谷歌联手DeepMind提出Performer:用新方式重新思考注意力机制
共
2921字,需浏览
6分钟
·
2020-10-28 03:07
编辑:QJP
【新智元导读】谷歌、 DeepMind、艾伦图灵研究院和剑桥大学的科学家们提出了「Performer」,一种线性扩展的人工智能模型架构,并在蛋白质序列建模等任务中表现良好。它有潜力影响生物序列分析的研究,降低计算成本和计算复杂性,同时减少能源消耗和碳排放。
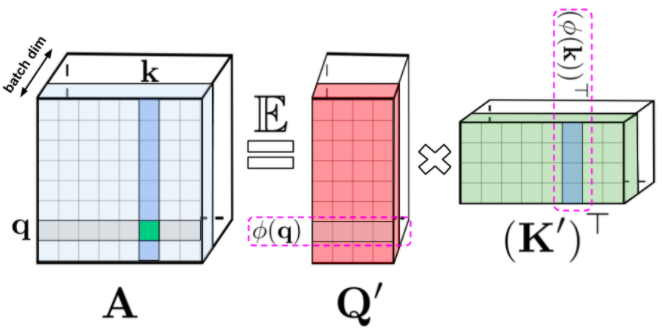
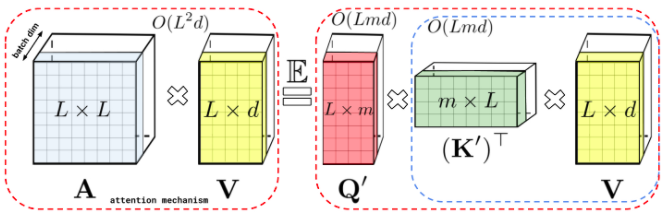
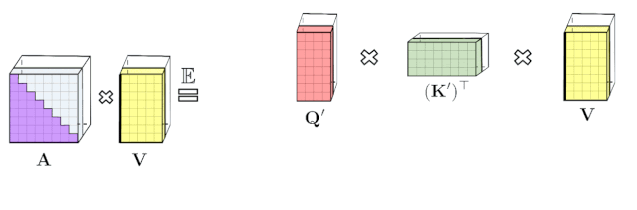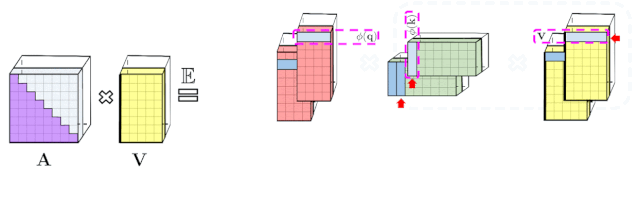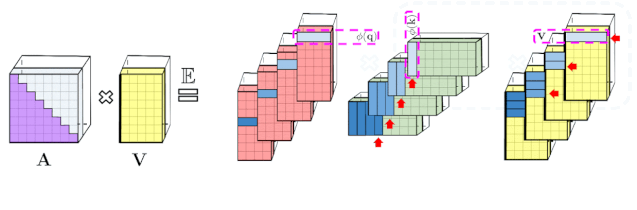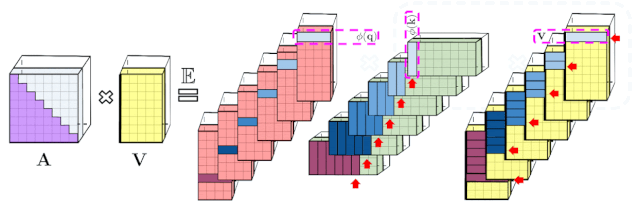
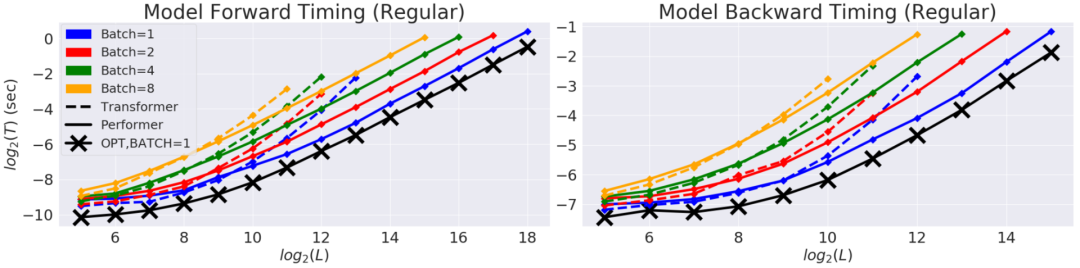
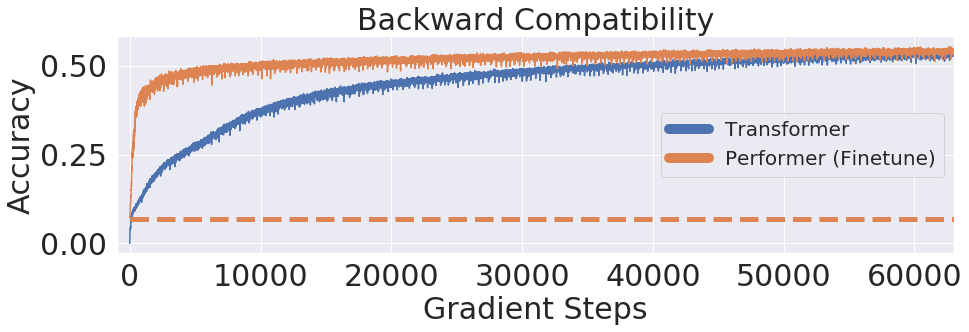
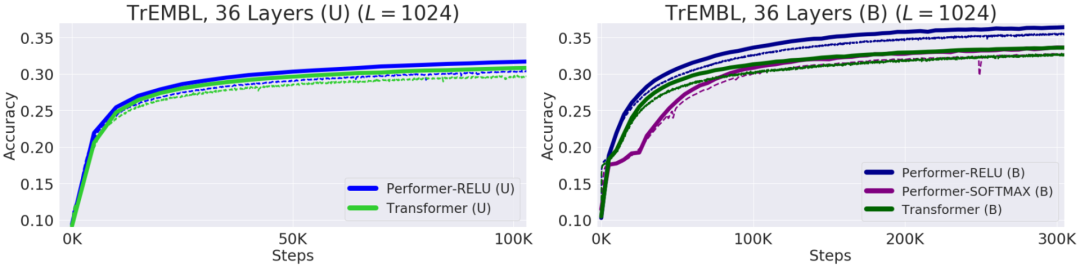
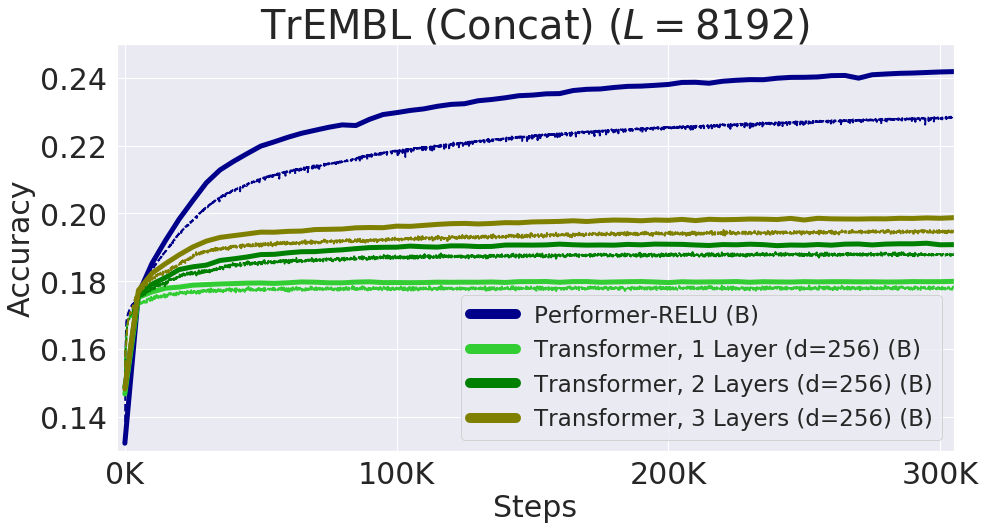
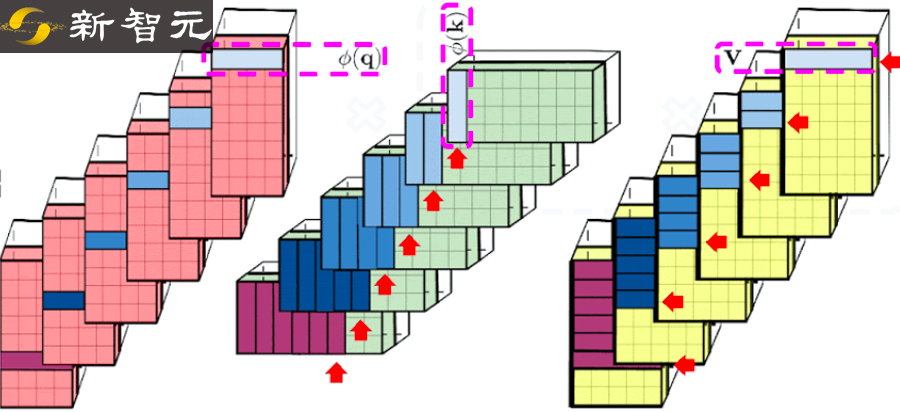
Transformer 模型在很多不同的领域都取得了SOTA,包括自然语言,对话,图像,甚至音乐。每个 Transformer 体系结构的核心模块是 Attention 模块,它为一个输入序列中的所有位置对计算相似度score。然而,这种方法在输入序列的长度较长时效果不佳,需要计算时间呈平方增长来产生所有相似性得分,以及存储空间的平方增长来构造一个矩阵存储这些score。对于需要长距离注意力的应用,目前已经提出了几种快速且更节省空间的方法,如内存缓存技术,但是一种更常见的方法是依赖于稀疏注意力。稀疏注意力机制通过从一个序列而不是所有可能的Pair中计算经过选择的相似性得分来减少注意机制的计算时间和内存需求,从而产生一个稀疏矩阵而不是一个完整的矩阵。这些稀疏条目可以通过优化的方法找到、学习,甚至随机化,如Sparse Transformers、Longformers、RoutingTransformers、Reformers和BigBird。