
重新思考深度学习中的Attention机制

极市导读
本文的讲述的是关于深度学习中的Attention机制,本文并非定位于对Attention机制的各类框架和玩法进行综述,而是介绍了四个Attention的有代表性和有意思的工作,并给出关于Attention机制的合理性的进一步的思考。 >>明日直播!田值:实例分割创新式突破BoxInst,仅用Box标注,实现COCO 33.2AP!
写在前面: 本文是一篇关于深度学习中的 Attention机制 的文章。与之前的系列文章不同,本文并非定位于对Attention机制的各类框架和玩法进行综述,因此不会花费过多的篇章去介绍Attention的发展历史或数学计算方法;更多是简单地介绍几个Attention的代表性和有意思的工作,并去思考Attention机制的合理性,提出一些进一步的思考。
以下是本文的主要框架:
问题来源 & 背景 “朴素”的Attention思想 Attention相关的有趣工作 What's more
1. 问题来源 & 背景
最近做了非常非常久的多任务学习工作(或许后面会整理一下),在尝试到MMoE这个模型时,发现了一件有意思的事情。
我们知道,在MMoE模型中,专家层的下一层——Gate层的工作是针对不同的任务,对专家的输出进行加权求和,使得不同任务按照自己的需要获取不同专家的信息,最终目的应该是将不同专家提取到的特征用一种更加无损的方式融合起来。
MMoE如下图最右侧的C模型,Gate A的工作是对专家0,1,2的输出进行加权,并将加权之后的结果输出给Tower A,用于A任务后续计算Logit。
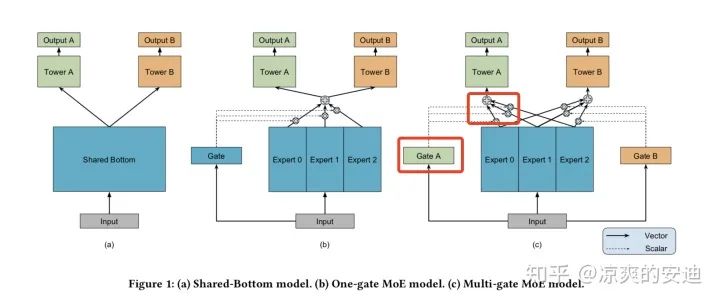
图1,MMoE模型结构,
在Gate A中采取了一种很有趣的方式来对专家0,1,2的方式进行加权融合:
专家0,1,2分别是从input处连接的全连接网络。 对于每个Tower(与Gate一一对应),从input处连接一个全连接网络(网络参数W的Size为input size * 3),并对这个全连接模块的输出进行Softmax。 将Softmax后的结果作为权重,分别乘以专家0,1,2的输出,作为加权融合后的结果,用作Tower A后续的操作。
读完Paper后,第一遍实现MMoE时并没有发现什么问题。后面和同事讨论,我们感觉Gate模块本质上就是一个对专家输出进行加权融合的模块,那这个模块为何不用主流的Attention来实现一下呢?
于是,我们修改了MMoE Gate层的结构,为每个任务随机设置了一个Context向量,作为Attention模块的Query,用Context与MMoE专家的输出计算相似度,根据相似度对于专家输出进行加权。修改后的模型,在我们的场景下,在多个任务上的评价指标居然高于原生的MMoE Gate层不少。
这件事情让我萌发了再深入思考一下Attention机制的想法!
2. “朴素”的Attention思想
如果用一句话来描述Attention机制的作用,你会怎么选择?
Attention机制的作用就是对信息进行更好地加权融合。
我们来看下这句话的关键词。其实就两个,第一,信息;第二,加权融合。
这两个词怎么来理解呢?
