
使用JAX实现完整的Vision Transformer

本文将展示如何使用JAX/Flax实现Vision Transformer (ViT),以及如何使用JAX/Flax训练ViT。
Vision Transformer
在实现Vision Transformer时,首先要记住这张图。
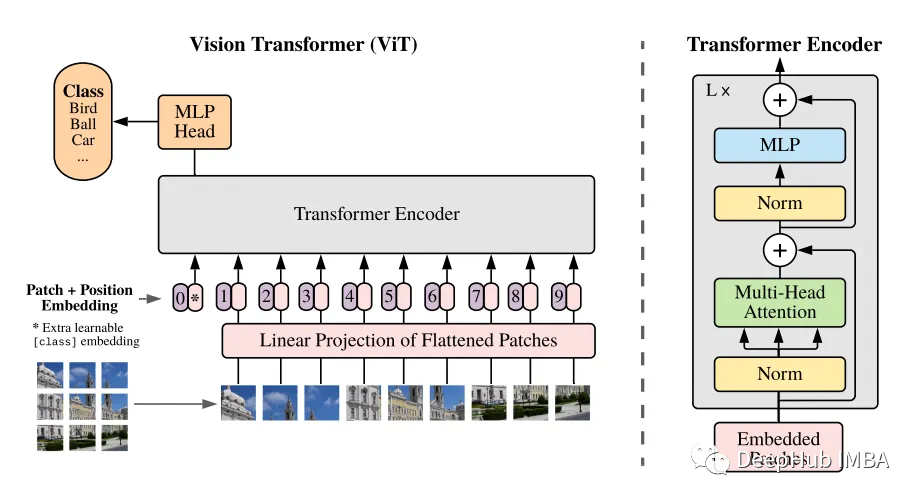
以下是论文描述的ViT执行过程。
从输入图像中提取补丁图像,并将其转换为平面向量。 投影到 Transformer Encoder 来处理的维度。 预先添加一个可学习的嵌入([class]标记),并添加一个位置嵌入。 由 Transformer Encoder 进行编码处理。 使用[class]令牌作为输出,输入到MLP进行分类。
细节实现
下面,我们将使用JAX/Flax创建每个模块。
1. 图像到展平的图像补丁
下面的代码从输入图像中提取图像补丁。这个过程通过卷积来实现,内核大小为patch_size * patch_size, stride为patch_size * patch_size,以避免重复。
class Patches(nn.Module):patch_size: intembed_dim: intdef setup(self):self.conv = nn.Conv(features=self.embed_dim,kernel_size=(self.patch_size, self.patch_size),strides=(self.patch_size, self.patch_size),padding='VALID')def __call__(self, images):patches = self.conv(images)b, h, w, c = patches.shapepatches = jnp.reshape(patches, (b, h*w, c))return patches
2和3. 对展平补丁块的线性投影/添加[CLS]标记/位置嵌入
Transformer Encoder 对所有层使用相同的尺寸大小hidden_dim。上面创建的补丁块向量被投影到hidden_dim维度向量上。与BERT一样,有一个CLS令牌被添加到序列的开头,还增加了一个可学习的位置嵌入来保存位置信息。
class PatchEncoder(nn.Module):hidden_dim: int@nn.compactdef __call__(self, x):assert x.ndim == 3n, seq_len, _ = x.shape# Hidden dimx = nn.Dense(self.hidden_dim)(x)# Add cls tokencls = self.param('cls_token', nn.initializers.zeros, (1, 1, self.hidden_dim))cls = jnp.tile(cls, (n, 1, 1))x = jnp.concatenate([cls, x], axis=1)# Add position embeddingpos_embed = self.param('position_embedding',nn.initializers.normal(stddev=0.02), # From BERT(1, seq_len + 1, self.hidden_dim))return x + pos_embed
4. Transformer encoder
如上图所示,编码器由多头自注意(MSA)和MLP交替层组成。Norm层 (LN)在MSA和MLP块之前,残差连接在块之后。
class TransformerEncoder(nn.Module):embed_dim: inthidden_dim: intn_heads: intdrop_p: floatmlp_dim: intdef setup(self):self.mha = MultiHeadSelfAttention(self.hidden_dim, self.n_heads, self.drop_p)self.mlp = MLP(self.mlp_dim, self.drop_p)self.layer_norm = nn.LayerNorm(epsilon=1e-6)def __call__(self, inputs, train=True):# Attention Blockx = self.layer_norm(inputs)x = self.mha(x, train)x = inputs + x# MLP blocky = self.layer_norm(x)y = self.mlp(y, train)return x + y
MLP是一个两层网络。激活函数是GELU。本文将Dropout应用于Dense层之后。
class MLP(nn.Module):mlp_dim: intdrop_p: floatout_dim: Optional[int] = None@nn.compactdef __call__(self, inputs, train=True):actual_out_dim = inputs.shape[-1] if self.out_dim is None else self.out_dimx = nn.Dense(features=self.mlp_dim)(inputs)x = nn.gelu(x)x = nn.Dropout(rate=self.drop_p, deterministic=not train)(x)x = nn.Dense(features=actual_out_dim)(x)x = nn.Dropout(rate=self.drop_p, deterministic=not train)(x)return x
多头自注意(MSA)
qkv的形式应为[B, N, T, D],如Single Head中计算权重和注意力后,应输出回原维度[B, T, C=N*D]。
class MultiHeadSelfAttention(nn.Module):hidden_dim: intn_heads: intdrop_p: floatdef setup(self):self.q_net = nn.Dense(self.hidden_dim)self.k_net = nn.Dense(self.hidden_dim)self.v_net = nn.Dense(self.hidden_dim)self.proj_net = nn.Dense(self.hidden_dim)self.att_drop = nn.Dropout(self.drop_p)self.proj_drop = nn.Dropout(self.drop_p)def __call__(self, x, train=True):B, T, C = x.shape # batch_size, seq_length, hidden_dimN, D = self.n_heads, C // self.n_heads # num_heads, head_dimq = self.q_net(x).reshape(B, T, N, D).transpose(0, 2, 1, 3) # (B, N, T, D)k = self.k_net(x).reshape(B, T, N, D).transpose(0, 2, 1, 3)v = self.v_net(x).reshape(B, T, N, D).transpose(0, 2, 1, 3)# weights (B, N, T, T)weights = jnp.matmul(q, jnp.swapaxes(k, -2, -1)) / math.sqrt(D)normalized_weights = nn.softmax(weights, axis=-1)# attention (B, N, T, D)attention = jnp.matmul(normalized_weights, v)attention = self.att_drop(attention, deterministic=not train)# gather headsattention = attention.transpose(0, 2, 1, 3).reshape(B, T, N*D)# projectout = self.proj_drop(self.proj_net(attention), deterministic=not train)return out
5. 使用CLS嵌入进行分类
最后MLP头(分类头)。
class ViT(nn.Module):patch_size: intembed_dim: inthidden_dim: intn_heads: intdrop_p: floatnum_layers: intmlp_dim: intnum_classes: intdef setup(self):self.patch_extracter = Patches(self.patch_size, self.embed_dim)self.patch_encoder = PatchEncoder(self.hidden_dim)self.dropout = nn.Dropout(self.drop_p)self.transformer_encoder = TransformerEncoder(self.embed_dim, self.hidden_dim, self.n_heads, self.drop_p, self.mlp_dim)self.cls_head = nn.Dense(features=self.num_classes)def __call__(self, x, train=True):x = self.patch_extracter(x)x = self.patch_encoder(x)x = self.dropout(x, deterministic=not train)for i in range(self.num_layers):x = self.transformer_encoder(x, train)# MLP headx = x[:, 0] # [CLS] tokenx = self.cls_head(x)return x
使用JAX/Flax训练
现在已经创建了模型,下面就是使用JAX/Flax来训练。
数据集
这里我们直接使用 torchvision的CIFAR10。
首先是一些工具函数:
def image_to_numpy(img):img = np.array(img, dtype=np.float32)img = (img / 255. - DATA_MEANS) / DATA_STDreturn imgdef numpy_collate(batch):if isinstance(batch[0], np.ndarray):return np.stack(batch)elif isinstance(batch[0], (tuple, list)):transposed = zip(*batch)return [numpy_collate(samples) for samples in transposed]else:return np.array(batch)
然后是训练和测试的dataloader:
test_transform = image_to_numpytrain_transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomResizedCrop((IMAGE_SIZE, IMAGE_SIZE), scale=CROP_SCALES, ratio=CROP_RATIO),image_to_numpy])# Validation set should not use the augmentation.train_dataset = CIFAR10('data', train=True, transform=train_transform, download=True)val_dataset = CIFAR10('data', train=True, transform=test_transform, download=True)train_set, _ = torch.utils.data.random_split(train_dataset, [45000, 5000], generator=torch.Generator().manual_seed(SEED))_, val_set = torch.utils.data.random_split(val_dataset, [45000, 5000], generator=torch.Generator().manual_seed(SEED))test_set = CIFAR10('data', train=False, transform=test_transform, download=True)train_loader = torch.utils.data.DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True, drop_last=True, num_workers=2, persistent_workers=True, collate_fn=numpy_collate,)val_loader = torch.utils.data.DataLoader(val_set, batch_size=BATCH_SIZE, shuffle=False, drop_last=False, num_workers=2, persistent_workers=True, collate_fn=numpy_collate,)test_loader = torch.utils.data.DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=False, drop_last=False, num_workers=2, persistent_workers=True, collate_fn=numpy_collate,)
初始化模型
初始化ViT模型:
def initialize_model(seed=42,patch_size=16, embed_dim=192, hidden_dim=192,n_heads=3, drop_p=0.1, num_layers=12, mlp_dim=768, num_classes=10:main_rng = jax.random.PRNGKey(seed)x = jnp.ones(shape=(5, 32, 32, 3))# ViTmodel = ViT(patch_size=patch_size,embed_dim=embed_dim,hidden_dim=hidden_dim,n_heads=n_heads,drop_p=drop_p,num_layers=num_layers,mlp_dim=mlp_dim,num_classes=num_classes)init_rng, drop_rng = random.split(main_rng, 3)params = model.init({'params': init_rng, 'dropout': drop_rng}, x, train=True)['params']return model, params, main_rngvit_params, vit_rng = initialize_model()
创建TrainState
在Flax中常见的模式是创建管理训练的状态的类,包括轮次、优化器状态和模型参数等等。还可以通过在apply_fn中指定apply_fn来减少学习循环中的函数参数列表,apply_fn对应于模型的前向传播。
def create_train_state(params, learning_rate:optimizer = optax.adam(learning_rate)return train_state.TrainState.create(apply_fn=model.apply,tx=optimizer,params=params)state = create_train_state(vit_model, vit_params, 3e-4)
循环训练
def train_model(train_loader, val_loader, state, rng, num_epochs=100):best_eval = 0.0for epoch_idx in tqdm(range(1, num_epochs + 1)):state, rng = train_epoch(train_loader, epoch_idx, state, rng)if epoch_idx % 1 == 0:eval_acc = eval_model(val_loader, state, rng)logger.add_scalar('val/acc', eval_acc, global_step=epoch_idx)if eval_acc >= best_eval:best_eval = eval_accsave_model(state, step=epoch_idx)logger.flush()# Evaluate after trainingtest_acc = eval_model(test_loader, state, rng)print(f'test_acc: {test_acc}')def train_epoch(train_loader, epoch_idx, state, rng):metrics = defaultdict(list)for batch in tqdm(train_loader, desc='Training', leave=False):state, rng, loss, acc = train_step(state, rng, batch)metrics['loss'].append(loss)metrics['acc'].append(acc)for key in metrics.keys():arg_val = np.stack(jax.device_get(metrics[key])).mean()logger.add_scalar('train/' + key, arg_val, global_step=epoch_idx)print(f'[epoch {epoch_idx}] {key}: {arg_val}')return state, rng
验证
def eval_model(data_loader, state, rng):# Test model on all images of a data loader and return avg losscount = 0, 0for batch in data_loader:acc = eval_step(state, rng, batch)correct_class += acc * batch[0].shape[0]count += batch[0].shape[0]eval_acc = (correct_class / count).item()return eval_acc
训练步骤
在train_step中定义损失函数,计算模型参数的梯度,并根据梯度更新参数;在value_and_gradients方法中,计算状态的梯度。在apply_gradients中,更新TrainState。交叉熵损失是通过apply_fn(与model.apply相同)计算logits来计算的,apply_fn是在创建TrainState时指定的。
def train_step(state, rng, batch):loss_fn = lambda params: calculate_loss(params, state, rng, batch, train=True)# Get loss, gradients for loss, and other outputs of loss function(loss, (acc, rng)), grads = jax.value_and_grad(loss_fn, has_aux=True)(state.params)# Update parameters and batch statisticsstate = state.apply_gradients(grads=grads)return state, rng, loss, acc
计算损失
def calculate_loss(params, state, rng, batch, train):imgs, labels = batchrng, drop_rng = random.split(rng)logits = state.apply_fn({'params': params}, imgs, train=train, rngs={'dropout': drop_rng})loss = optax.softmax_cross_entropy_with_integer_labels(logits=logits, labels=labels).mean()acc = (logits.argmax(axis=-1) == labels).mean()return loss, (acc, rng)
结果
训练结果如下所示。在Colab pro的标准GPU上,训练时间约为1.5小时。
test_acc: 0.7704000473022461
https://github.com/satojkovic/vit-jax-flax
作者:satojkovic
编辑:黄继彦