
ICCV19 (Oral) | 基于贝叶斯损失函数的人群计数
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文作者:洪晓鹏
https://zhuanlan.zhihu.com/p/127956794
本文已由原作者授权,不得擅自二次转载

Zhiheng Ma, Xing Wei, Xiaopeng Hong, and Gong, Yihong. Bayesian Loss for Crowd Count Estimation with Point Supervision. In Proceedings of the international conference on computer vision, (ICCV-19), pp. 6142-6151, 2019.
本文发表于ICCV 2019,由西安交通大学龚怡宏、洪晓鹏团队提出。这篇简短的介绍由本人讲座的稿件整理而成。我们希望通过它能够让更多的同行了解和关注我们的方法,并提出宝贵意见。
基于机器视觉的目标计数在规模估算、密集目标的快速定位、人流估计、场景监控等方面有着广泛的应用前景。不过由于密集目标之间往往存在大量的重叠和遮挡;而且透视成像效果导致目标之间在大小、形状方面会发生较大变化,时至今日目标计数依然是一项非常具有挑战性的任务。
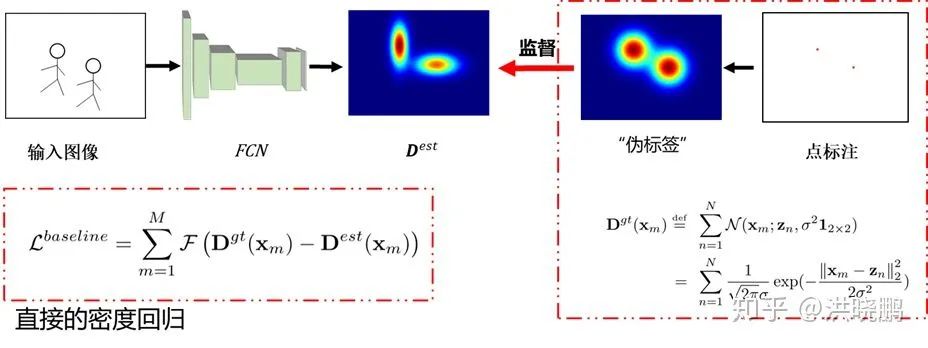
现有的基于目标检测的目标计数方法无法有效地检测稠密区域中的每一个目标,因此在精确计数方面存在着很大的困难。尽管最近使用卷积神经网络(CNN)的目标计数方法取得了显着进展,但正如图1所示,传统方法在训练时通常需要从提供的输入图像“点”标注“生成”真值(Ground Truth)密度图,并以其作为监督信号,与模型预测得到的密度图一起用来计算相应的损失(Loss),进行直接的密度回归估计。从点标注生成真值密度图的过程需要对点标注作简单的高斯假设,进行模糊处理从而生成可用于训练监督的像素级真值概率密度。然而,由于目标之间高度的拥挤与重叠,通过上述方法生成的概率密度仅仅是对实际概率密度图的一个粗略逼近,其准确度是很难保证的。此外,由于目标大小信息往往无法获得,因此在对每个标注点高斯假设时无法准确获得每个目标对应的高斯分布标准差  ,因此只能把不同目标的标准差都“粗暴地”设置为一个固定值,这样又进一步影响了所生成概率密度图的准确程度。因此我们这里将这种通过模糊方式从点标注得到的概率密度图称为“伪”真值标签,这里的形容词“伪”表示其与真正的概率密度图差别较大,难以准确体现实际概率密度图的特点。
,因此只能把不同目标的标准差都“粗暴地”设置为一个固定值,这样又进一步影响了所生成概率密度图的准确程度。因此我们这里将这种通过模糊方式从点标注得到的概率密度图称为“伪”真值标签,这里的形容词“伪”表示其与真正的概率密度图差别较大,难以准确体现实际概率密度图的特点。
为解决上述这些问题,我们采用了一个全新的思路。我们不再依赖从点标注生成不完美的伪标签,而是直接采用数据库所提供的点标注作为(弱)监督信号。为了使监督信号格式匹配,我们从估计得到的概率密度图的基础上又多进行了一步“期望”操作,利用“离散”的概率密度期望值与“离散”的点标注设计损失函数并进行期望值意义上的回归估计,如下图所示。我们将所提损失函数称为贝叶斯损失函数(Bayesian Loss)。
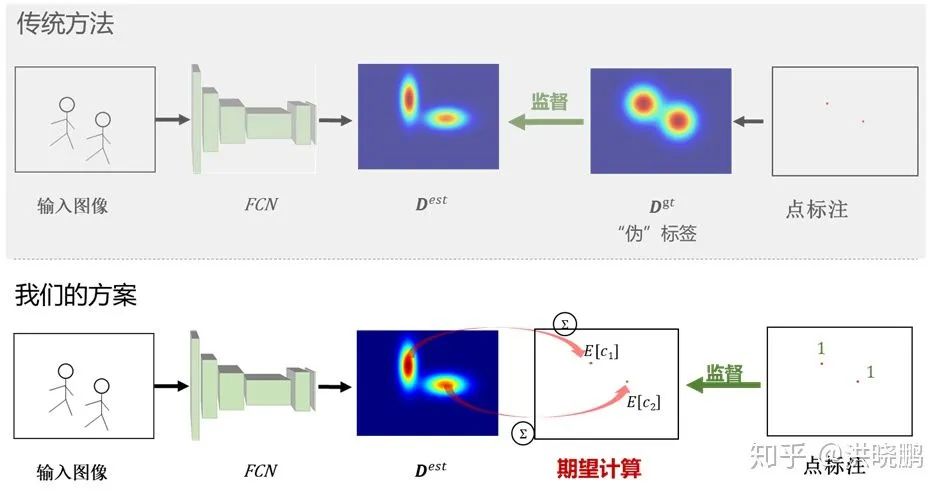