“信息”。深度学习里的信息,无非就是特征,隐藏层的输出。
2. “加权融合”。这个也比较好理解,我们可能通过不同的方式获取了几组信息后,并非简单地将这几组信息直接进行concat或者直接相加,而是根据每组信息的重要性,为其赋予一个权重,再按照权重求和。
从这个角度上来看,Attention机制人如其名——注意力机制,表现了对信息重要性程度的关注。Attention作为深度学习的一个组件,其实是通过信息加权融合的方式,目的是为了让网络获取更好的特征表达。
Attention的例子在生活中比比皆是。
男生:多喝热水。
女生:你怎么就知道让我喝热水,啥也不是!
因为女生情绪比较激动,可能忽略了平时男生对她也是体贴的,导致一个临时事件的权重急速上升,权重失衡就生气了(当然男生也有问题O(∩_∩)O~)。
再比如说,“颜狗”这个词,说的就是你对于人评价的Attention权重过多分配在对方的颜值上,又是一个Attention机制没有train好的例子。= =当然,如果“颜值”这个Value更适合你的Query就当我没说。
大白话讲完了,为了让文章显得更加直观和科学一点,我们来简单看下Attention的计算方式。
通常的文章在介绍Attention机制的时候往往是和Encoder-Decoder架构放在一起来讲,我感觉多一些影响因素反而会影响理解。因此,我们抛离Encoder-Decoder架构来看看Attention机制。
我们先看看下面的图,
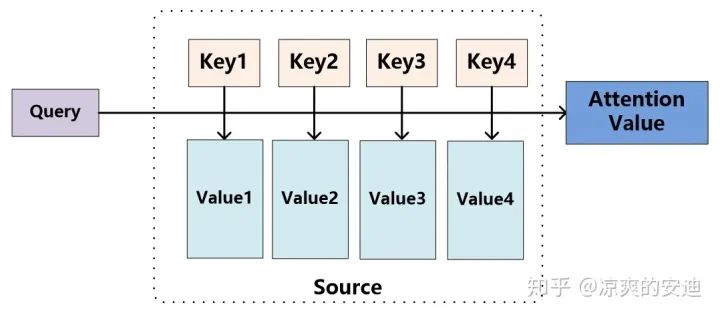
图2,Q, K, V
Value1到4是我们要用来加权的信息,类比搜索系统中的文档内容。 Key1到4是用于检索Value的“索引”,与Value一一对应,类比搜索系统中的文档摘要或者文档关键词。 Query是用来检索Key的信息,我们通过计算Q与各个K的“相似”或者说“匹配”程度,得到每个V对应的权重,根据权重对V进行加和。
用数学语言来描述,通过Query与Key逐一计算“相似度”,得到相似度权重a,使用a对于Value进行加权得到最终的输出。

3. Attention相关的有趣工作
3.1 Hierarchical Attention Networks
《Hierarchical Attention Networks for Document Classification》本文的应用场景是文档分类,本质上还是使用了Attention作为基础组件,但是让Attention的建模具有了层级结构:
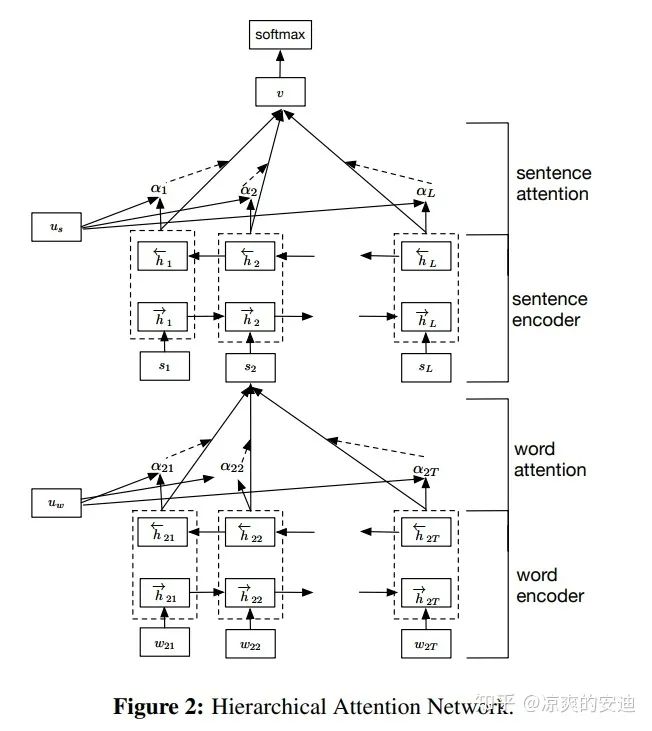
