
Python爬取+可视化糗事百科
生活真是太苦了,需要找点快乐的精神食粮支撑社畜生活,听说糗事百科段子挺多,今天就来看一看!
本文主要内容:
selenium爬取段子信息
这次我们利用selenium来实现翻页爬取段子信息!
翻页查看url变化规律:
https://www.qiushibaike.com/text/page/1/
https://www.qiushibaike.com/text/page/2/
https://www.qiushibaike.com/text/page/3/
https://www.qiushibaike.com/text/page/4/
https://www.qiushibaike.com/text/page/5/
https://www.qiushibaike.com/text/page/6/
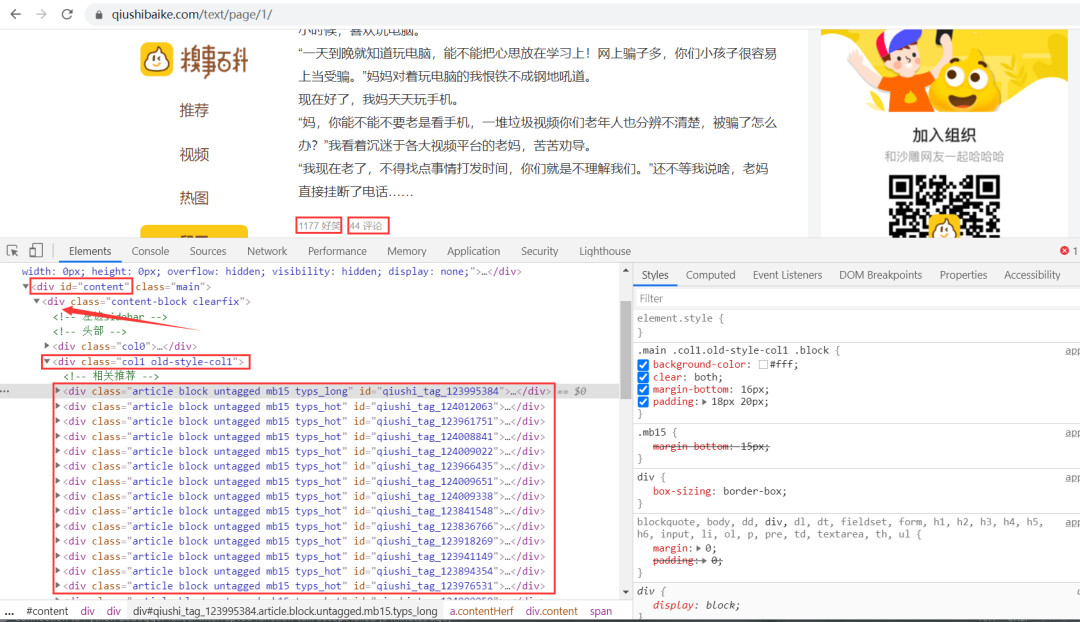
思路:段子信息在 id 为 content 的 div 标签下的 div 下的第二个 div 标签下的 div 标签里,获取到所有 div 标签的内容,然后遍历,从中提取出每一条段子信息。
代码如下:
from selenium import webdriver
from time import sleep
import logging
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(['段子内容', '好笑数', '评论数'])
