数据集进行重复数据删除——例如,从 C4 中删除重复超过 60,000 次的单个 61 个单词的英语句子。重复数据删除使研究人员能够训练发出记忆文本的频率降低十倍的模型,并且需要更少的训练步骤来达到相同或更好的准确性。 该研究还可以减少训练测试重叠,这会影响超过 4% 的标准数据集验证集,从而可以进行更准确的评估。
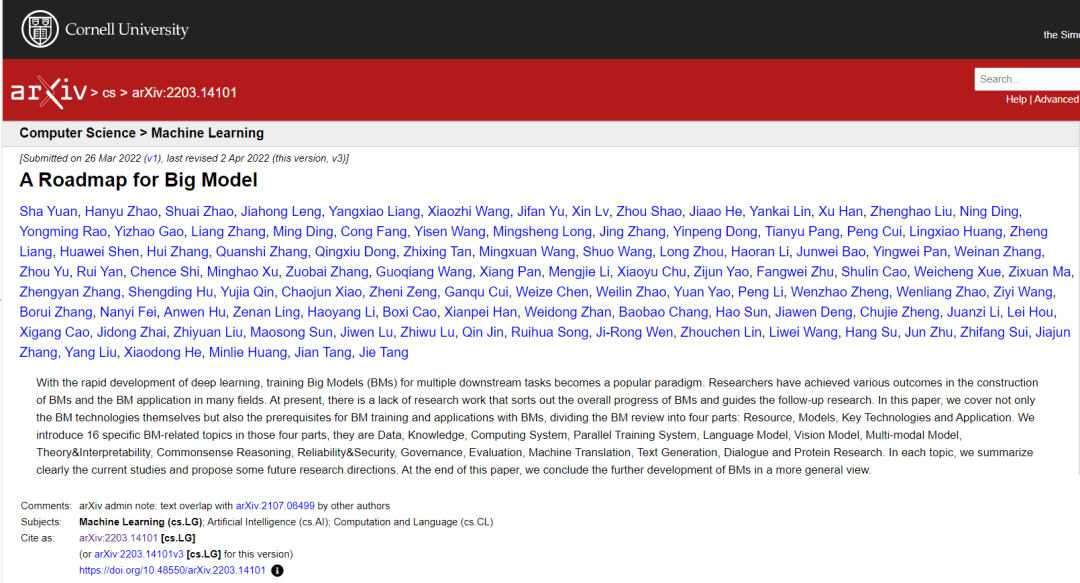

