
CVPR2020 夜间目标检测挑战赛冠军方案解读
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转载自DeepBlue深兰科技。
在 CVPR 2020 Workshop 举办的 NightOwls Detection Challenge 中,来自国内团队深兰科技的 DeepBlueAI 团队斩获了“单帧行人检测”和“多帧行人检测”两个赛道的冠军,以及“检测单帧中所有物体”赛道的亚军。


Pedestrian Detection from a Single Frame (same as 2019 competition) Pedestrian Detection from a Multiple Frames All Objects Detection (pedestrian, cyclist, motorbike) from a Single Frame

模型效果评估使用的是行人检测中常用的指标Average Miss Rate metric,但是仅考虑高度 > = 50px 的非遮挡目标。

运动模糊和图像噪点
与常规检测数据集不同,该竞赛考虑到实际驾驶情况,所用数据是在车辆行进过程中采集的,所以当车速较快或者有相对运动的时候会产生持续的运动模糊图像。并且由于摄像头是普通的RGB相机,因此在光线较弱的环境下收集的图片质量大幅度下降,这也是影响模型效果的主要原因。
对比度差异大,色彩信息少
不同的数据分布


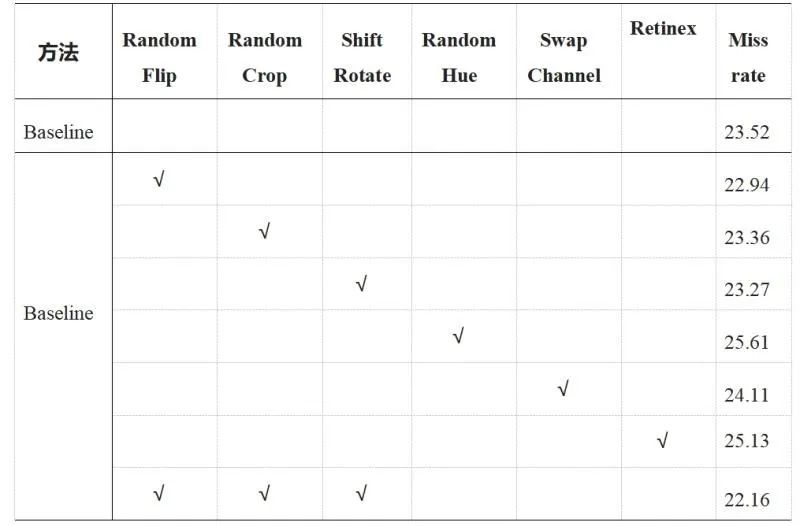
Baseline = Backbone + DCN + FPN + Cascade + anchor ratio (2.44)