所提方法的训练过程示意图如下所示。
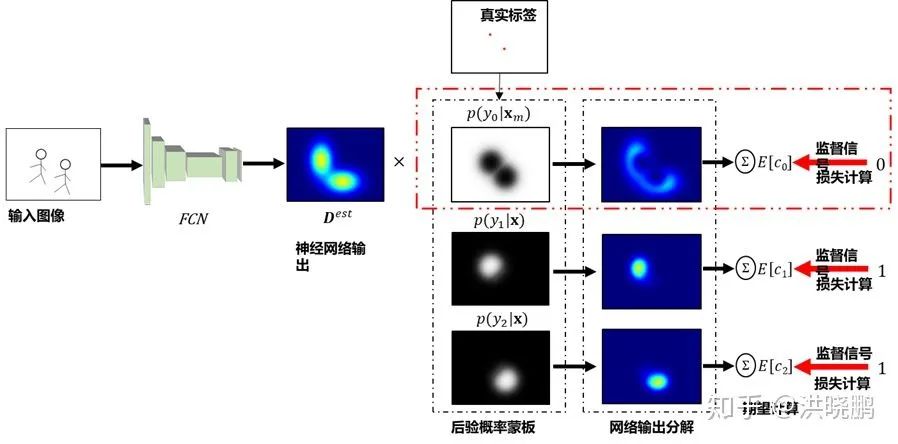
令 为 空间位置 随机变量,
为 空间位置 随机变量,  为 标记有人 的随机变量。为表示每个目标在图像中的位置分布,我们使用二维高斯分布来近似目标的似然概率分布,即“当出现 目标标签为
为 标记有人 的随机变量。为表示每个目标在图像中的位置分布,我们使用二维高斯分布来近似目标的似然概率分布,即“当出现 目标标签为 的目标时,他/她出现在位置
的目标时,他/她出现在位置  ”的条件概率:
”的条件概率:
 (1)
(1)
其中  代表目标中心标记点的空间位置,
代表目标中心标记点的空间位置,  代表高斯分布,目标的似然概率随着远离目标中心标记点而减小。在此基础上,给定目标的似然概率分布,我们估计每个像素出现目标的后验概率:
代表高斯分布,目标的似然概率随着远离目标中心标记点而减小。在此基础上,给定目标的似然概率分布,我们估计每个像素出现目标的后验概率:
 (2)
(2)
通过上式的似然概率,我们可以使用贝叶斯公式构建出后验概率场,该概率场定义了空间中每一个位置属于某一个目标的概率(即图3中的后验概率蒙版)。以此为基础,我们可以计算每一个目标的期望计数。比如出现第  人的期望
人的期望  可通过下式计算:
可通过下式计算:
 (3)
(3)
其中  是神经网络预测的目标概率密度,也即在位置 处出现人的概率密度。公式(3)通过将后验分配概率场和神经网络预测的密度相乘相加,从而得到每一个目标的期望计数。由于 任意给定的目标的理想计数期望应该是1,因此对于该目标的损失函数,即所提出的贝叶斯损失函数 Bayesian Loss 可写为:
是神经网络预测的目标概率密度,也即在位置 处出现人的概率密度。公式(3)通过将后验分配概率场和神经网络预测的密度相乘相加,从而得到每一个目标的期望计数。由于 任意给定的目标的理想计数期望应该是1,因此对于该目标的损失函数,即所提出的贝叶斯损失函数 Bayesian Loss 可写为:
 (4)
(4)
在实验中我们注意到,上述方案中的目标后验概率可以较为准确推断出人(Head Point)与人(Head Point)之间的边界,但是对于远离任何人头标注(Head Point)的位置,却不太理想。这些位置很可能是背景点,然而通过计算却有一定概率会得到一个较高的后验概率。为了解决这个问题,并且保证在背景区域的后验概率场计算准确性,我们将背景类也当成一个特殊的目标(类)  ,并且引入一个动态的背景哑元(Dummy Background Point)。利用背景哑元,我们可以“吸收”远离人群的背景区域像素的“贡献”,从而更为准确的计算背景区域的似然及最终的后验概率。
,并且引入一个动态的背景哑元(Dummy Background Point)。利用背景哑元,我们可以“吸收”远离人群的背景区域像素的“贡献”,从而更为准确的计算背景区域的似然及最终的后验概率。
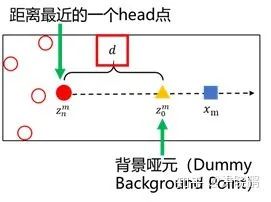
背景哑元的似然概率可按下式计算:  (5)
(5)
上述背景哑元的机制带来的另一个好处是,我们几乎不需要作出显著的改动,就可以将其统一到上述贝叶斯损失框架中。具体地,依公式(2)和(3),我们可以将目标类别增广为从类别下标0开始,相应即可得到类别的后验概率和期望:
 (6)
(6)
