
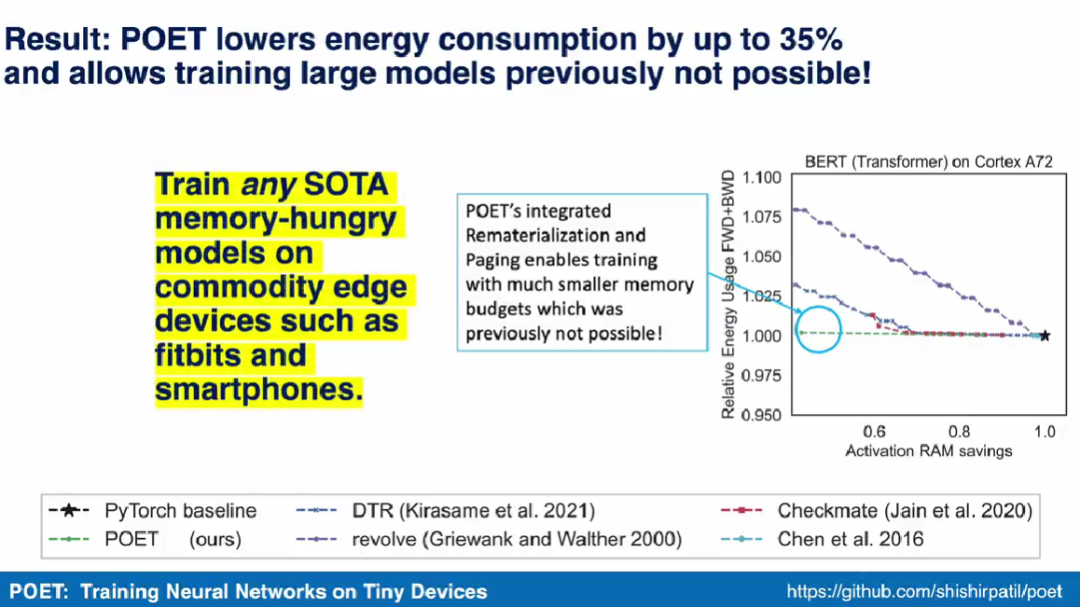
首次在智能手机上训练BERT和ResNet,能耗降35%
视学算法报道
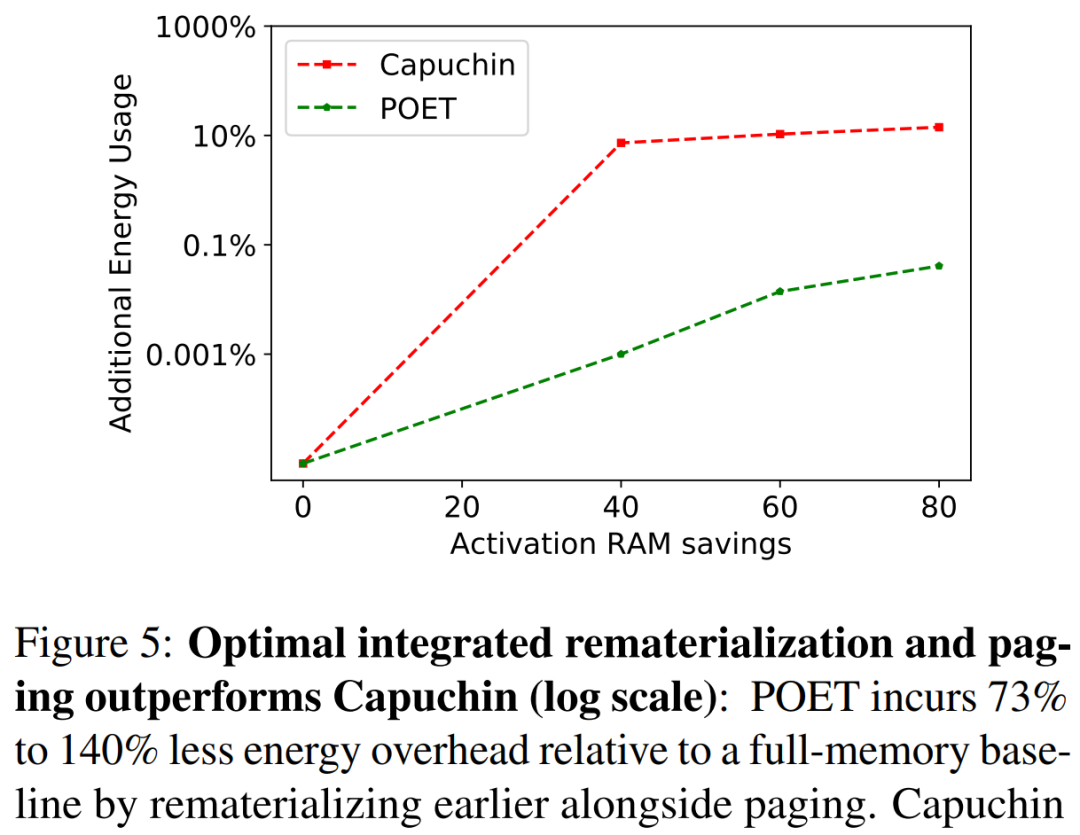
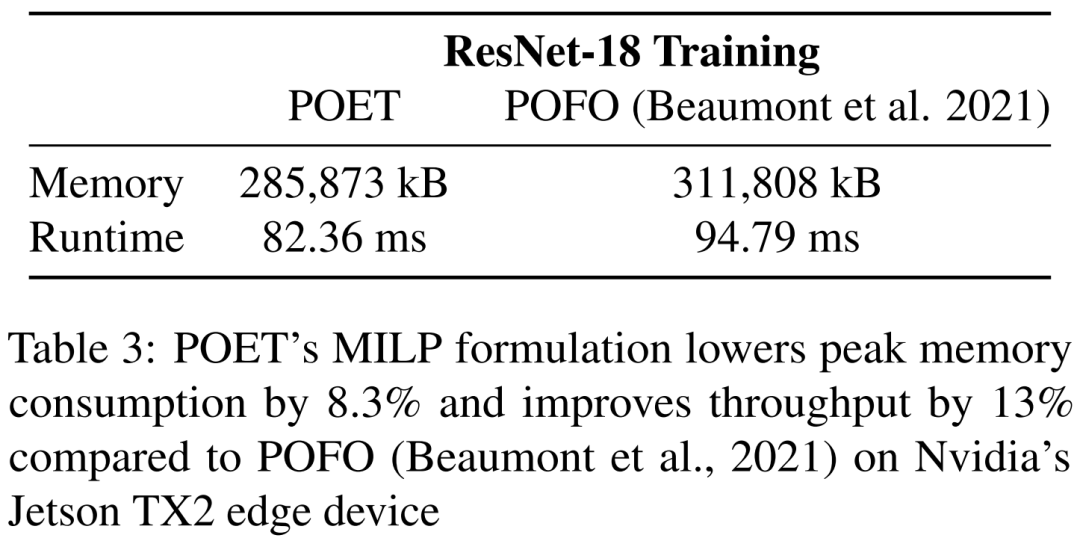
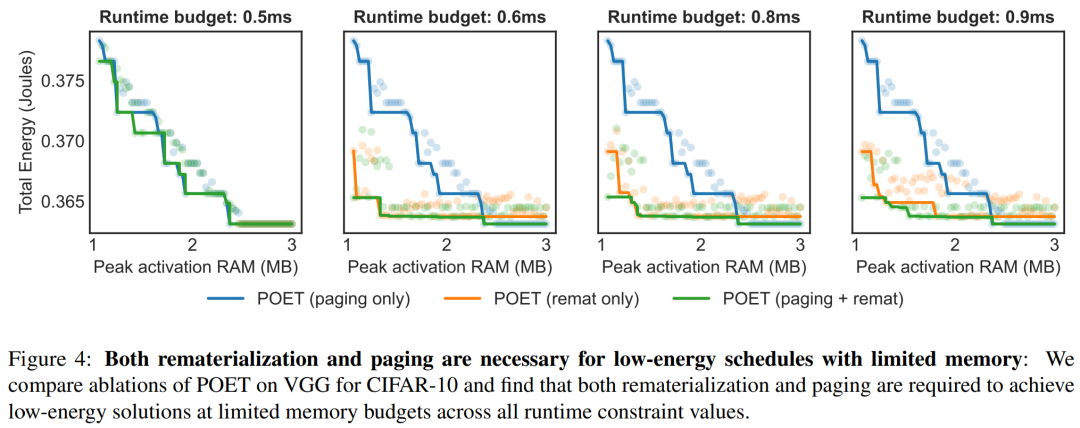
研究者表示,他们将边缘训练看作一个优化问题,从而发现了在给定内存预算下实现最小能耗的最优调度。


论文地址:https://arxiv.org/pdf/2207.07697.pdf 项目主页:https://poet.cs.berkeley.edu/ GitHub 地址:https://github.com/shishirpatil/poet
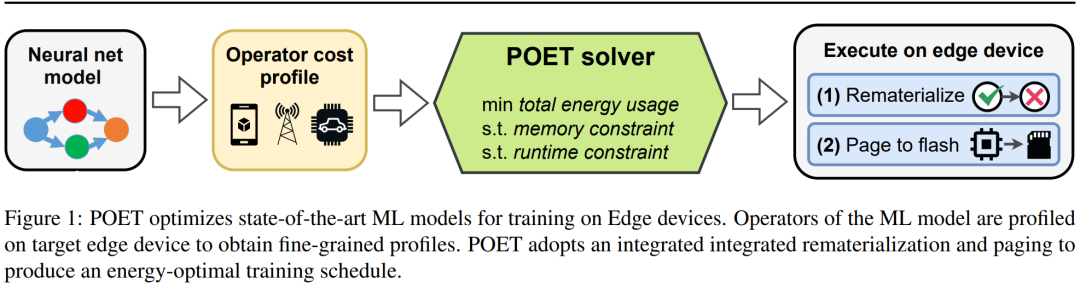
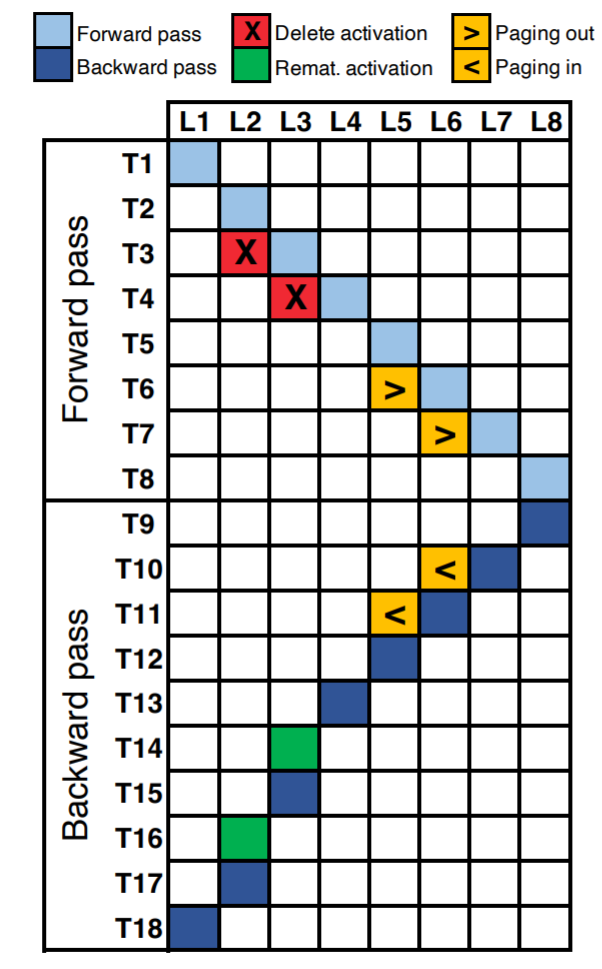

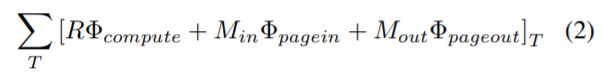
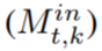 或 page-out