图3,Hierarchical Attention Networks网络结构
文档由句子组成,句子由单词组成,这是一个两层结构。
对于每个句子,通过Attention获取到每个单词的注意力权重,并词级别信息进行加权,最终获得句子的特征表示。 对于每个文档,通过Attention获取到每个句子的注意力权重,并句子级别信息进行加权,最终获得文档的特征表示。
具体做法为:
首先,设置两个context向量:
 是词语级别的context vector;
是词语级别的context vector;  是句子级别的context vector。
是句子级别的context vector。从句子的层面来看,针对每一个句子,用双向GRU建模,计算出每个词语的hidden vector。用
与hidden vector通过内积计算相似度作为每个词语的权重,加权以后就可以产生整个sentence的表示。从document层面来看(hierarchical),针对每个document,对每个句子使用双向GRU建模,同上使用
来获取句子的权重,加权以后就可以产生整个document的表示。
思想很简单,结果很惊艳。
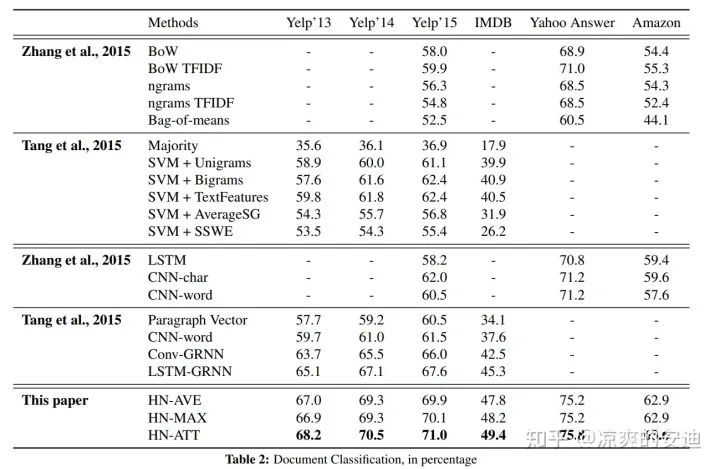
图4,Hierarchical Attention Networks模型效果
3.2 Self-attention & multi-head attention
这个可能大家更熟悉一些,《Attention is all you need》中明确提出的思想,并成为Bert等预训练模型的基础框架。
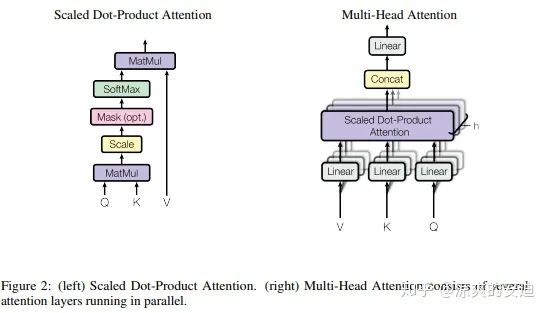
图5,Self-Attention和Multi-head attention
Self-Attention的提出是为了对句子信息进行更好的建模,让每个词中,都可以更好地融入其他单词的信息。
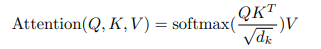
而多头Attention则是Concat了多组Self-attention的结果。

网上关于multi-head attention详细描述比较多,在此就不展开赘述了,简单推荐一篇文章:
《Attention is All You Need》浅读(简介+代码)
https://spaces.ac.cn/archives/4765/comment-page-1
同时,大家可以关注一下这个不错的问题
为什么Transformer 需要进行 Multi-head Attention?
