
PyTorch 进阶之路:在 GPU 上训练深度神经网络
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

选自 | Medium
作者 | Aakash N S
参与| Panda
本文是该系列的第四篇,将介绍如何在 GPU 上使用 PyTorch 训练深度神经网络。
在之前的教程中,我们基于 MNIST 数据集训练了一个识别手写数字的 logistic 回归模型,并且达到了约 86% 的准确度。
但是,我们也注意到,由于模型能力有限,很难再进一步将准确度提升到 87% 以上。在本文中,我们将尝试使用前向神经网络来提升准确度。本教程的大部分内容受到了 Jeremy Howard 的 FastAI 开发笔记的启发:https://github.com/fastai/fastai_old/tree/master/dev_nb
如果你想一边阅读一边运行代码,你可以通过下面的链接找到本教程的 Jupyter Notebook:
https://jvn.io/aakashns/fdaae0bf32cf4917a931ac415a5c31b0
你可以克隆这个笔记,使用 conda 安装必要的依赖包,然后通过在终端运行以下命令来启动 Jupyter:
pip install jovian --upgrade # Install the jovian library
jovian clone fdaae0bf32cf4917a931ac415a5c31b0 # Download notebook
cd 04-feedforward-nn # Enter the created directory
jovian install # Install the dependencies
conda activate 04-feedfoward-nn # Activate virtual env
jupyter notebook # Start Jupyter
如果你的 conda 版本更旧一些,你也许需要运行 source activate 04-feedforward-nn 来激活虚拟环境。对以上步骤的更详细解释可参阅本教程的本系列教程第一篇文章。
这里的数据准备流程和前一篇教程完全一样。我们首先导入所需的模块和类。

我们使用 torchvision.datasets 的 MNIST 类下载数据并创建一个 PyTorch 数据集。

接下来,我们定义并使用一个函数 split_indices 来随机选取 20% 图像作为验证集。
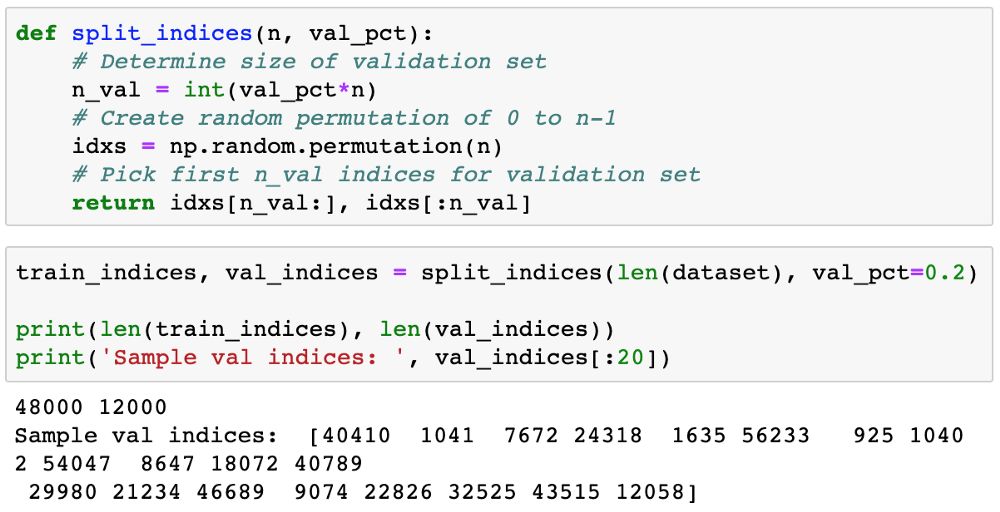
现在,我们可以使用 SubsetRandomSampler 为每个子集创建 PyTorch 数据加载器,它可从一个给定的索引列表中随机地采样元素,同时创建分批数据。

要在 logistic 回归的基础上实现进一步提升,我们将创建一个带有一个隐藏层(hidden layer)的神经网络。这是我们的做法:
我们不再使用单个 nn.Linear 对象将输入批(像素强度)转换成输出批(类别概率),而是将使用两个 nn.Linear 对象。其中每一个对象都被称为一层,而该模型本身则被称为一个网络。
第一层(也被称为隐藏层)可将大小为 batch_size x 784 的输入矩阵转换成大小为 batch_size x hidden_size 的中间输出矩阵,其中 hidden_size 是一个预配置的参数(比如 32 或 64)。
然后,这个中间输出会被传递给一个非线性激活函数,它操作的是这个输出矩阵的各个元素。
这个激活函数的结果的大小也为 batch_size x hidden_size,其会被传递给第二层(也被称为输出层)。该层可将隐藏层的结果转换成一个大小为 batch_size x 10 的矩阵,这与 logistic 回归模型的输出一样。
引入隐藏层和激活函数让模型学习输入与目标之间更复杂的、多层的和非线性的关系。看起来像是这样(蓝框表示单张输入图像的层输出):
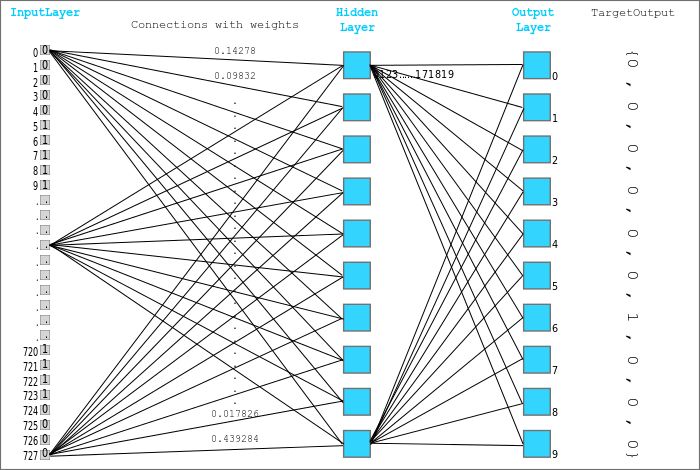
我们这里将使用的激活函数是整流线性单元(ReLU),它的公式很简单:relu(x) = max(0,x),即如果一个元素为负,则将其替换成 0,否则保持不变。
为了定义模型,我们对 nn.Module 类进行扩展,就像我们使用 logistic 回归时那样。

我们将创建一个带有 32 个激活的隐藏层的模型。

我们看看模型的参数。可以预见每一层都有一个权重和偏置矩阵。

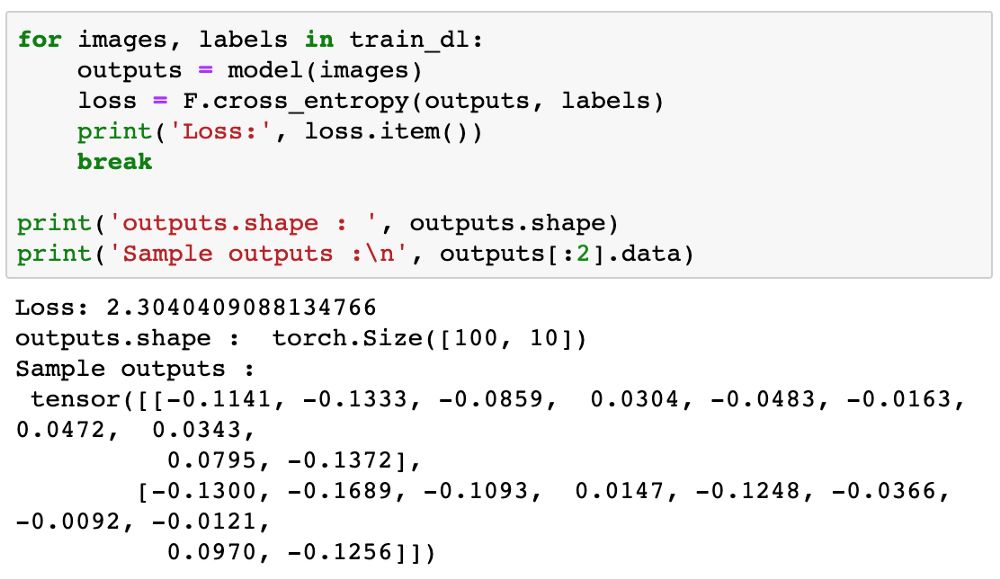
我们试试用我们的模型生成一些输出。我们从我们的数据集取第一批 100 张图像,并将其传入我们的模型。
随着我们的模型和数据集规模增大,为了在合理的时间内完成模型训练,我们需要使用 GPU(图形处理器,也被称为显卡)来训练我们的模型。GPU 包含数百个核,这些核针对成本高昂的浮点数矩阵运算进行了优化,让我们可以在较短时间内完成这些计算;这也因此使得 GPU 非常适合用于训练具有很多层的深度神经网络。你可以在 Kaggle kernels 或 Google Colab 上免费使用 GPU,也可以租用 Google Cloud Platform、Amazon Web Services 或 Paperspace 等 GPU 使用服务。你可以使用 torch.cuda.is_available 检查 GPU 是否可用以及是否已经安装了所需的英伟达驱动和 CUDA 库。

我们定义一个辅助函数,以便在有 GPU 时选择 GPU 为目标设备,否则就默认选择 CPU。

接下来,我们定义一个可将数据移动到所选设备的函数。

最后,我们定义一个 DeviceDataLoader 类(受 FastAI 的启发)来封装我们已有的数据加载器并在读取数据批时将数据移动到所选设备。有意思的是,我们不需要扩展已有的类来创建 PyTorch 数据加载器。我们只需要用 __iter__ 方法来检索数据批并使用 __len__ 方法来获取批数量即可。

我们现在可以使用 DeviceDataLoader 来封装我们的数据加载器了。

已被移动到 GPU 的 RAM 的张量有一个 device 属性,其中包含 cuda 这个词。我们通过查看 valid_dl 的一批数据来验证这一点。

和 logistic 回归一样,我们可以使用交叉熵作为损失函数,使用准确度作为模型的评估指标。训练循环也是一样的,所以我们可以复用前一个教程的 loss_batch、evaluate 和 fit 函数。
loss_batch 函数计算的是一批数据的损失和指标值,并且如果提供了优化器就可选择执行梯度下降。
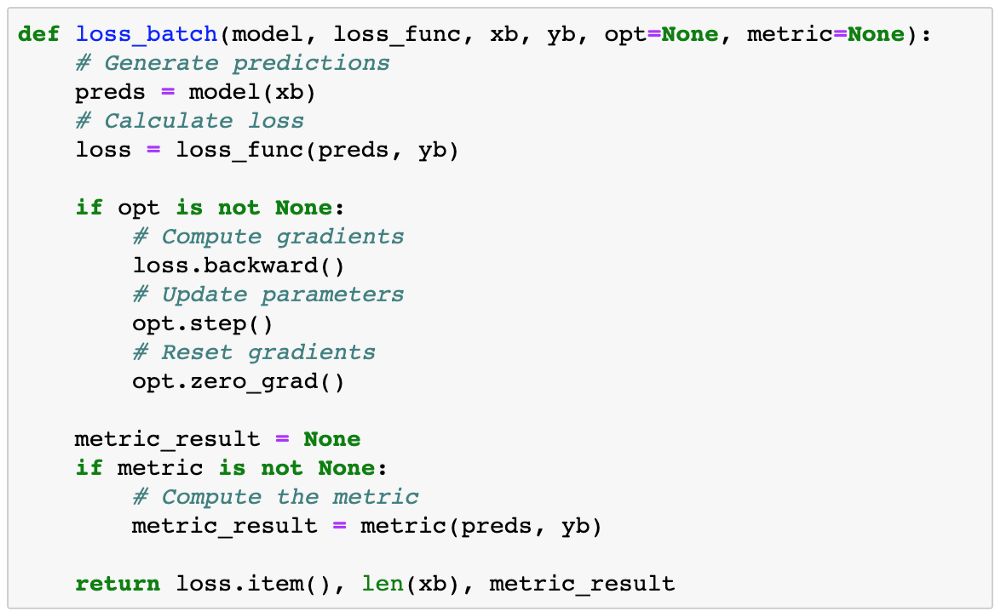
evaluate 函数是为验证集计算整体损失(如果有,还计算一个指标)。

和之前教程中定义的一样,fit 函数包含实际的训练循环。我们将对 fit 函数进行一些改进:
我们没有人工地定义优化器,而是将传入学习率并在该函数中创建一个优化器。这让我们在有需要时能以不同的学习率训练模型。
我们将记录每 epoch 结束时的验证损失和准确度,并返回这个历史作为 fit 函数的输出。

我们还要定义一个 accuracy 函数,其计算的是模型在整批输出上的整体准确度,所以我们可将其用作 fit 中的指标。

在我们训练模型之前,我们需要确保数据和模型参数(权重和偏置)都在同一设备上(CPU 或 GPU)。我们可以复用 to_device 函数来将模型参数移至正确的设备。

我们看看使用初始权重和偏置时,模型在验证集上的表现。

初始准确度大约是 10%,这符合我们对随机初始化模型的预期(其有十分之一的可能性得到正确标签)。
现在可以开始训练模型了。我们先训练 5 epoch 看看结果。我们可以使用相对较高的学习率 0.5。
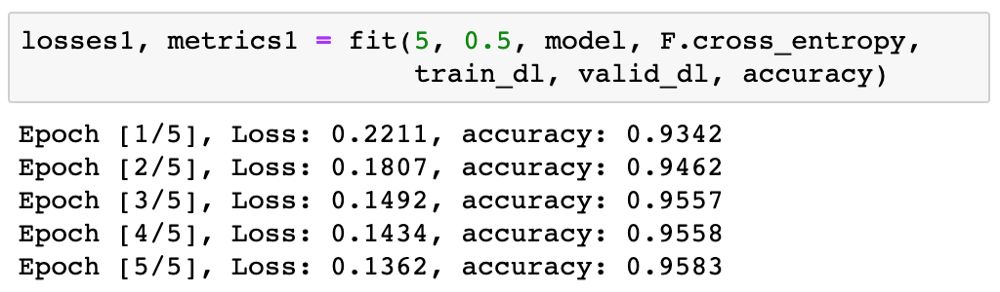
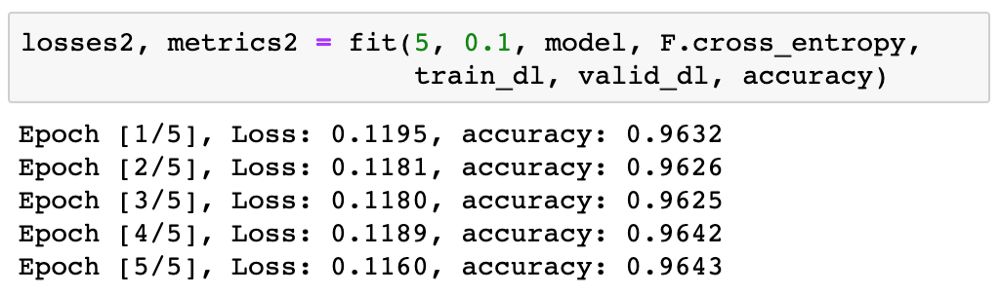
95% 非常好了!我们再以更低的学习率 0.1 训练 5 epoch,以进一步提升准确度。
现在我们可以绘制准确度图表,看看模型随时间的提升情况。
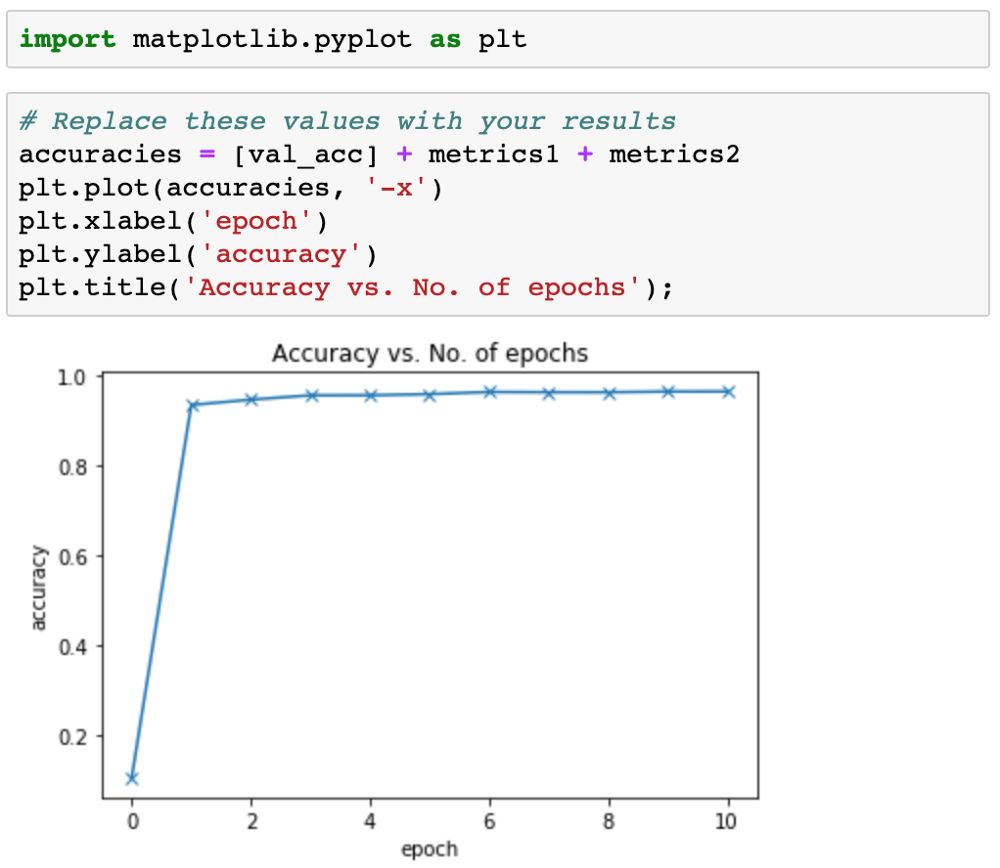
我们当前的模型极大地优于 logistic 模型(仅能达到约 86% 的准确度)!它很快就达到了 96% 的准确度,但没能实现进一步提升。如果要进一步提升准确度,我们需要让模型更加强大。你可能也已经猜到了,通过增大隐藏层的规模或添加更多隐藏层可以实现这一目标。
最后,我们可以使用 jovian 库保存和提交我们的成果。
jovian 会将笔记上传到 https://jvn.io,并会获取其 Python 环境并为该笔记创建一个可分享的链接。你可以使用该链接共享你的成果,让任何人都能使用 jovian 克隆命令轻松复现它。jovian 还有一个强大的评论接口,让你和其他人都能讨论和点评你的笔记的各个部分。
本教程涵盖的主题总结如下:
我们创建了一个带有一个隐藏层的神经网络,以在前一个教程的 logistic 回归模型基础上实现进一步提升。