2022年3月26日,清华大学、东北大学、纽约大学、北京大学、哥伦比亚大学、哈尔滨工业大学、北京航空航天大学、上海交通大学、蒙特利尔大学等多单位合作,唐杰等100多为作者在预印版平台arXiv 在线发表题为“A Roadmap for Big Model”的综述文章,该综述不仅涵盖了 BM 技术本身,还涵盖了 BM 培训和应用 BM 的先决条件,将 BM 审查分为四个部分:资源、模型、关键技术和应用。
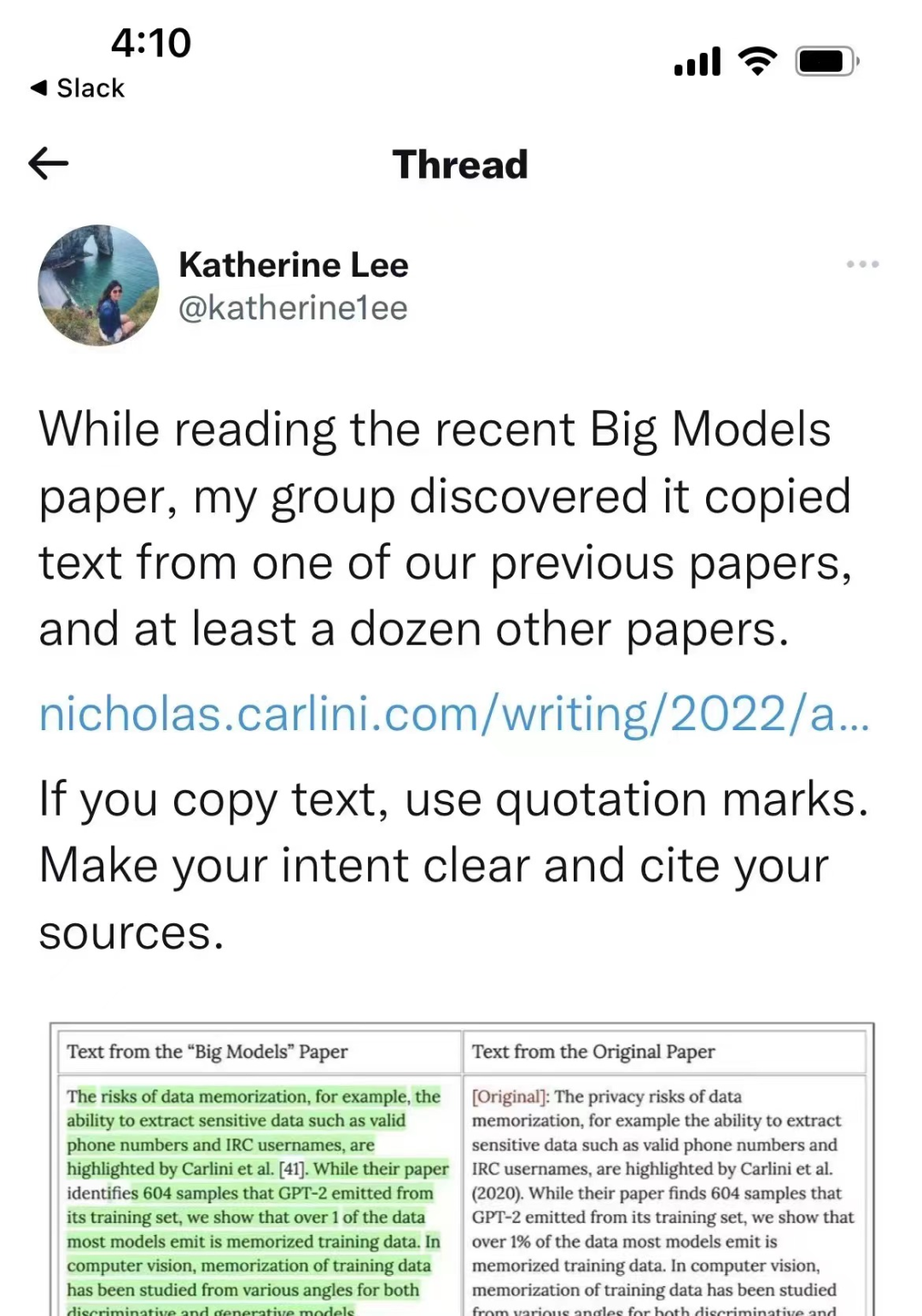
但是,近期Katherine Lee爆料,唐杰等人发表的文章与Katherine Lee等人先前发表的“Deduplicating Training Data Makes Language Models Better”文章存在大量重叠。

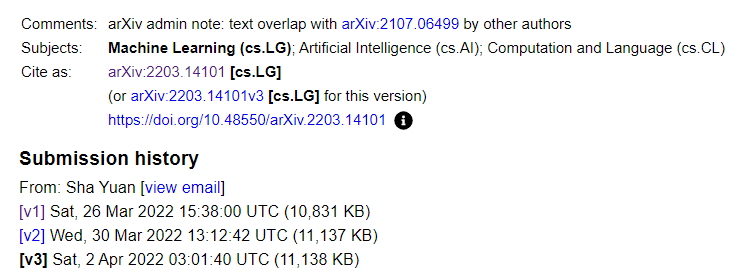
由于Katherine Lee的爆料,arXiv也在唐杰等人发表的文章做了文章重叠的警示。
该文章的第一作者单位北京智源人工智能研究院发布说明称,已展开调查,对学术不端零容忍。

2022年4月13日,北京智源人工智能研究院分布了初步研究调查报告:
今天我们从互联网上获悉,智源研究院在预印本网站arXiv发布的综述报告“A Roadmap for Big Model”(大模型路线图)涉嫌抄袭。对这一情况,研究院立即组织内部调查,确认部分文章存在问题后,已启动邀请第三方专家开展独立审查,并进行相关追责。
对于这一问题的发生,我们深感愧疚。智源研究院作为一家科研机构,高度重视学术规范,鼓励学术创新和学术交流,对学术不端零容忍。在此,我们向相关原文作者和学术界、产业界的同仁和朋友表示诚挚的道歉。


参考消息:
https://arxiv.org/abs/2203.14101
https://arxiv.org/abs/2107.06499
https://zhuanlan.zhihu.com/p/497629749
https://zhuanlan.zhihu.com/p/498064778
仅作学术分享之用,如有不妥,请联系删除!
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: