
DeiT比ResNet强在哪里?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
Facebook提出的DeiT解决了谷歌的ViT所需大量的训练数据的问题,DeiT通过特殊的训练策略在ImageNet上取得了较好的性能,而且在相似的模型大小(参数量和FLOPs)要优于ResNet。近期北邮的一篇研究?Visformer系统地研究了DeiT和ResNet的差异,这篇论文通过将DeiT逐步地转换成ResNet来分析模型的差异,并相应地提出了性能更优的Visformer模型。
这里以DeiT-S和ResNet-50为例,两者的参数量和FLOPs,但是DeiT-S在ImageNet上的top1 acc达到了80.07,而ResNet50只有77.43。不过DeiT采用了特殊的训练策略,而ResNet50的训练策略比较简单:采用SDG优化器,训练epochs为90,数据增强只包括随机裁剪(random-size cropping)和水平翻转(flip horizontal),这个是CNN模型标准的训练策略。而相比之下,DeiT需要复杂的训练策略:采用AdamW优化器,训练epochs为300,更强的数据增强(RandAugment和CutMix等)等,那么在不同的训练策略下对比两者的性能显然是有失公允的。在论文中,CNN常用的训练策略称为base setting,而DeiT所用的训练策略称为elite setting,后者要比前者更heavy。如果ResNet50也采用elite setting,其性能提升至78.73,但是还是低于DeiT;如果DeiT-S采用base setting,其性能下降比较厉害,掉到了63.12,这个远低于ResNet50。如果两者策略分别代表模型上下限的话,那说明DeiT的上限要高于ResNet,但下限要远低于ResNet。另外论文还对比只用10% label和10% classes部分数据下DeiT和ResNet的性能差异,结果表明DeiT要差于ResNet。这其实也说明在小数据或者常规训练模式下,ResNet更有优势。
为了分析ResNet和DeiT的性能差异,论文将DeiT模型逐步转化成ResNet模型,这里共包含8个步骤来转换,这里可以看到每个部分对性能的影响: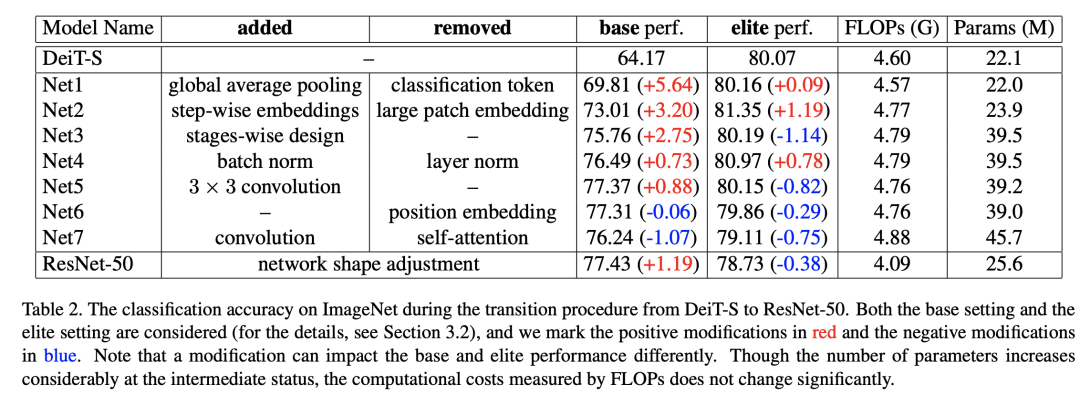
Global average pooling
