本文约1700字,建议阅读9分钟
本文为你介绍2020年发布的一种称为 U²-Net 或 U-squared Net 的 U-net 变体。
分割给定图像中的不同对象一直是计算机视觉领域的一项非常重要的任务。多年来,我们已经看到像 Deeplab 这样的自编码器模型被用于语义分割。在所有分割模型中,仍然有一个名字居于首位那就是U-Net。U-Net 于 2018 年发布,从那时起它获得了巨大的普及,并以某种形式用于与分割相关的几个不同任务。在这篇文章中,我们将介绍2020年发布的一种称为 U²-Net 或 U-squared Net 的 U-net 变体。U²-Net基本上是由U-Net组成的U-Net。
U²-Net 是为显著性对象检测或 SOD 而设计的。对于那些不知道的人来说,显著性对象检测基本上是检测给定图像中最重要或主要的对象。U2 -Net 的架构是一个两级嵌套的 U 结构。该设计具有以下优点:
- 提出残差 U 块 (RSU) 中混合了不同大小的感受野,它能够从不同的尺度捕获更多的上下文信息。
- 这些 RSU 块中使用了池化操作,它增加了整个架构的深度,而不会显著增加计算成本。
Residual U-Block:局部和全局上下文信息对于对象检测和其他分割任务都非常重要。为了降低内存和计算量,VGG16、ResNet 或 DenseNet 等网络使用较小尺寸的卷积核(通常为 1x1 或 3x3)。在下图中显示了不同的网络的架构。浅层的输出特征图只包含局部特征,因为 1×1 或 3×3 卷积核的感受野太小,无法捕获全局信息。为了在浅层的高分辨率特征图中获得更多的全局信息,最直接的想法是扩大感受野,但这是以额外计算为代价的。上图(d)显示了一个类似 Inception 的块,它试图通过使用扩张(空洞)卷积扩大感受野来提取局部和非局部特征。但是以原始分辨率对输入特征图(尤其是早期阶段)进行多次扩张卷积需要过多的计算和内存资源。RSU-L(C_in,M,C_out)受 U-Net、ReSidual Ublock 和 RSU 的启发可以捕获阶段内多尺度特征(上图最右侧架构)。这里L是编码器的层数,C_in、C_out表示输入和输出通道,M表示RSU内部层的通道数。
- 输入卷积层,将输入特征图 x (H×W ×C_in) 转换为通道为 C_out 的中间图 F1(x)。这是一个用于局部特征提取的普通卷积层。
