
最强辅助Visualizer:简化你的Vision Transformer可视化!
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
©作者 | 洛英
Visualizer 是一个辅助深度学习模型中 Attention 模块可视化的小工具,主要功能是帮助取出嵌套在模型深处的 Attention Map。
为了可视化 Attention Map,你是否有以下苦恼:
1. Return 大法好:通过 return 将嵌套在模型深处的 Attention Map 一层层地返回回来,然后训练模型的时候又不得不还原;
2. 全局大法好:使用全局变量在 Attention 函数中直接记录 Attention Map,结果训练的时候忘改回来导致 OOM。
不管你有没有,反正我有,由于可视化分析不是一锤子买卖,实际过程中你往往需要在训练-可视化-训练-可视化两种状态下反复横跳,所以不适合采用以上两种方式进行可视化分析。

PyTorch hook 的局限性
handle = net.conv2.register_forward_hook(hook)
这样我们就可以拿出来 net.conv2 这层的输出啦。
然而!进行这样操作的前提是我们知道要取出来的模块名,但是 Transformer 类模型一般是这样定义的(以 Vit 为例)。
class VisionTransformer(nn.Module):
def __init__(self, *args, **kwargs):
...
self.blocks = nn.Sequential(*[Block(...) for i in range(depth)])
...然后每个 Block 中都有一个 Attention 。
class Block(nn.Module):
def __init__(self, *args, **kwargs):
...
self.attn = Attention(...)
...然后我们想要的 attention map 又在 Attention 里面。
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
...
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn) # <-在这
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x1. 嵌套太深,模块名不清晰,我们根本不知道我们要取的 attention map 怎么以 model.bla.bla.bla 这样一直点出来!
2. 一般来说,Transformer 中 attention map 每层都有一个,一个个注册实在太麻烦了。
那怎么办呢....
Visualizer!
所以我就思考并查找能否通过更简洁的方法来得到 Attention Map(尤其是 Transformer 的),而 visualizer 就是其中的一种,它具有以下特点:
精准直接,你可以取出任何变量名的模型中间结果;
快捷方便,一个操作,就可以同时取出 Transformer 类模型中的所有 attention map;
非侵入式,你无须修改函数内的任何一行代码;
训练-测试一致,可视化完成后,训练时无须再将代码改回来。

python setup.py install使用方法一
from visualizer import get_local
@get_local('attention_map') # 我要拿attention_map这个变量,所以把他传参给get_local
def your_attention_function(*args, **kwargs):
...
attention_map = ...
...
return ...在可视化代码里,我们这么写:
from visualizer import get_local
get_local.activate() # 激活装饰器
from ... import model # 被装饰的模型一定要在装饰器激活之后导入!!
# load model and data
...
out = model(data)
cache = get_local.cache # -> {'your_attention_function': [attention_map]}使用 Pytorch 时我们往往会将模块定义成一个类,此时也是一样只要装饰类内计算出 attention_map 的函数即可:
from visualizer import get_local
class Attention(nn.Module):
def __init__(self):
...
@get_local('attn_map')
def forward(self, x):
...
attn_map = ...
...
return ...其他细节请参考:

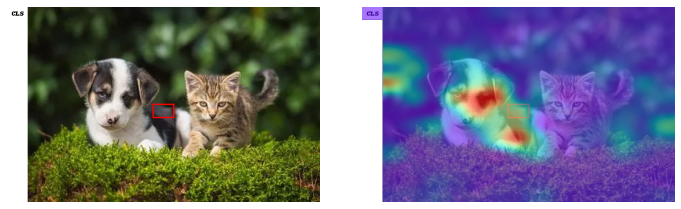
可视化结果
因为普通 Vit 所有 Attention map 都是在 Attention.forward 中计算出来的,所以只要简单地装饰一下这个函数,我们就可以同时取出 vit 中 12 层 Transformer 的所有 Attention Map!
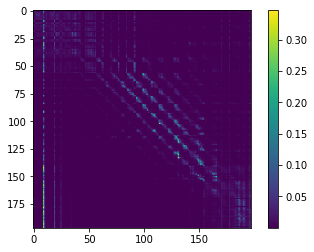
一个 Head 的结果:
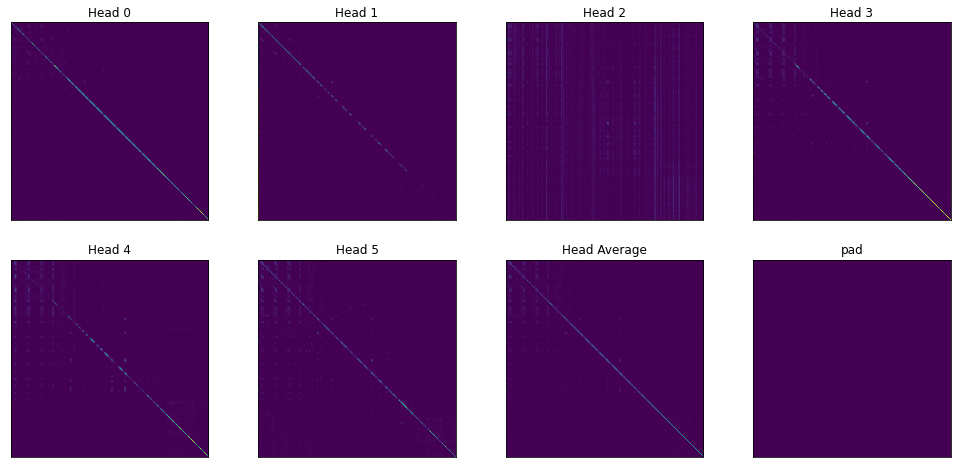
一层所有 Heads 的结果:

在可视化这张图片的过程中,我也发现了一些有趣的现象。
首先,靠前层的 Attention 大多只关注自身,进行真·self attention 来理解自身的信息,比如这是第一层所有 Head 的 Attention Map,其特点就是呈现出明显的对角线模式。
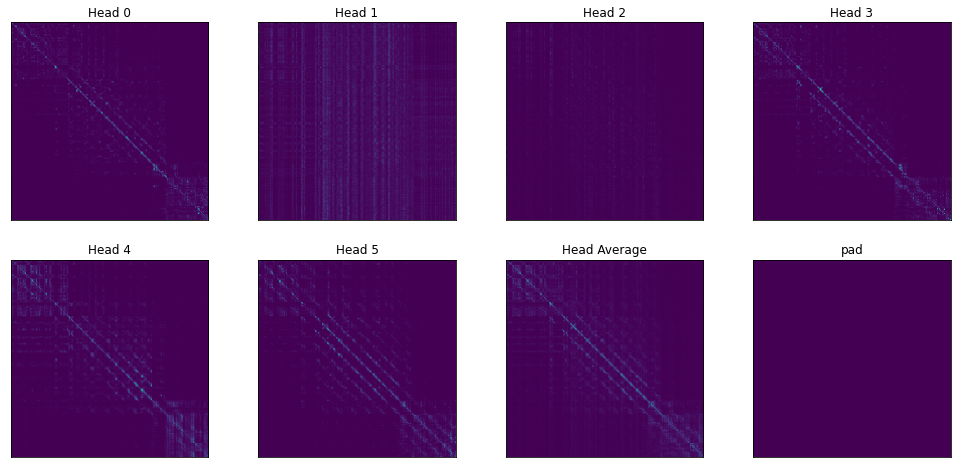

最后,重要信息聚合到某些特定的 token 上,Attention 出现与 query 无关的情况,在 Attention Map 上呈现出竖线的模式,如下第 11 层的 Attention Map:

注意
在使用 visualizer 的过程中,有以下几点需要注意:
1. 想要可视化的变量在函数内部不能被后续的同名变量覆盖了,因为 get_local 取的是对应名称变量在函数中的最终值;
2. 进行可视化时,get_local.activate() 一定要在导入模型前完成,因为 python 装饰器是在导入时执行的;
3. 训练时你不需要删除装饰的代码,因为在 get_local.activate() 没有执行的情况下,attention 函数不会被装饰,故没有任何性能损失(同上一点,因为 python 装饰器是在导入时执行的)。
其他
当然,其实 get_local 本质就是获取一个函数中某个局部变量的最终值,所以它应该还有其他更有趣的用途。

小结

点个在看 paper不断!