DeiT采用的是class token来进行最后的分类,但是CNN模型基本是对提出的特征做global average pooling(GAP)然后分类,那么用GAP替换掉class token,可以看到DeiT的base性能(base setting下)大幅度提升(5%+),同时elite性能(elite setting下)略有提升。这说明GAP在常规训练策略下对模型性能比较重要。
Step-wise patch embedding
DeiT最开始是一个patch embedding,将图像转换成patch tokens,这操作等价于一个卷积,比如16x16大小的patch就等价于采用一个stride和kernel size均为16的卷积,这相当于直接对图像进行很大的downsample。由于采用较大的patch,这可能导致patch内部的信息可能有损失。而CNN网络常是逐渐对图像downsample的。所以类似ResNet的stem layer(res block前面的部分),将DeiT也改成step-wise small patch embedding。首先是一个stride为2的7x7卷积,然后是一个stride为4的4x4卷积和一个stride为2的2x2卷积,这样经过patch embedding后得和DeiT-S-16一样,都是提取的16x16大小的pach特征。不过ResNet50通过stem之后提取得是下采样为1/4的特征。此外,在最后也增加了一个stride为2的2x2卷积得到下采样为1/32的特征来进行分类,这和ResNet保持一致。这个变动可以看到base性能和elite性能均有明显的提升(这个转变额外增加4%的FLOPs)。其实关于patch embedding,?Mocov3也指出对无监督训练的稳定性影响较大,所以提出采用fixed random patch embedding来增强稳定性;此外,Facebook最新的论文?Early Convolutions Help Transformers See Better也指出在ViT的前面采用几个卷积层对性能和稳定性(Training length stability,Optimizer stability,Hyperparameter (lr, wd) stability)都有帮助:
Stages-wise design