https://www.zhihu.com/question/341222779/answer/814111138
Multi-head attention基本已经成为NLP领域的标配框架了,且在推荐领域有较好的应用场景,一个最简单的转化就是AutoInt(《AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks》)了,直接用Multi-head attention去对CTR问题进行建模。AutoInt在我们的尝试中,效果较好,建议大家可以关注。
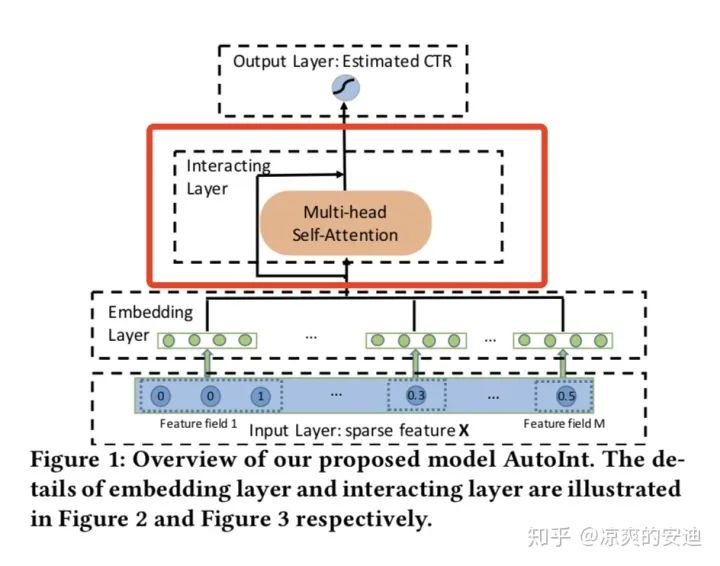
图6,AutoInt网络结构
3.3 Multi-Head Attention with Disagreement Regularization
如果在Multi-Head Attention中设置多个头是为了让模型关注不同的信息角度,但是在具体的实践中会发现:如果让每个attention的头原生地自发生长会可能导致信息冗余的发生——多个头提取的特征比较一致。
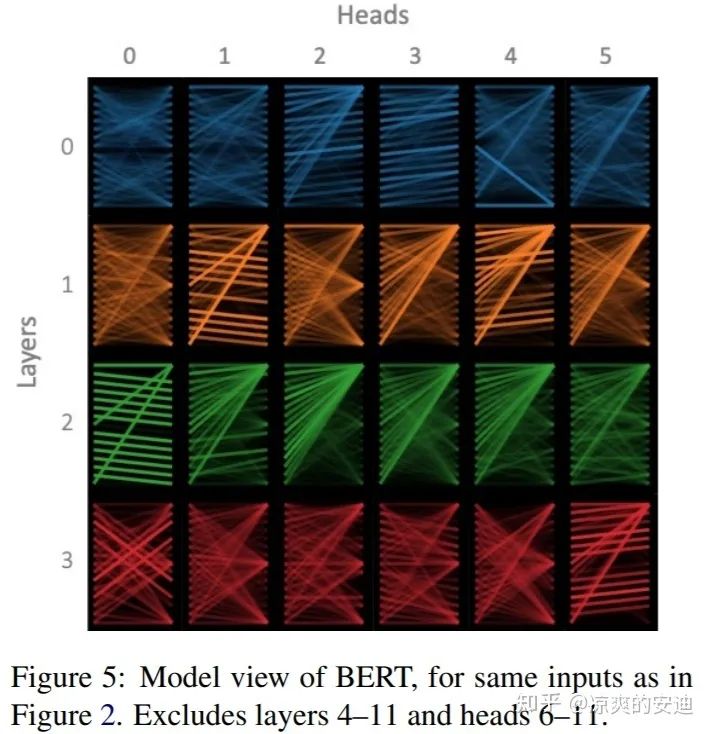
图7,Bert Head可视化情况《A Multiscale Visualization of Attention in the Transformer Model》https://arxiv.org/pdf/1906.05714.pdf
如上图所示,第三层的1, 2,3,4等几个Head学习结果高度相似。那么有没有办法来提升不同Head的学习能力呢?