由于稀疏矩阵也可以用图形和边来表示,稀疏化方法也受到图神经网络文献的推动,在图注意网络中列出了与注意力的具体关系。这种基于稀疏性的体系结构通常需要额外的层来隐式地产生完全的注意力机制。不幸的是,稀疏注意力的方法仍然会受到一些限制,如:(1)需要高效的稀疏矩阵乘法运算,但并非所有加速器都能使用;(3)主要针对 Transformer 模型和生成式预训练进行优化;(4)它们通常堆叠更多的注意力层以补偿稀疏表示,使其难以与其他预训练模型一起使用,因此需要重新训练和显著的内存消耗。除了这些缺点,稀疏注意力机制往往仍然不足以解决所有的正常注意力机制的问题,如指针网络(Pointer Network)。同时也存在一些不能稀疏化的操作,比如常用的softmax操作,它使注意机制中的相似度得分归一化,在工业规模的推荐系统中得到了广泛的应用。为了解决这些问题,Google AI的研究人员引入了「Performer」,这是一个具有注意力线性扩展机制的Transformer架构,可以使模型在处理更长序列的同时实现更快的训练,这是对于特定的图像数据集如 ImageNet64和文本数据集如 PG-19所必需的。Performer使用了一个有效的(线性的)广义注意力框架,它是一种允许基于不同的相似性度量(Kernel)的注意力机制。在原有的注意力机制中,query和key分别对应于矩阵的行和列,再进行相乘并通过softmax形成一个注意力矩阵,并存储下来相似性score。请注意,在这种方法中,不能将query-key传递到非线性 softmax 操作之后再将其分解回原来的key和query,但是可以将注意力矩阵分解为原始query和key的随机非线性函数的乘积,也就是所谓的随机特征(random features),这样就可以更有效地对相似性信息进行编码。FAVOR+: Fast Attention via Matrix Associativity上面描述的那种矩阵分解,使得可以使用线性而不是二次的复杂度来存储隐式注意力矩阵,同时也可以通过这种分解得到一个线性时间的注意力机制。原有的注意力机制是将注意力矩阵乘以输入的value值来得到最终结果,而注意力矩阵分解后,可以重新排列矩阵乘法来逼近常规注意机制的结果,而无需显式构造二次的注意力矩阵。上述分析与所谓的双向注意力有关,即没有过去和未来概念的「非因果注意力」。