以此为基础,我们可以很容易得到增强的贝叶斯损失函数 Bayesian Loss+:
 (7)
(7)
最终我们利用 公式7 进行模型优化。
在预测阶段,给定输入预测图片,我们希望计算目标数目  。我们可以通过卷积神经网络模型得到人群密度估计图 。然而不仅目标数目 待求,而且预测图片的标记点 也是不可得到的,我们无法按照下列方式直接利用公式1-2 计算其后验概率,从而求和每个目标的期望得到总数:
。我们可以通过卷积神经网络模型得到人群密度估计图 。然而不仅目标数目 待求,而且预测图片的标记点 也是不可得到的,我们无法按照下列方式直接利用公式1-2 计算其后验概率,从而求和每个目标的期望得到总数:

不过,考虑上式特点,我们可以交换式子右端两个求和运算的顺序。由于公式2中的后验  对求和恒为1,我们得到
对求和恒为1,我们得到
 (8)
(8)
上式我们得到了一个令人鼓舞的结果。它表明,我们只需要对输入图片的人群密度估计图 求和,即可得到该图片的预测目标计数。值得一提的是,尽管我们对训练模块从监督信号到回归机制都作了较大的改动,然而在预测部分,却没有带来任何明显的改变,只需要按照公式8进行简单求和,就能得到我们想要的计数估计值。这点保证了我们方法具有好的可推广性。
实验结果
通过与SOTA方法在四个主流人群计数数据库上的比较,以MAE和MSE为指标的对比结果如下表1所示。
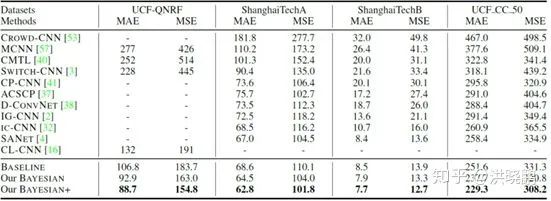
从上述对比实验中可以看出,所提方法在MAE和MSE指标上均取得明显提升。比如,在目前最大的人群计数数据集UCF-QNRF上,所提方法将MAE指标从主流算法的132降低到88.7(降低MAE值44),MSE指标从191降低到155.8(降低MSE值35)。

图5列举了在一组示例图片上基准算法,贝叶斯损失,增强贝叶斯损失函数产生的概率密度图对比。在该例子中,真实计数为1616,传统算法输出计数为1946,误差为330个计数,而所提的贝叶斯损失函数输出计数1686,误差为70个计数;增强版的贝叶斯损失函数输出计数1602,误差仅为14个计数。
文中我们还对似然高斯的标准差 以及背景哑元间隔值  进行了参数敏感度测试,并且评估了不同骨干网络等因素对性能的影响。详情请见文章4.5节。
进行了参数敏感度测试,并且评估了不同骨干网络等因素对性能的影响。详情请见文章4.5节。
结论
在本文中,我们提出了一种新的损失函数,用于点监督下的人群计数估计。传统方法通常使用高斯核将像素的“点注释”转换为“伪”真值密度图,并以此“伪”真值密度图为基础进行概率密度回归。与之不同的是,我们使用了一种更可靠的方式,对每个注释点的计数期望值(而非注释点在密度图上的邻域内所有像素的计数值)进行监督。由于训练过程的监督是以个别离散像素点形式进行,因此仅仅需要“点”标注,而无需全图标注。从而提高了性能。充实的实验证明了我们提出的方法在准确性,鲁棒性和泛化方面的优势。此外,我们的方法更具有一般性,可以很容易地被用来合并其他知识,例如,特定的前景或背景先验,尺度和时间似然以及其他事实,从而得到进一步改进。
本文是ICCV 2019口头展示(Oral)文章。在口头展示和墙报展示环节均受到了不少与会者的关注。其中国际计算机视觉著名学者,美国中佛罗里达大学(UCF)计算机视觉研讨中心主任Mubarak Shah教授(IEEE,AAAS,SPIE,IAPR会士)在提到我们的方法时当面评价到:
“A new crowd counting solution, which is simple and elegant”
对我们的方法给与了充分的肯定。
Zhiheng Ma, Xing Wei, Xiaopeng Hong, and Gong, Yihong. Bayesian Loss for Crowd Count Estimation with Point Supervision. In Proceedings of the international conference on computer vision, (ICCV-19), pp. 6142-6151, 2019.
@inproceedings{ma2019bayesian, title={Bayesian loss for crowd count estimation with point supervision}, author={Ma, Zhiheng and Wei, Xing and Hong, Xiaopeng and Gong, Yihong}, booktitle={Proceedings of the IEEE International Conference on Computer Vision}, pages={6142--6151}, year={2019} }
http://openaccess.thecvf.com/content_ICCV_2019/papers/Ma_Bayesian_Loss_for_Crowd_Count_Estimation_With_Point_Supervision_ICCV_2019_paper.pdf
https://github.com/ZhihengCV/Bayesian-Crowd-Counting
主要参考文献
[1] Haroon Idrees, Muhmmad Tayyab, Kishan Athrey, Dong Zhang, Somaya Al-Maadeed, Nasir Rajpoot, and Mubarak Shah. Composition loss for counting, density map estimation and localization in dense crowds. In ECCV, 2018.
[2] Xinkun Cao, ZhipengWang, Yanyun Zhao, and Fei Su. Scale aggregation network for accurate and efficient crowd counting. In ECCV, 2018.
[3] Haroon Idrees, Imran Saleemi, Cody Seibert, and Mubarak Shah. Multi-source multi-scale counting in extremely dense crowd images. In CVPR, 2013.
[4] Yingying Zhang, Desen Zhou, Siqin Chen, Shenghua Gao, and Yi Ma. Single-image crowd counting via multi-column convolutional neural network. In CVPR, 2016.
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~