
4K美女壁纸爬取
4K美女壁纸爬取
一、前言
拍了zhenguo的课程,今天继续学习课程同时,尝试使用BeautifulSoup4这个网页解析的方法爬取图片,看完后心血来潮,想自己也试一下。
爬完后并总结这篇投稿给zhenguo,奖励我50元稿费,很开心。
最先想到的是彼岸图网,这个网站上有很多4k壁纸,打开网页后,我选择了4k美女壁纸作为本次爬虫的目标,爬取到的图片截图如下:


二、过程
1.首先,我们拿到前三页的网页地址。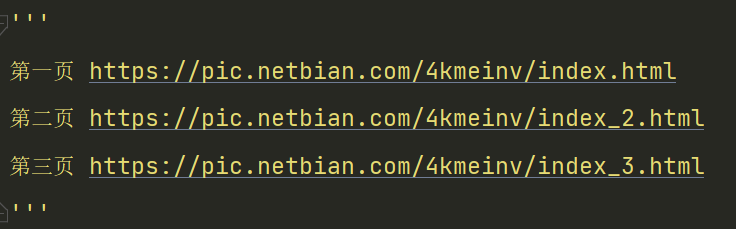
2.通过分析可以看出,当页面变化时,index后面会发生改变,但在第一页时并没有数字显示,所以做出以下操作,通过input获取我们想要爬取的页数,使用if语句对index进行赋值,再传入要爬取的网址中。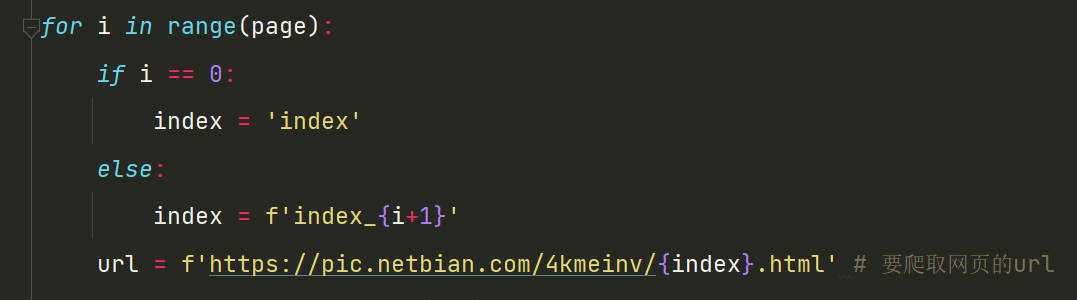
3.接下来就是获取网页源代码了,使用requests.get拿到网页源代码,在打印时发现出现了乱码,根据网页源代码里的提示,规定格式为'gbk',再获取bs对象main_page,指定解析器为'lxml'。
4.在网页源代码中分析得知,需要的内容在标签div class='slist'的标签中,每一个li标签下的a标签包含了要爬取的每张图片的所有信息,所以使用find('div',class_='slist')先定位主标签,再使用find_all('a')定位每一个子标签。接着使用for循环,遍历每一个a标签下的内容,使用get('href')拿到该图片的url,再使用切片的方法,提出图片的数字编号,传入下载地址,就得到了每一个图片的下载地址。注意:这里的下载地址是通过抓包获取,在子页面的网页源代码中是找不到的。
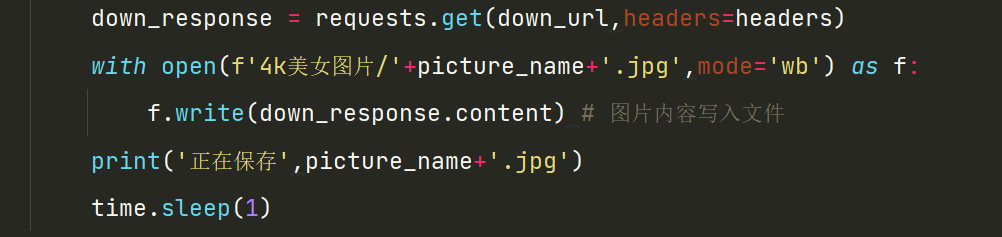
5.有了下载地址,使用requests模块获取响应。这里要注意,该网站要登录后才能进行下载,所以我们要在请求头里传入cookie参数。获取响应后我们就要写入文件保存起来。
三、完整源码
import requests
from bs4 import BeautifulSoup
import time
'''
第一页 https://pic.netbian.com/4kmeinv/index.html
第二页 https://pic.netbian.com/4kmeinv/index_2.html
第三页 https://pic.netbian.com/4kmeinv/index_3.html
'''
headers = {
'cookie': '__yjs_duid=1_609256ccf97c86f63356e4e9f3fa5eb21654735480955; Hm_lvt_c59f2e992a863c2744e1ba985abaea6c=1654735481; zkhanecookieclassrecord=%2C65%2C59%2C66%2C54%2C53%2C55%2C; PHPSESSID=25p1pnl1nog1nn56lic0j2fga6; zkhanmlusername=qq803835154342; zkhanmluserid=826128; zkhanmlgroupid=3; zkhanmlrnd=VQOfLNvHK33WGXiln7nY; zkhanmlauth=264643c01db497a277bbf935b54aa3f3; Hm_lpvt_c59f2e992a863c2744e1ba985abaea6c=1654741154'
}
page = int(input('请输入要爬取的页数:'))
for i in range(page):
if i == 0:
index = 'index'
else:
index = f'index_{i+1}'
theme_url = f'https://pic.netbian.com/4kmeinv/{index}.html' # 要爬取主题的url
response = requests.get(theme_url)
response.encoding = 'gbk'
main_page = BeautifulSoup(response.text,features="lxml")
li_all_a = main_page.find('div',class_='slist').find_all('a') # li标签下所有的a标签
for a in li_all_a:
href = a.get('href')
picture_num = href[8:13]
picture_name = a.find('b').string
down_url = f'https://pic.netbian.com/downpic.php?id={picture_num}&classid=54' # 子页面中的下载地址
down_response = requests.get(down_url,headers=headers)
with open(f'4k美女图片/'+picture_name+'.jpg',mode='wb') as f:
f.write(down_response.content) # 图片内容写入文件
print('正在保存',picture_name+'.jpg')
time.sleep(1)
response.close()
print('程序运行完毕')
四、结尾
以上是爬取4k美女壁纸的简单案例,有兴趣的小伙伴可以对比一下其他主题壁纸,参数稍作修改即可下载其他主题壁纸了。