
华为AI再进化,CANN 3.0释放「算力狂魔」

新智元报道
新智元报道
编辑:白峰、梦佳
【新智元导读】如今,AI已经进入了全面落地的阶段,但未来想要让AI真正像水和电一样无处不在,还面临着巨大的鸿沟。为了解决算力成本高、模型开发效率低的问题,华为专门设计了异构计算架构CANN 3.0。
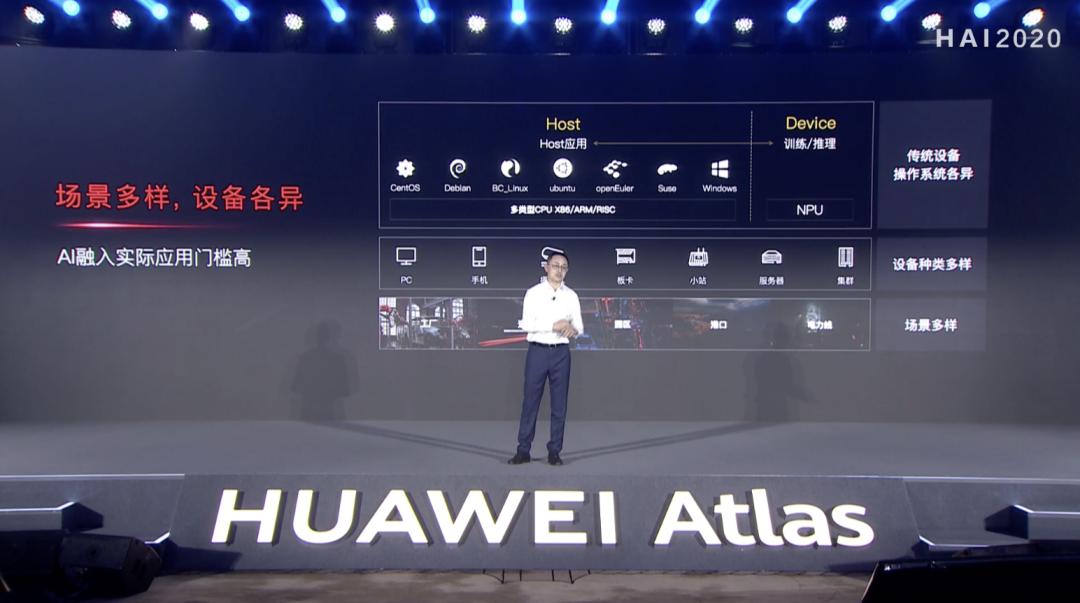
华为的野望:异构计算架构CANN 3.0,全场景AI走起