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
chrome_driver = r'D:\python\pycharm2020\chromedriver.exe'
options = webdriver.ChromeOptions()
# 可以设置无头模式 不弹出浏览器
# options.add_argument("--headless")
# 关闭左上方 Chrome 正受到自动测试软件的控制的提示
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option("excludeSwitches", ['enable-automation'])
browser = webdriver.Chrome(options=options, executable_path=chrome_driver)
# 可以设置绕过Webdriver的检测
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
def get_data(page): # 爬取数据函数
url = f'https://www.qiushibaike.com/text/page/{page}/'
browser.get(url) # 访问目标url
browser.maximize_window() # 最大化窗口
sleep(1) # 短暂休眠
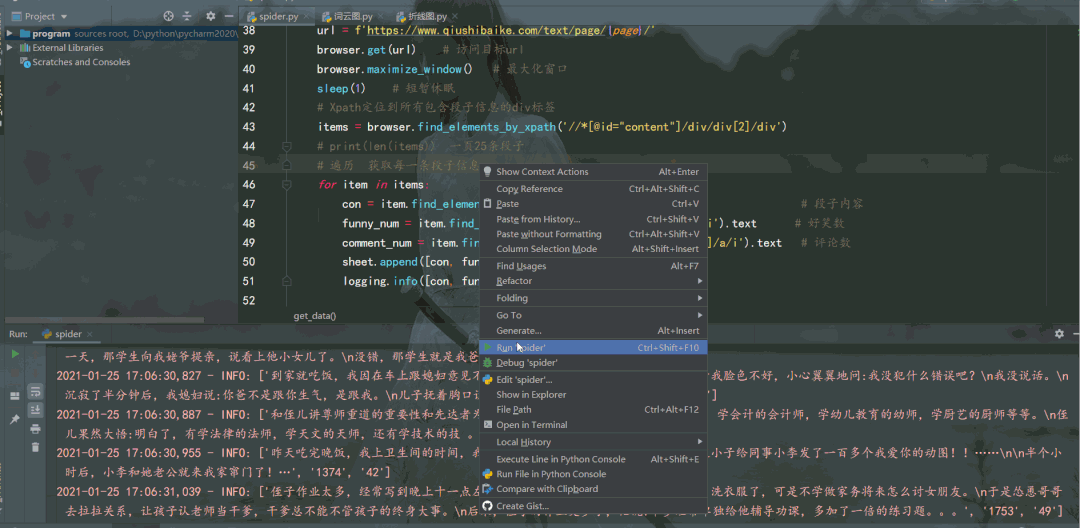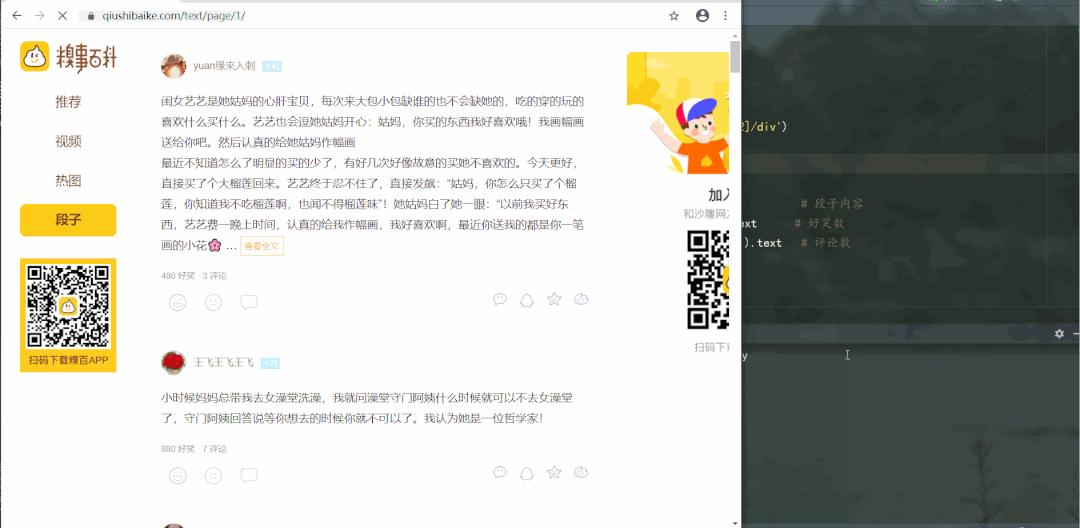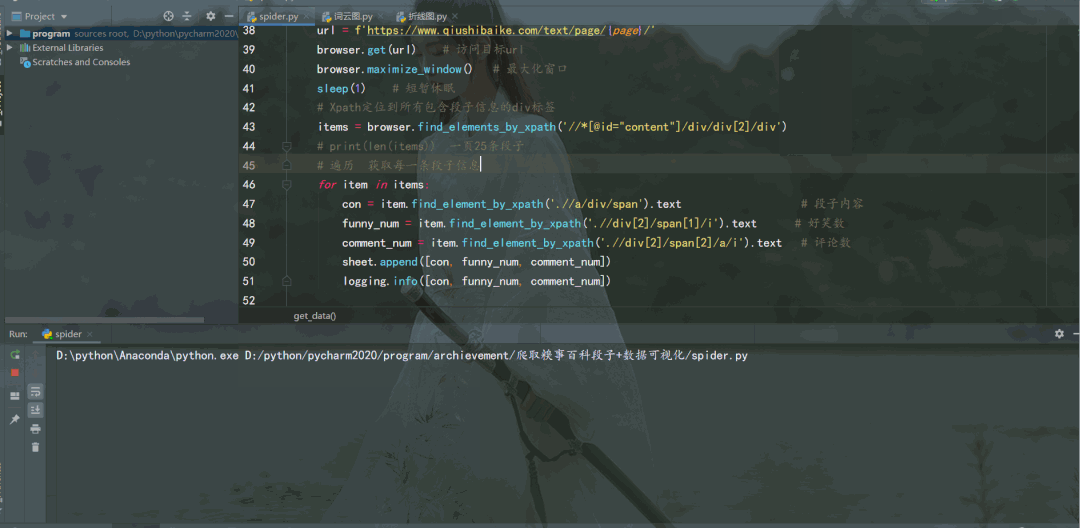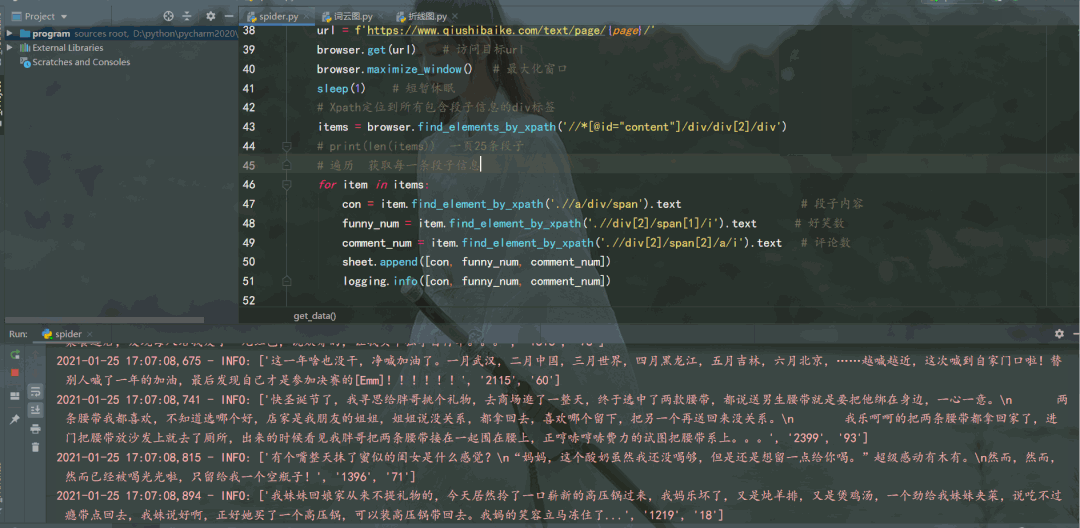
# Xpath定位到所有包含段子信息的div标签
items = browser.find_elements_by_xpath('//*[@id="content"]/div/div[2]/div')
# print(len(items)) 一页25条段子
# 遍历 获取每一条段子信息
for item in items:
con = item.find_element_by_xpath('.//a/div/span').text # 段子内容
funny_num = item.find_element_by_xpath('.//div[2]/span[1]/i').text # 好笑数
comment_num = item.find_element_by_xpath('.//div[2]/span[2]/a/i').text # 评论数
sheet.append([con, funny_num, comment_num])
logging.info([con, funny_num, comment_num])
if __name__ == '__main__':
for i in range(1, 14): # 翻页爬取
get_data(i)
browser.quit() # 关闭浏览器
wb.save(filename='datas.xlsx') # 保存数据
运行结果如下:
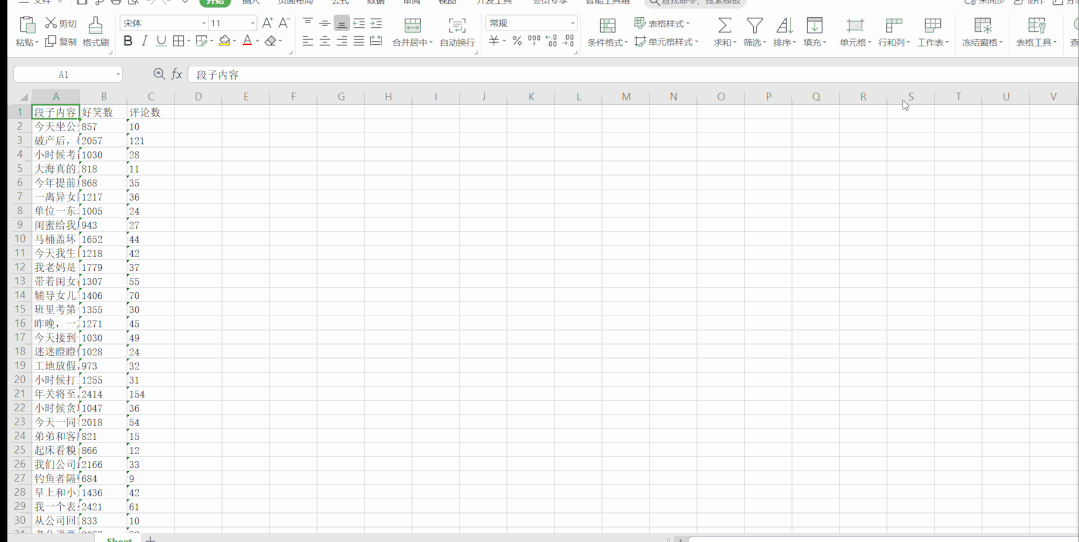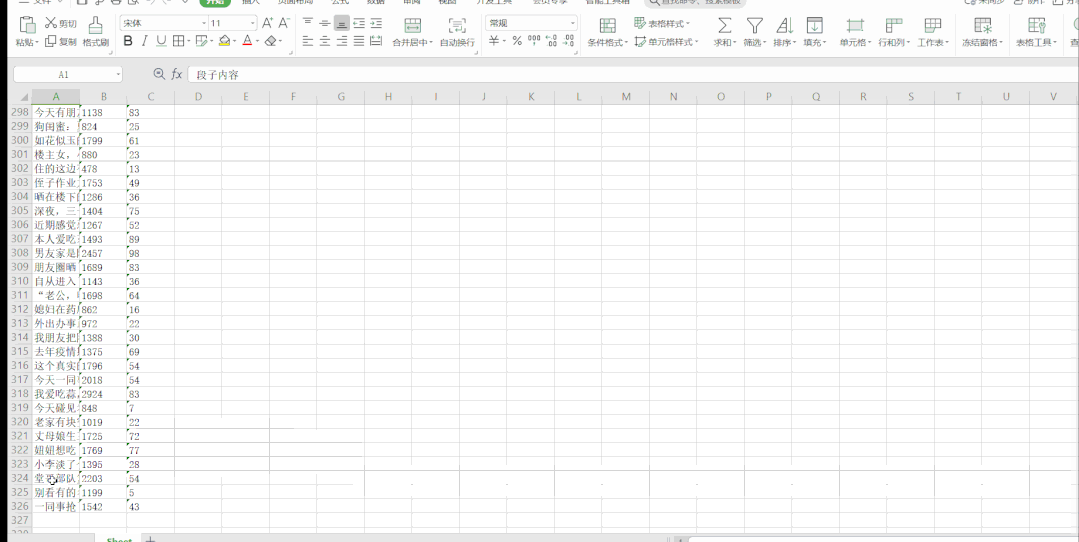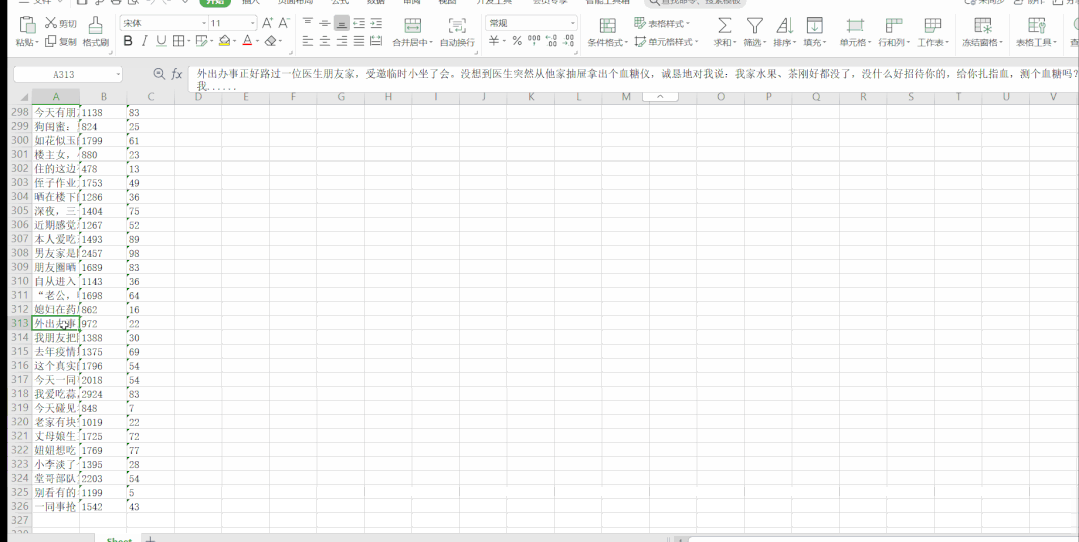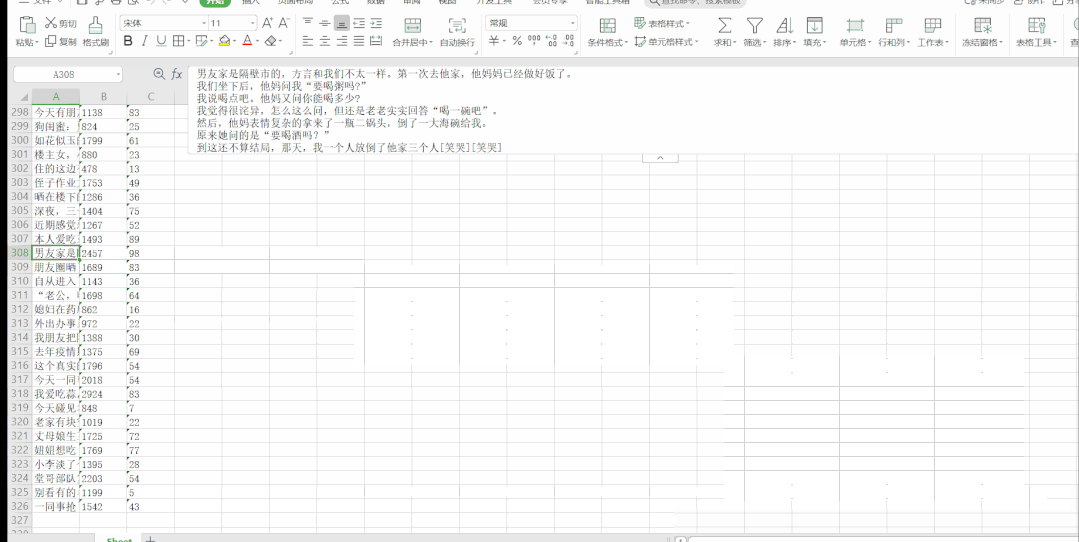
 段子信息保存到了本地 Excel 里,结果如下:
段子信息保存到了本地 Excel 里,结果如下:
绘制词云图
段子内容词云图可视化
import pandas as pd
import jieba
import collections
import re
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 读取段子数据
datas = pd.read_excel('datas.xlsx')['段子内容']
# 读取停用词数据
with open('stop_words.txt', encoding='utf-8') as f:
con = f.read().split('\n') # 得到每一行的停用词