《Multi-Head Attention with Disagreement Regularization》一文中,希望通过对不同的Head加正则的方式,来提升不同Head学习的差异性。
原文中,添加了三种类型的正则:
a. Disagreement on Subspaces (Sub.)——增大不同Head的Value空间中,Value的差异
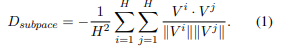
b. Disagreement on Attended Positions (Pos.)——增大不同的Head中,注意力权重的差异
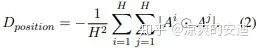
c. Disagreement on Outputs (Out.)——直接增加不同的Head的输出的差异
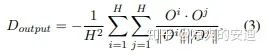
最终,在NMT任务中,基于正则的多头Attention取得了优于Base的普通多头Attention的效果。
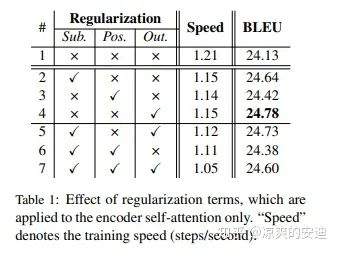
图8,《Multi-Head Attention with Disagreement Regularization》模型效果
3.4 Attention的长程依赖问题
我们在计算Attention时,与RNN,CNN一样,也存在长程依赖问题。
这里有一篇比较RNN,CNN,Transfomer长程依赖和效果的比较的论文供大家参考。
https://www.aclweb.org/anthology/D18-1458.pdf
在《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》中提出了Transfomer-XL模型,提出了一种相对位置编码的方式,相对于Base的Transfomer模型效果略有提升,但是相应地参数量增大。
文中提出了跨相邻两个区域的attention来解决长程依赖依赖的问题,使得Transfomer可以提取更长文本的信息。
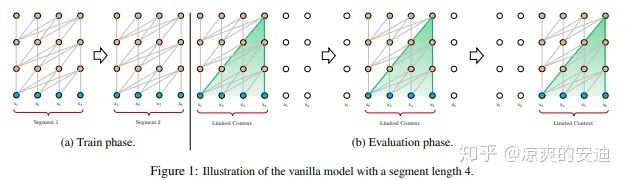
图8,Vanilla Attention处理长程依赖
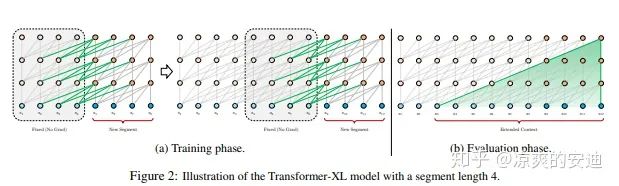
图9,Transformer-XL处理长程依赖
Transfomer-XL只能用于单向语言建模,后续在XLNet(效果优于Bert)中,为了使其可以解决双向上下文的建模的问题,作者提出了排列语言模型。
4. What's more
4.1 从“信息”层面
4.1.1 信息采集的区域——Global Attention VS Local Attention
Global Attention将会计算Q与所有K的相似性关系,并对所有Value进行加权,而Local Attention会先定位到一定的窗口,然后再对窗口内的K计算相似性关系,对窗口内的Value进行加权。
4.1.2 信息的线性——线性加权信息 VS 非线性加权信息
我们的“朴素的”Attention模型,如Hierarchical Attention Networks中的Attention中其实只是对信息V进行了线性的加权。
反观Self-Attention中,每个V都会通过全连接(非线性地)映射到一个新的空间,然后在根据Q与K的相似性进行加权,这种先将Value非线性映射后再加权的方式是不是好呢?我们不得而知,这个选择需要结合具体任务来实践。
4.1.3 信息的交互性
在推荐领域,从最早的LR模型只能提取一阶特征,并依靠经验进行二阶的特征组合;到FM模型提取二阶特征;再到DCN、xDeepFM等号称可以显式提取高阶特征的推荐模型,我们可以发现,在推荐领域非常在意特征交互。
在Attention中,不同V在进行加权之前,Q和V在计算相似性之前,进行信息和特征的交互是否是有用的呢?我们不得而知,也需要结合具体任务来实践。