DeiT在patch embedding之后接的都是相同的transformer block,而ResNet是包含不同的stage的,每个stage包含相同的res blocks,一般每个stage会对特征下采样2倍,这是一种金字塔结构(目前已经有基于local attention的金字塔vision transformer模型,如Swin Transformer可以取得很好的性能)。这个第三个转换就是将DeiT也变成stage-wise,在前面step-wise patch embedding基础上,将transformer block分别在 8 × 8, 16 × 16和32 × 32 patch embedding stages插入(各1/3),为了保证相似的FLOPs,在8x8 patch embedding时将特征维度降低一半。转变成stage-wise后,模型的base性能有较大的提升,但是elite性能下降超过1个点,这个下降的原因,论文也做了额外的实验,发现主要是在前面的stage(较大的分辨率,tokens较多)采用self-attention会性能带来较大的影响。
BatchNorm
对于transformer模型常采用的是LayerNorm,而CNN采用BatchNorm,这第4个变动就是用BatchNorm替换LayerNorm,这个改动后模型的base性能和elite性能就有提升。另外,论文也做了另外一个实验,就是在Net2上也做这个变动,发现模型收敛困难,对于Net2模型的主体还是transformer blocks,这说明替换BatchNorm对纯transformer模型并不太有效。
3 × 3 Conv
对于transformer block中的MLP,虽然看起来是FC层,但是其实是两个1x1卷积层(把tokens和pixels等同),而ResNet中更多的是采用3x3卷积,3x3卷积可以有效地提取局部信息。这次的变动是在MLP的两个1x1卷积层间增加一个3x3卷积,由于MLP本身也是残差结构,这样MLP其实就变成了和res bottleneck block基本一样了。这里为了保持计算量,也需要合理设置bottleneck ratios(3x3卷积层的输入特征维度降低ratio,代码实现中是in_features*5//6)。这个改动继续提升了base性能,但是elite性能下降了0.82,论文中额外做了实验,即单独的在各个stage改为3x3卷积,最后发现只有在前面的stage这个才比较有效,而对于分辨率较低的后面的stage效果较差,这应该是前面的stage更需要引入局部信息。 