stop_words = set()
for i in con:
stop_words.add(i)
result_list = []
for data in datas:
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
# 去除停用词和单个词
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
# 筛选后统计
word_counts = collections.Counter(result_list)
# 绘制词云
my_cloud = WordCloud(
background_color='white', # 设置背景颜色 默认是black
width=800, height=550,
font_path='simhei.ttf', # 设置字体 显示中文
max_font_size=160, # 设置字体最大值
min_font_size=16, # 设置字体最小值
random_state=88 # 设置随机生成状态,即多少种配色方案
).generate_from_frequencies(word_counts)
# 显示生成的词云图片
plt.imshow(my_cloud, interpolation='bilinear')
# 显示设置词云图中无坐标轴
plt.axis('off')
plt.show()
运行效果如下:

老婆、朋友、孩子、媳妇、同事、回家、老公等词云都是糗事百科段子内容里出现频率较高,都比较贴进生活,除此之外,"发现" 这个词也是出现频率较高的,看来有点东西。
散点图
分析评论数与好笑数之间关系,散点图可视化
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
# 读取数据
df = pd.read_excel('datas.xlsx')
funny_num, comment_num = df['好笑数'], df['评论数']
# 设置中文显示
mpl.rcParams['font.family'] = 'SimHei'
# 设置图形显示风格 ggplot
plt.style.use('ggplot')
# 设置大小 像素
plt.figure(figsize=(9, 6), dpi=100)
# 绘制散点图
plt.scatter(comment_num, funny_num)
# 添加描述信息
plt.title('段子评论数与好笑数关系-散点图')
plt.xlabel('评论数')
plt.ylabel('好笑数')
plt.show()
运行效果如下:
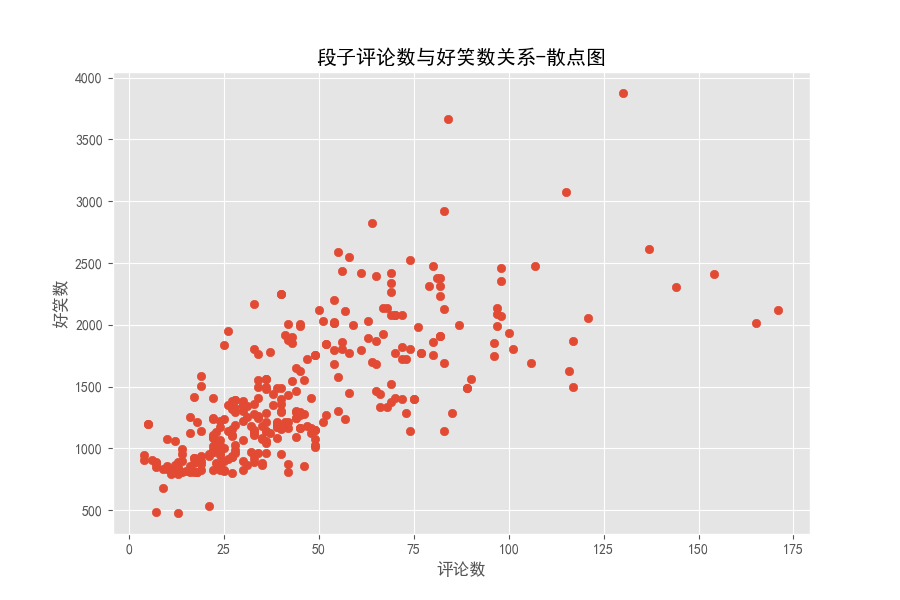
在评论数小于 50 时,点分布密集,大概还有评论数多,好笑数多的关系,评论数大于50之后,点分布非常散乱。段子的评论数和好笑数实时在变,下面来看看我们那是爬取下来的段子里评论数最多、好笑数最多的分别讲的啥。