如何释放算力狂魔?指挥官CANN 3.0还可以「上下兼容」

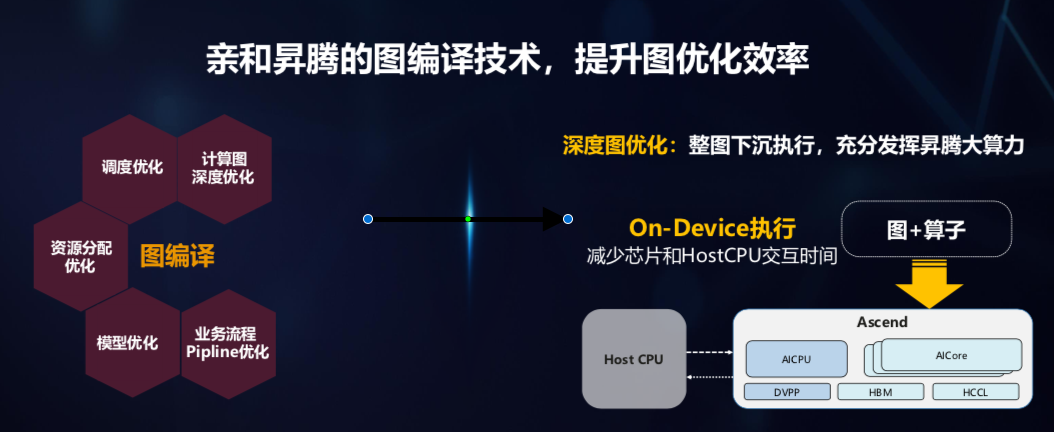
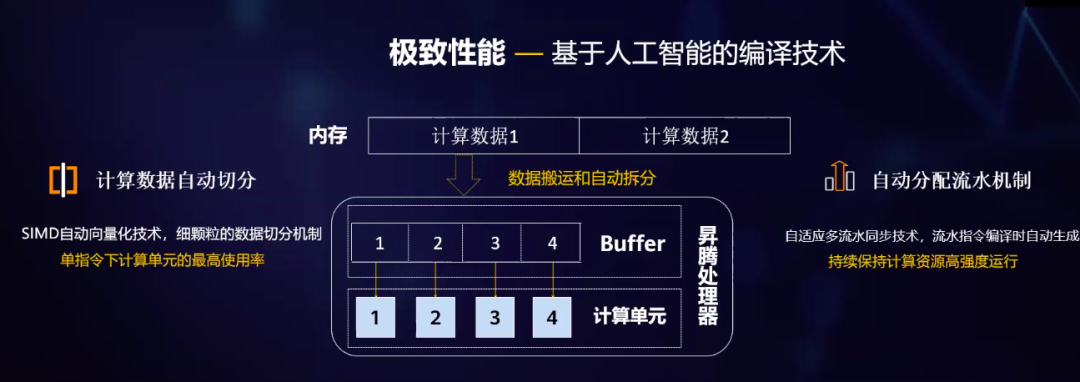
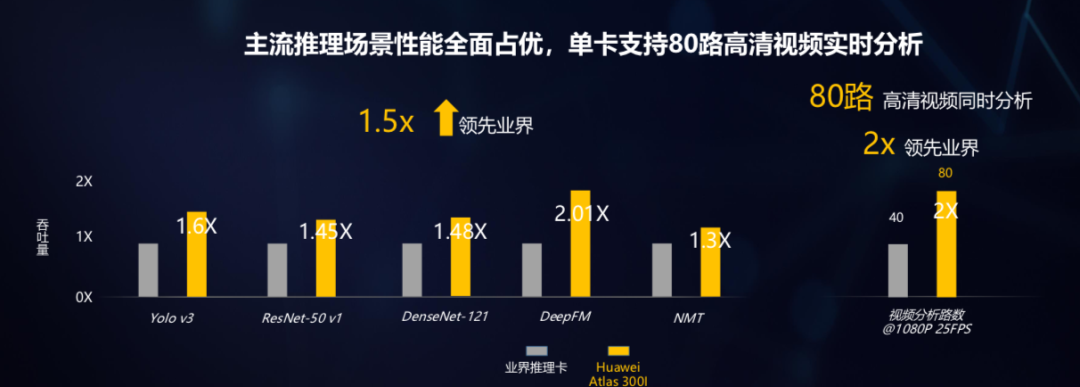
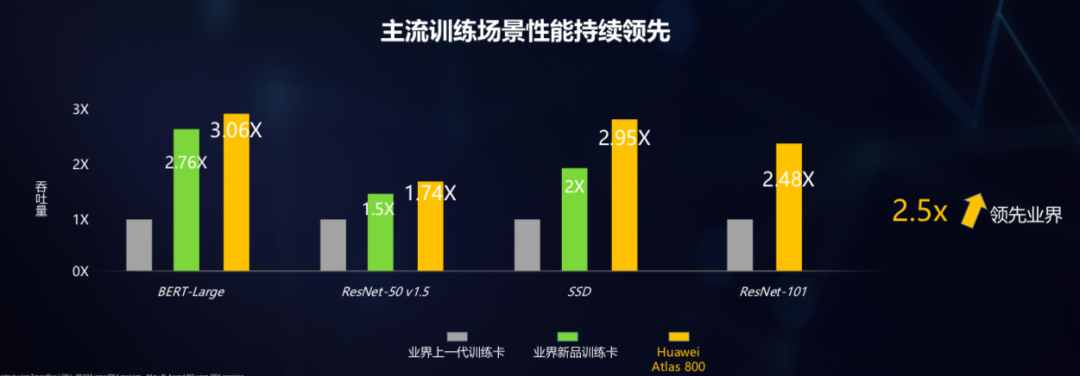
CANN「不是一个人在战斗」,还有开发者的AK47





评论