或 page-out 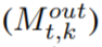 来输出 DAG 调度。
来输出 DAG 调度。
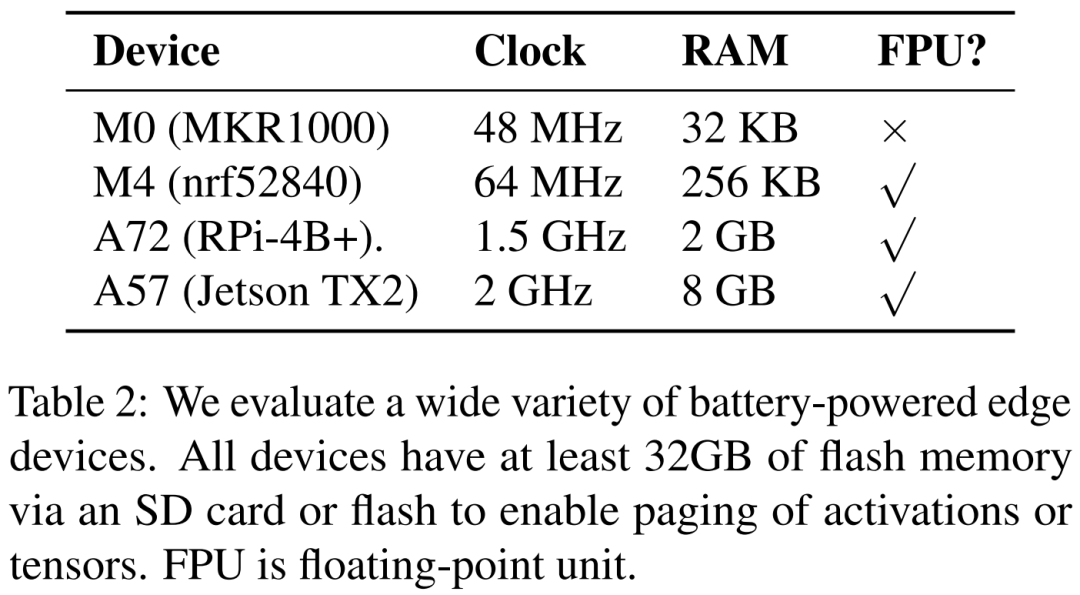
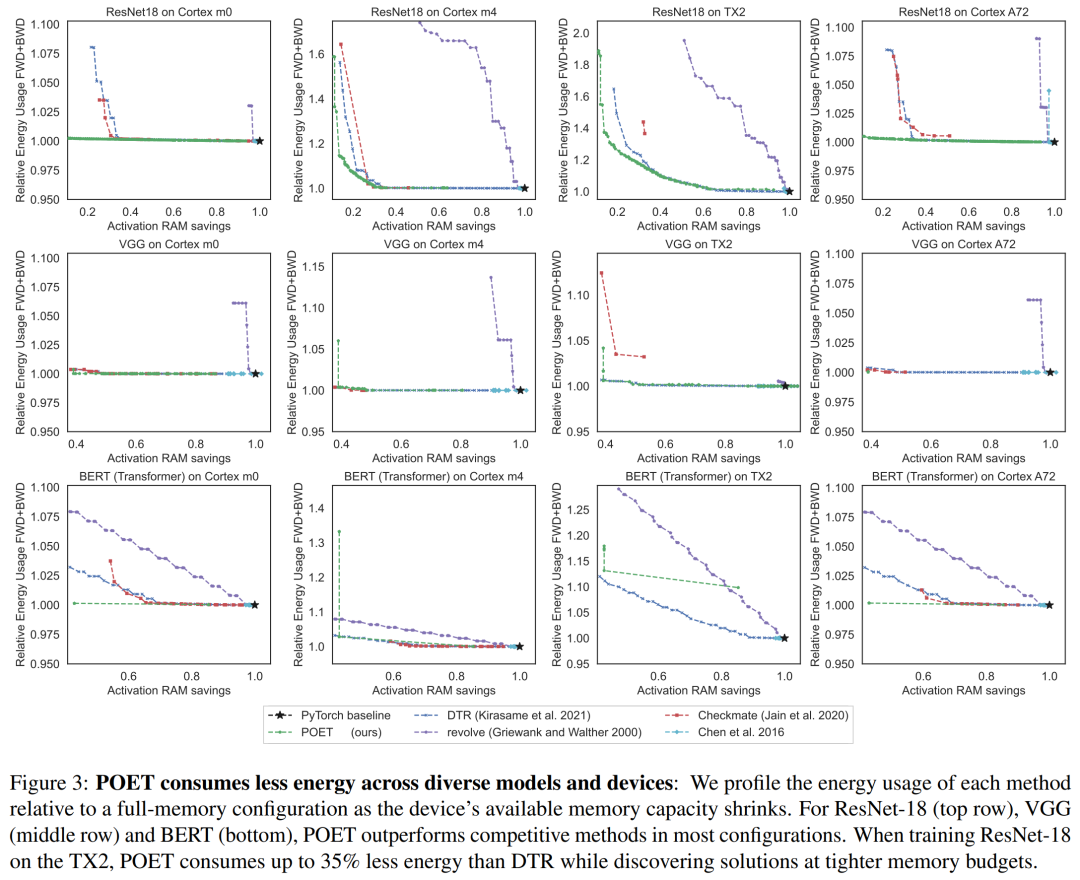
© THE END
转载请联系原公众号获得授权

点个在看 paper不断!
评论