对于单向(因果)注意力,即Mask掉不参与输入序列后面计算的其他token,只使用前面的token参与计算,只存储运行矩阵计算的结果,而不是存储一个显式的下三角注意力矩阵。我们首先对Performer的空间和时间复杂度进行基准测试,结果表明,注意力加速和内存减少几乎是最优的,也就是说,结果非常接近于在模型中根本不使用注意力机制。研究人员又进一步展示了 Performer,使用无偏 softmax 逼近,向后兼容经过一点微调的预训练Transformer模型,可以通过提高推断速度降低成本,而不需要完全重新训练已有的模型。蛋白质是具有复杂三维结构和特定功能的大分子,对生命来说至关重要。与单词一样,蛋白质被指定为线性序列,其中每个字符是20个氨基酸构建块中的一个。将 Transformers 应用于大型未标记的蛋白质序列产生的模型可用于对折叠的功能性大分子进行准确的预测。Performer-ReLU (使用基于 relu 的注意力,这是一个不同于 softmax 的广义注意力)在蛋白质序列数据建模方面有很强的表现,而 Performer-Softmax 与 Transformer 的性能相匹配,正如理论所预测的结果那样。下面,我们可视化一个蛋白质Performer模型,使用基于 relu 的近似注意力机制进行训练,使用 Performer 来估计氨基酸之间的相似性,从序列比对中分析进化替换模式得到的替换矩阵中恢复类似的结构。更一般地说,我们发现局部和全局注意力机制与用蛋白质数据训练的Transformer模型一致。Dense Attention的近似Performer有可能捕捉跨越多个蛋白质序列的全局相互作用。作为概念的验证,对长串联蛋白质序列进行模型训练,会使得常规 Transformer 模型的内存过载,但 Performer模型的内存不会过载,因为它的空间利用很高效。Google AI的这项工作有助于改进基于非稀疏的方法和基于Kernel的Transformer,这种方法也可以与其他技术互操作,研究人员甚至还将 FAVOR 与Reformer的代码集成在一起。同时研究人员还提供了论文、 Performer的代码和蛋白质语言模型的代码链接。Google AI的研究人员相信,他们对于Performer的研究开辟了一种关于Attention、Transformer架构甚至Kernel的全新的思维方式,对于进一步的改进有巨大的启示作用。


点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报