- 一种高度为 L 的类 U-Net 对称编码器-解码器结构,以中间特征图 F1(x) 作为输入,学习提取和编码多尺度上下文信息 U(F1(x))。较大的 L 会导致更深的残差 U 块 (RSU)、更多的池化操作、更大范围的感受野以及更丰富的局部和全局特征。配置 L 可以从具有任意空间分辨率的输入特征图中提取多尺度特征。这个过程减轻了由大尺度直接上采样引起的细节损失。
- 通过求和融合局部特征和多尺度特征的残差连接:F1(x) +U(F1(x))。
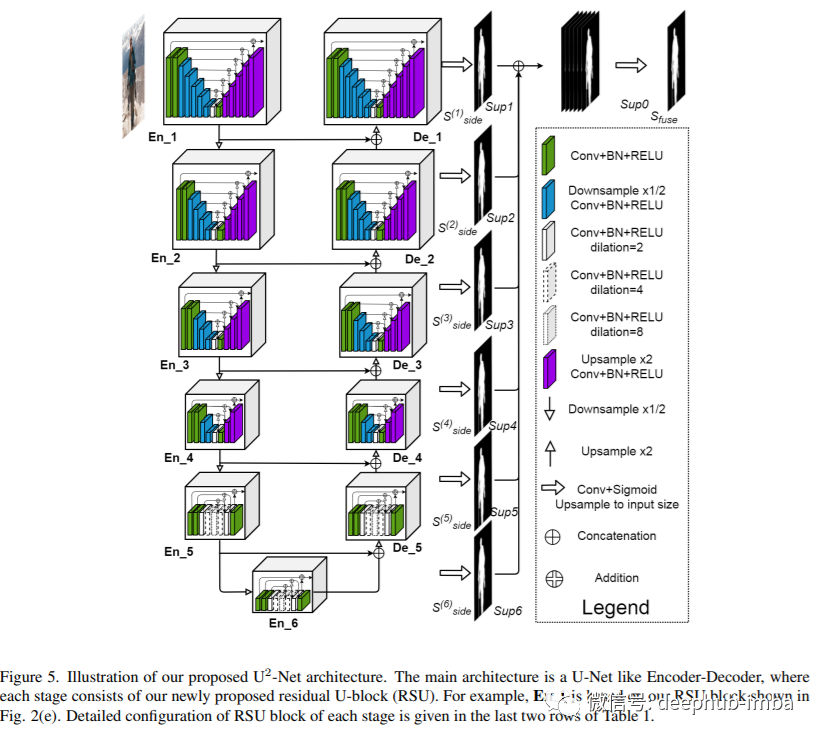
U²-Net 架构在编码器阶段,En_1、En_2、En_3 和 En_4,分别使用残差 U 块 RSU-7、RSU-6、RSU-5 和 RSU-4。其中“7”、“6”、“5”和“4”表示 RSU 块的高度 (L)。L 通常根据输入特征图的空间分辨率进行配置。对于高度和宽度较大的特征图,较大的 L 值用于捕获更多的大规模信息。En_5 和 En_6 中特征图的分辨率相对较低,这些特征图的进一步下采样会导致有用上下文的丢失。因此在 En_5 和 En_6 阶段,都使用了 RSU-4F,其中“F”表示 RSU 是扩张版本并且池化和上采样操作被扩张卷积取代。RSU-4F 的所有中间特征图都具有与其输入特征图相同的分辨率。
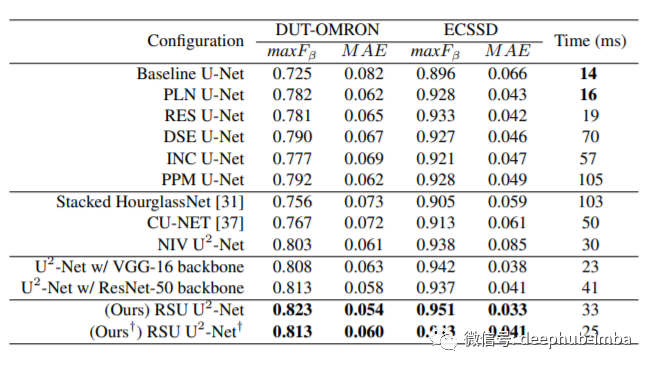
解码器的结构与其对称编码器的 En_6 结构相似。De_5 还使用了与编码器阶段 En_5 和 En_6 中使用的类似的扩张版残差 U 块 RSU-4F。每个解码器阶段将来自其前一阶段的上采样特征图和来自其对称编码器阶段的上采样特征图的连接作为输入。最后是用于生成显著概率图的显著图融合模块。U²-Net首先通过一个由3 × 3的卷积层和一个sigmoid函数组成的阶段En_6、De_5、De_4、De_3、De_2和De_1生成的S(6)、S(5)、S(4)、S(3)、S(2)、S(1)输出显著性概率映射。然后,它对这些输出显著性logits (sigmoid函数之前的卷积输出)进行熵采样并将其映射到输入图像大小,通过concat操作进行融合,最后是1×1卷积层和sigmoid函数,这样就生成了最终的显著性概率图S_fuse。上图可以看到对比其他的模型U2-Net都有不小的提升。以上就是这篇文章的所有内容,我们论文回顾的目标是用一种简单易懂的格式呈现原始论文,同时也给你一些关键的收获。https://arxiv.org/pdf/2005.09007.pdf