
百行代码轻松爬取视频

最近老肥在追剧,遇到了不是VIP无法畅享剧集的小困难。然后我在某强大的搜索引擎中发现了一个视频网站,该网站涵盖了各大热门视频,与VIP的更新速度同步,并且无需等待广告。
视频网站?不如我们就写个小爬虫把喜欢的电视剧全部下载到本地,方便随时观看,话不多说,直接开淦!
先来看看单集视频如何爬取,随着视频的播放,我们可以看到一条又一条的ts生成,ts是Transport Stream的缩写,我们可以理解为是视频流。这些ts文件大概是几秒钟的播放时长,因而我们后面需要将该集的所有ts文件合并起来以便观看。
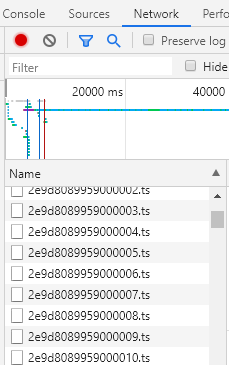
单个ts文件非常容易爬取,使用requests请求对应的url,并将返回的content保存为新的ts文件即可。那么如何获取所有的ts(或者说这些ts的url)呢,答案就在m3u8之中。m3u8文件实质上是一个播放列表,其内部信息记录的是一系列的媒体片段资源。
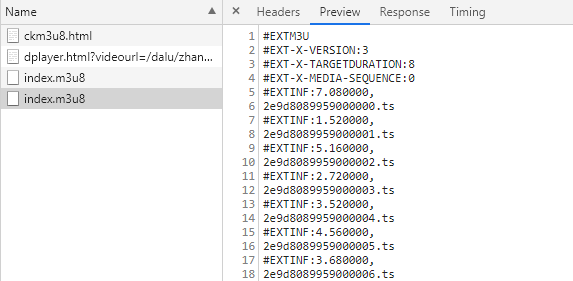
该视频的所有ts列表均在该m3u8之中。也就是说我们首先需要获取该视频的m3u8文件,根据文件中的ts列表,我们可以将该视频所有的ts文件下载到本地。
将该视频所有的ts文件下载之后,我们需要将这些文件合并。如果直接使用命令copy进行合并的话,会有文件数量的限制,本例中就无法将近千个ts文件合并。因此,我使用了ffmpeg来进行合并操作,在代码中通过os.system执行ffmpeg合并命令。
def merge(piece):"""合并ts文件"""os.chdir(vedio_name)with open('temp.txt', 'w') as f:for ts_file in glob('*.ts'):f.write('file ' + ts_file + '\n')shell_str = 'ffmpeg -f concat -i temp.txt -c copy 第{}集.mp4'.format(piece + 1)os.system(shell_str)print("*****************视频'{}第{}集'合并成功*****************".format(vedio_name, piece+1))
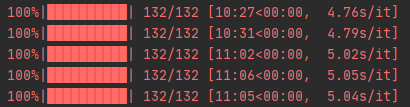
至此,单集视频的下载就已经完成——不对,这样下载速度可慢了,如何提速?这里使用了多进程,将所有的ts文件等分进行视频的多进程下载,为了增加用户体验,这里还加入了进度条的显示,使用tqdm模块,将各个进程的下载情况以进度条的形式显示。
那么如何下载电视剧的所有分集呢,返回到电视剧的主页面,这里有各个分集选项,通过查看网页源代码,我们可以直接使用xpath、正则或者其他方式来提取,加上网页前缀即可生成分集页面的完成url。

通过这些url,我们可以获取各分集对应的m3u8的url,从而获取相应的ts的url,并进而经过处理获得完整的视频。

除此之外,根据我的观察发现这些视频的前缀url格式一致,仅有一处不同,且该处是电视剧名称的拼音,因此用户只需要输入想要下载的电视剧的中文名称,通过pypinyin模块将其转化成拼音,即可完成后面这一系列视频下载操作,完整的代码我已上传,在后台回复「视频」即可获取。
——END——
推荐阅读
Python中模块(Module)和包(Package)到底是什么,有什么区别?