在DIN中,广告信息和用户侧信息在进行Attention之前有一个out product的操作,然后将广告信息,用户侧信息,Product信息三者Concat在一起之后,进行Attention。这个操作的效果笔者暂时没有考虑清楚,有熟悉的小伙伴可以在评论区进行讨论~
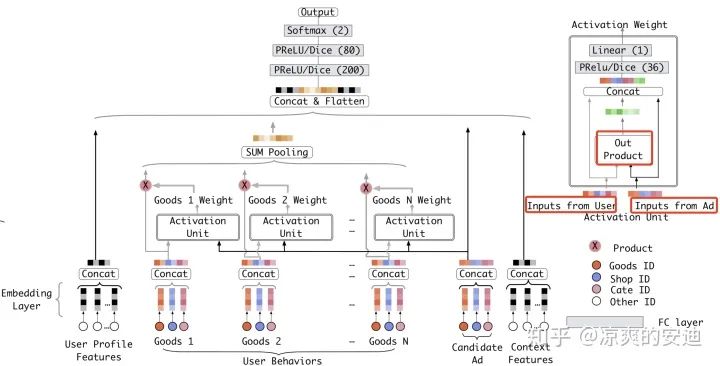
图10,DIN模型
4.2 从“加权融合”层面
4.2.1 权重的计算方法
关于Q和K相似度的计算方法,这里有一份总结,我觉得还不错,大家可以参考一下。
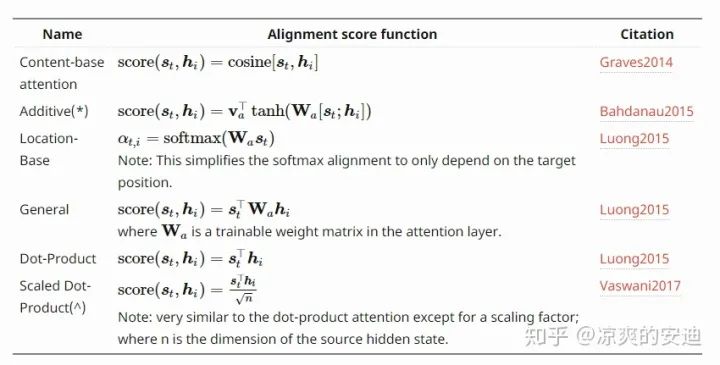
图11,Attention相似度计算方式,https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html#summary
5. 总结
Attention机制的本质就是对信息进行更好地加权融合。 信息可以用非线性进行变换,QKV之间可以进行特征交互,可以选择加权信息的区域。 在加权融合的时候可以采用多种方式计算相似度
这就是本文核心的三句话啦,读完本文之后,你理解了么~
参考文献
Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1930-1939.
Yang Z, Yang D, Dyer C, et al. Hierarchical attention networks for document classification[C]//Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies. 2016: 1480-1489.
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
Li J, Tu Z, Yang B, et al. Multi-head attention with disagreement regularization[J]. arXiv preprint arXiv:1810.10183, 2018.
Vig J. A multiscale visualization of attention in the transformer model[J]. arXiv preprint arXiv:1906.05714, 2019.
Song, Weiping, et al. "Autoint: Automatic feature interaction learning via self-attentive neural networks."Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019.
Dai Z, Yang Z, Yang Y, et al. Transformer-xl: Attentive language models beyond a fixed-length context[J]. arXiv preprint arXiv:1901.02860, 2019.
Tang G, Müller M, Rios A, et al. Why self-attention? a targeted evaluation of neural machine translation architectures[J]. arXiv preprint arXiv:1808.08946, 2018
Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1059-1068.
https://spaces.ac.cn/archives/4765/comment-page-1
为什么Transformer 需要进行 Multi-head Attention?
https://zhuanlan.zhihu.com/p/106662375
Attention? Attention!
推荐阅读