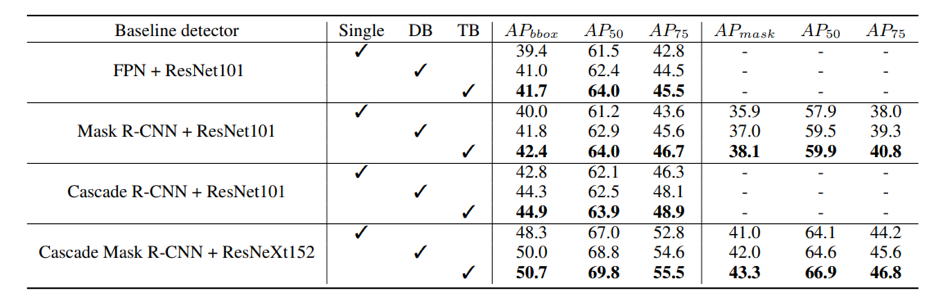
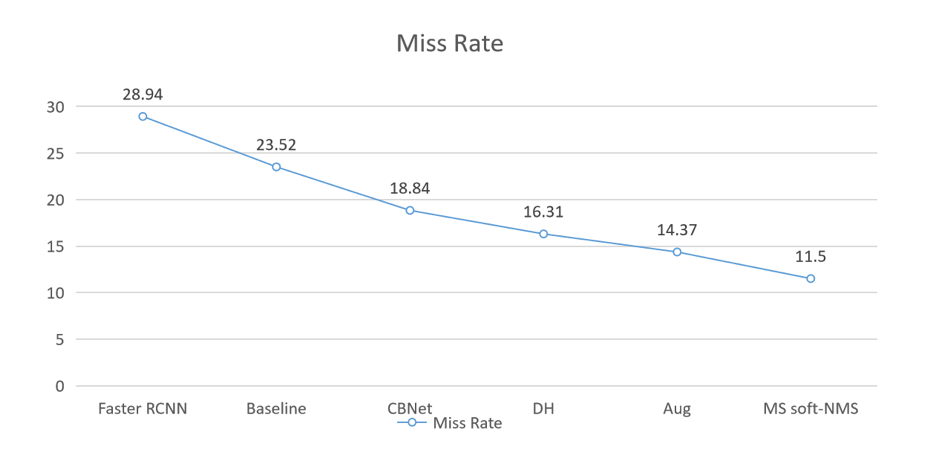
1. 将 Cascade rcnn + DCN + FPN 作为 baseline;
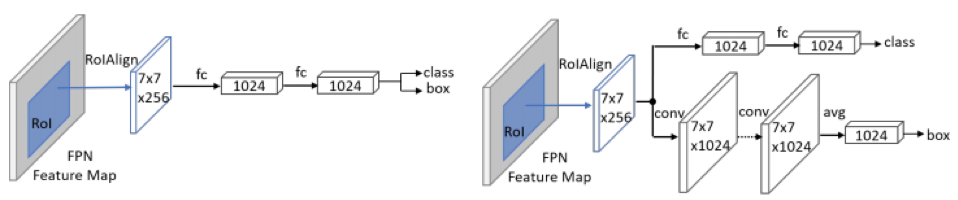
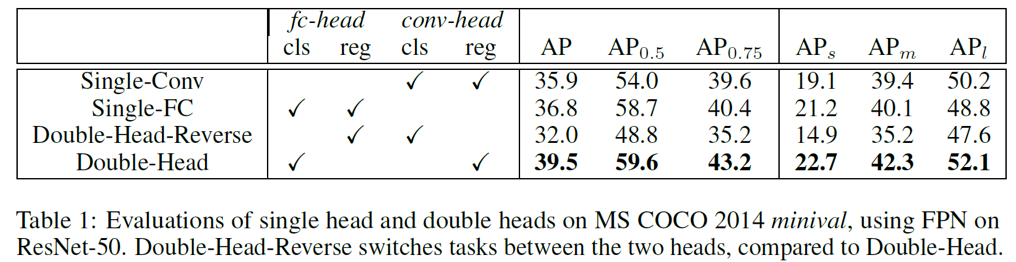
2. 将原有 head 改为 Double head;
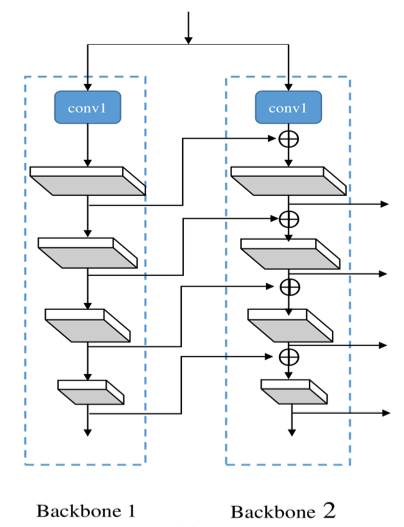
3. 将 CBNet 作为 backbone;
4. 使用 cascade rcnn COCO-Pretrained weight;
5. 数据增强;
6. 多尺度训练 + Testing tricks。
参考文献:
评论