之前提到的stage-wise的额外实验也是基于Net5,具体是分别用ResNet的bottleneck blocks替换各个stage的self-attention,结果发现虽然替换后性能均有所下降,但是后2个stage的替换导致elite性能下降较多,而第一个stage替换基本不影响性能,这说明第一个stage采用直接采用bottleneck blocks就好,这也可能是stage-wise后elite性能恶化的原因。
之前提到的stage-wise的额外实验也是基于Net5,具体是分别用ResNet的bottleneck blocks替换各个stage的self-attention,结果发现虽然替换后性能均有所下降,但是后2个stage的替换导致elite性能下降较多,而第一个stage替换基本不影响性能,这说明第一个stage采用直接采用bottleneck blocks就好,这也可能是stage-wise后elite性能恶化的原因。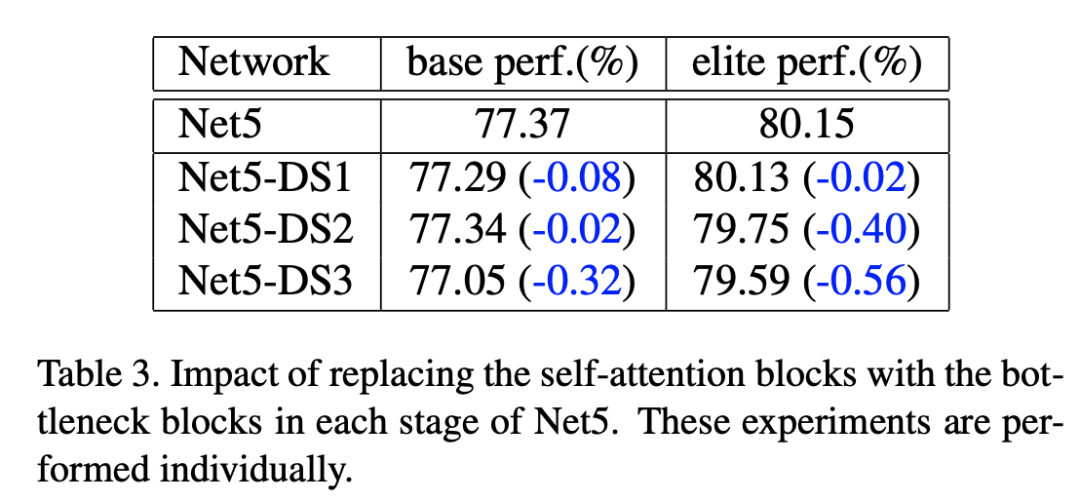
Remove position embedding
DeiT需要position embedding来引入tokens的位置信息,但是对于CNN来说是不需要的。美团的论文?Conditional Positional Encodings for Vision Transformers也指出只需要带有zero-padding的3x3卷积就可以隐式地编码位置信息。去掉position embedding后,模型性能只略有下降,这说明经过前面的改动(已经含有带有padding的卷积层),position embedding其实已经不再需要了。对于原始的DeiT来说,去掉position embedding其性能下降较多(-3.95%),这个影响在改动后基本消除了。
Replace self-attention
这最后一步就是将所有的self-attention用 bottleneck blocks来替换(替换后增加一些 bottleneck blocks来保持FLOPs),这样模型就变成纯粹的CNN了,也和ResNet50一样只包含 bottleneck blocks。替换self-attention后模型的base和elite性能均有下降,这说明self-attention对性能也比较重要,另外我们也看到模型的base性能其实已经提升很多了,这说明前面的那些因素才可能是影响base性能的主要因素。经过7次改动,模型已经接近ResNet50,但是还是有所区别:模型的depths, widths, bottleneck ratios和block numbers是不同的,且FLOPs也有所区别;ResNet50在每个卷积层都有BN,而改动的DeiT只有在每个block后有BN。相比原始的ResNet50,转变的模型的base性能差一些,但是elite性能更好。