我们使用了 ReLU 激活函数来引入非线性,让模型可以学习输入和输出之间的更复杂的关系。
我们定义了 get_default_device、to_device 和 DeviceDataLoader 等一些实用程序,以便在可使用 GPU 时利用它,并将输入数据和模型参数移动到合适的设备。
我们可以使用我们之前定义的同样的训练循环:fit 函数,来训练我们的模型以及在验证数据集上评估它。
其中有很多可以实验的地方,我建议你使用 Jupyter 的交互性质试试各种不同的参数。这里有一些想法:
试试修改隐藏层的大小或添加更多隐藏层,看你能否实现更高的准确度。
试试修改批大小和学习率,看你能否用更少的 epoch 实现同样的准确度。
比较在 CPU 和 GPU 上的训练时间。你看到存在显著差异吗?数据集的大小和模型的大小(权重和参数的数量)对其有何影响?
试试为不同的数据集构建模型,比如 CIFAR10 或 CIFAR100 数据集。
最后,分享一些适合进一步学习的好资源:
神经网络可以计算任何函数的视觉式证明,也被称为通用近似定理:http://neuralnetworksanddeeplearning.com/chap4.html
神经网络究竟是什么?——通过视觉和直观的介绍解释了神经网络以及中间层所表示的内容:https://www.youtube.com/watch?v=aircAruvnKk
斯坦福大学 CS229 关于反向传播的讲义——更数学地解释了多层神经网络计算梯度和更新权重的方式:http://cs229.stanford.edu/notes/cs229-notes-backprop.pdf
吴恩达的 Coursera 课程:关于激活函数的视频课程:https://www.coursera.org/lecture/neural-networks-deep-learning/activation-functions-4dDC1
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~