TOP级别段子
import pandas as pd
# 读取数据
df = pd.read_excel('datas.xlsx')
# 降序排列后打印第一行 评论数最多
df1 = df.sort_values(by='评论数', ascending=False)
print(df1.values[0])
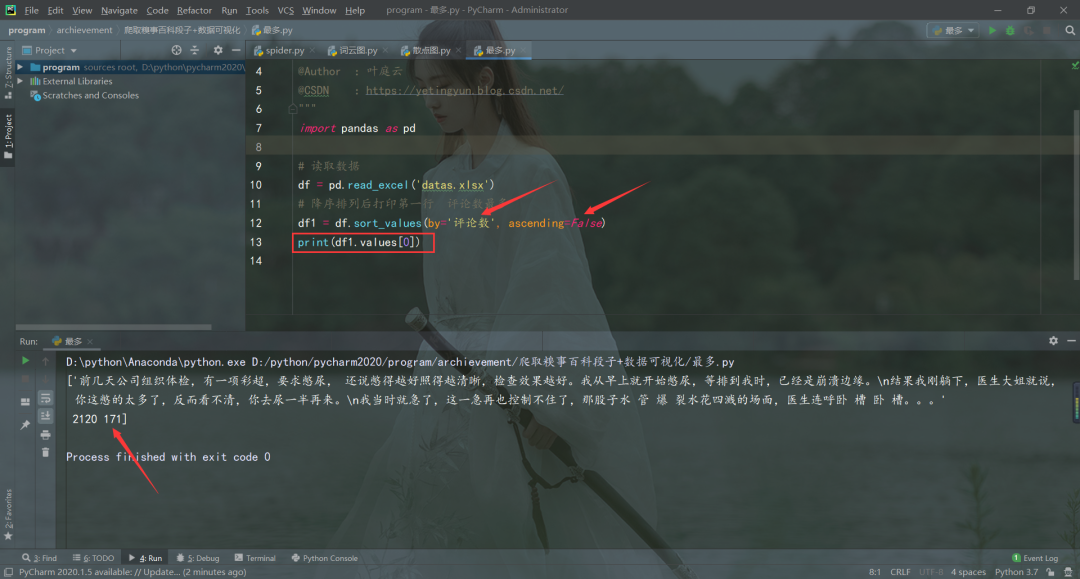
评论数最多的段子


import pandas as pd
# 读取数据
df = pd.read_excel('datas.xlsx')
# 降序排列后打印第一行 好笑数最多
df1 = df.sort_values(by='好笑数', ascending=False)
print(df1.values[0])
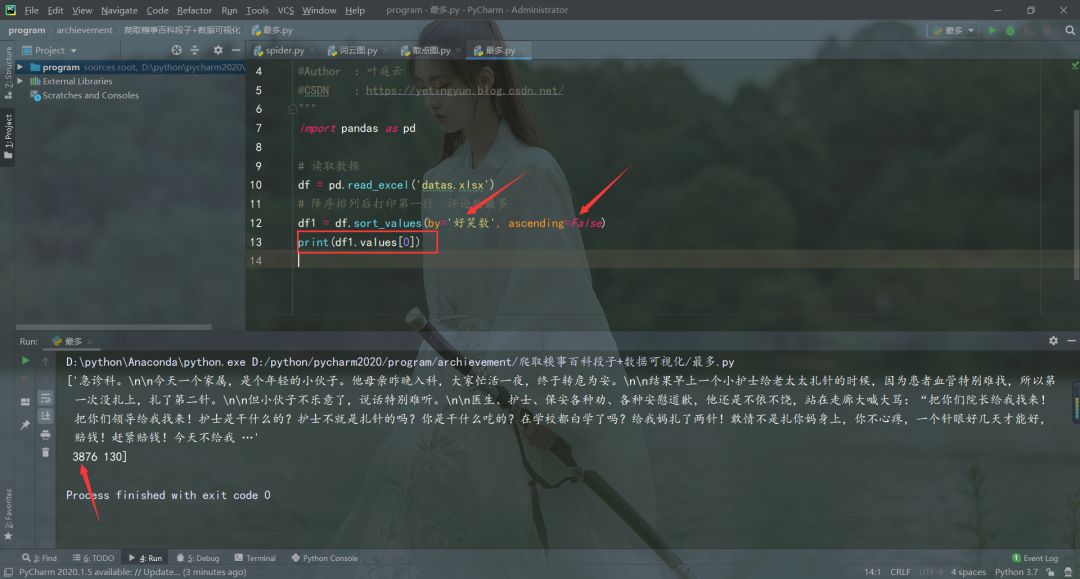
好笑数最多的段子

emmm,幽默笑话大全__爆笑笑话__笑破你的肚子的搞笑段子,就这?

作者:叶庭云
CSDN:https://yetingyun.blog.csdn.net/本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。觉得文章对你有帮助、让你有所收获的话,期待你的点赞呀,不足之处,也可以在评论区多多指正。
_往期文章推荐_
评论