Visformer
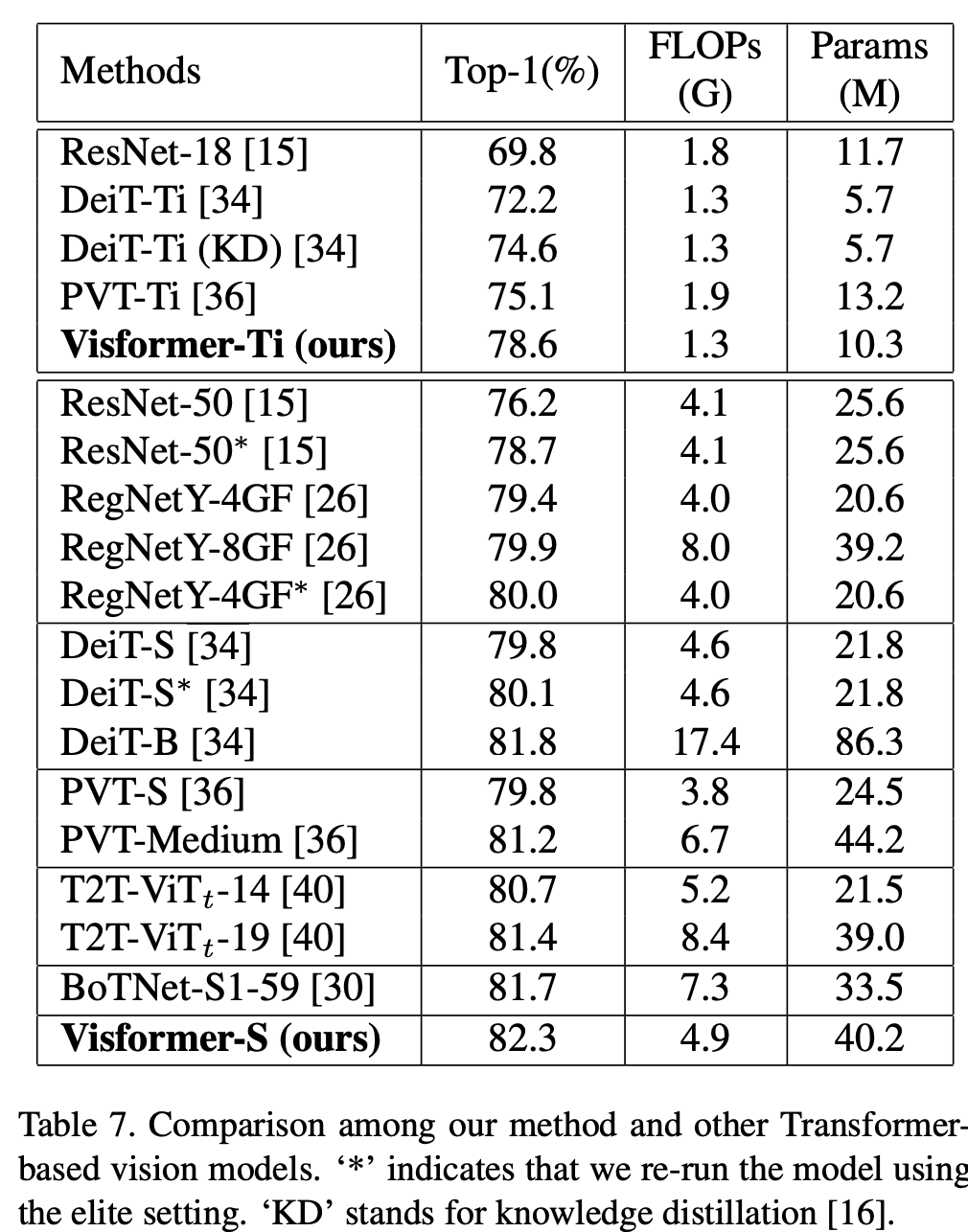
经过之前的分析,可以看到采用step-wise patch embedding和stage-wise设计对base性能提升是比较大的,另外在第一个stage可以采用卷积而不是self-attention,而后面的stage采用存粹的self-attention。故此,论文提出了visformer模型,其模型结构如下所示: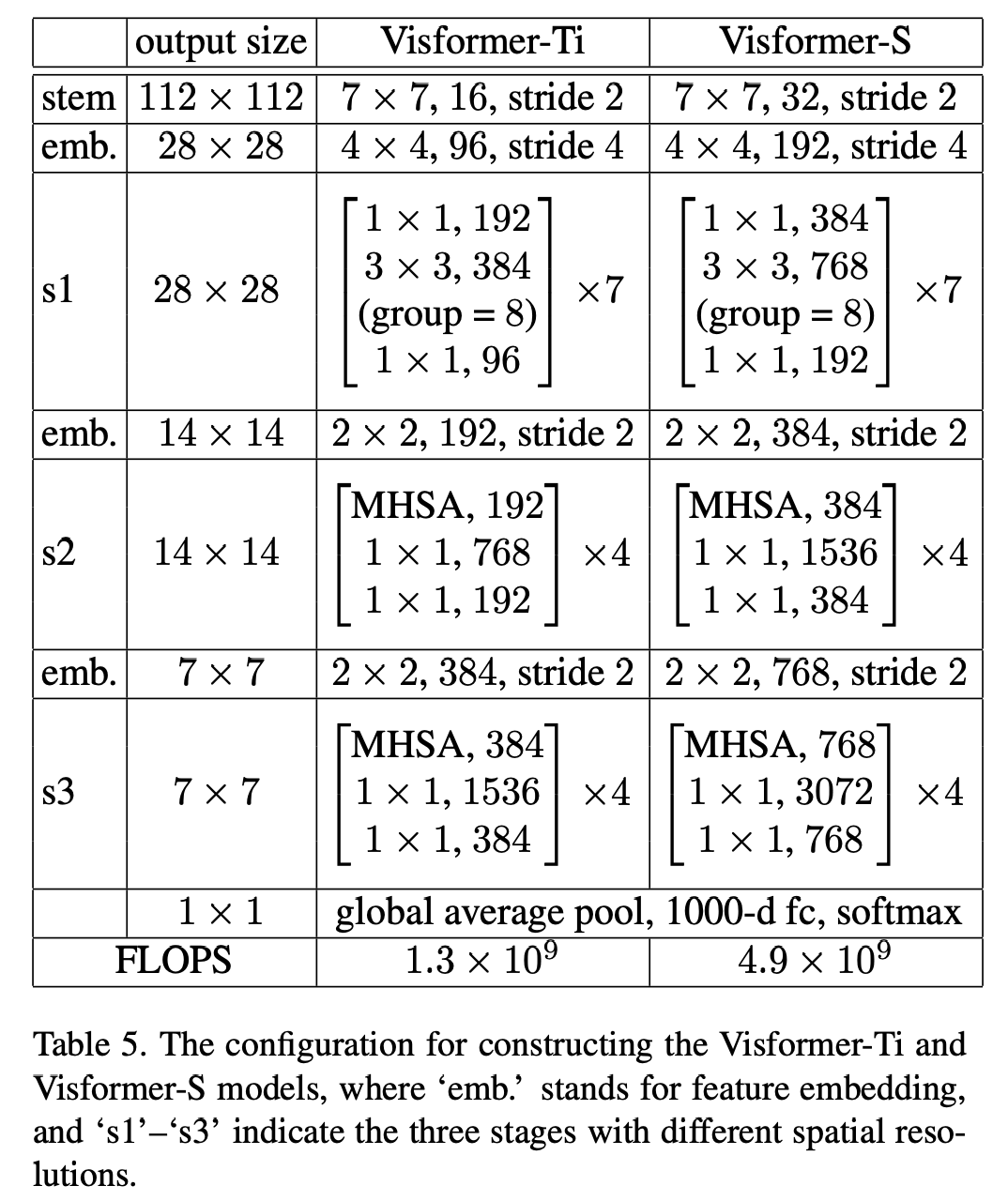 其模型效果如下所示,可以看到visformer-S模型效果超过了ResNet50和DeiT-S(其中FLOPs少量增加,但参数量增加了一倍),另外相比DeiT-S,visformer-S的base性能也大幅度提升。
其模型效果如下所示,可以看到visformer-S模型效果超过了ResNet50和DeiT-S(其中FLOPs少量增加,但参数量增加了一倍),另外相比DeiT-S,visformer-S的base性能也大幅度提升。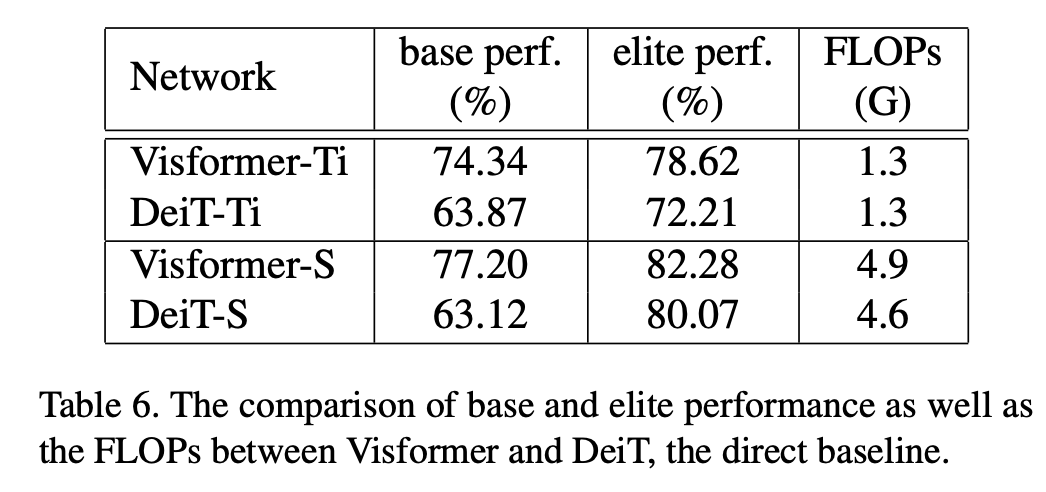
小结
visformer这篇论文更多的贡献是分析了ResNet和DeiT在不同训练策略下的差异,同时通过一步一步地转变找到各个设计对性能的影响,这些结论对改进ViT模型是有建设性意义的。其实,stage-wise设计以及GAP这些也已经在local-attention ViT模型中被证明有效。关于ViT,谷歌也有两篇论文-?How to train your ViT? Data, Augmentation,and Regularization in Vision Transformers 和?When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations也值得关注。
参考
?Visformer: The Vision-friendly Transformer
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
