
Python爬取精美壁纸,附源码

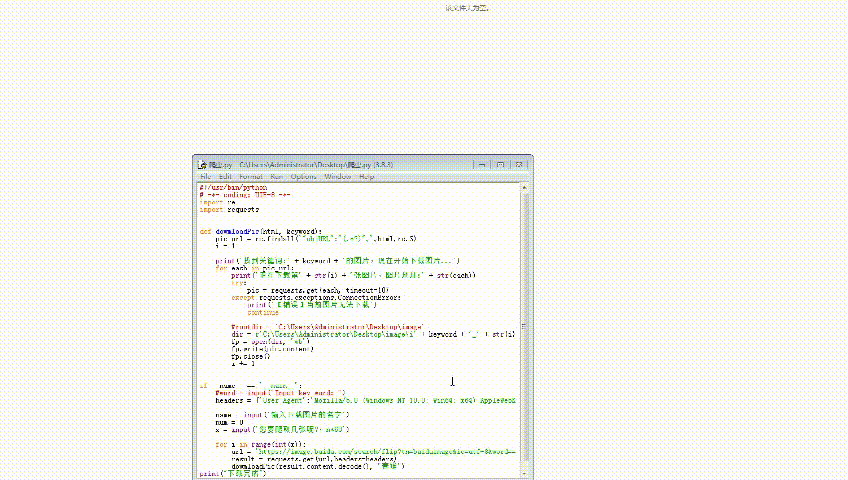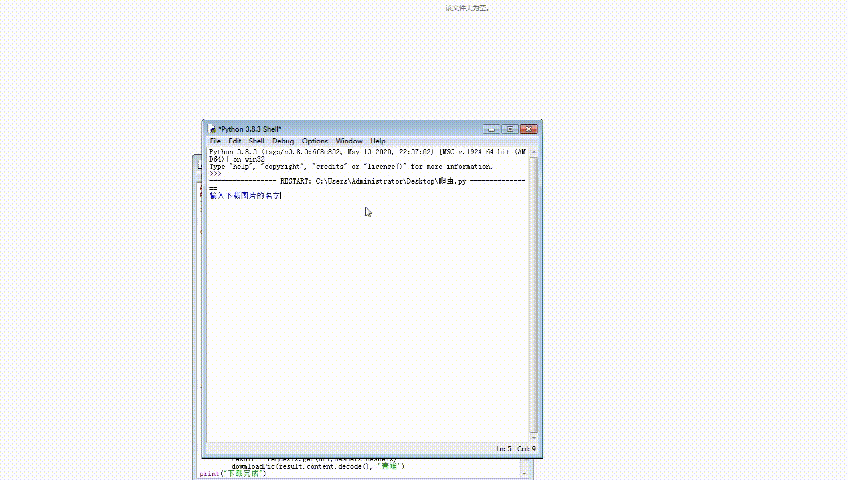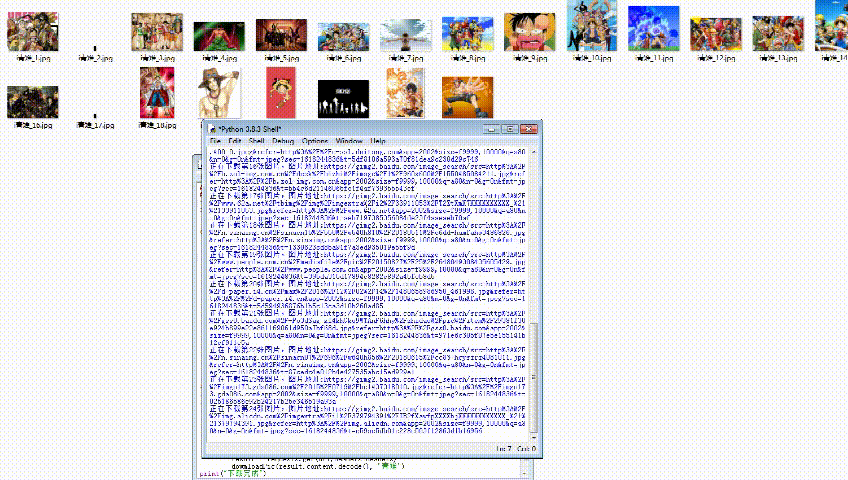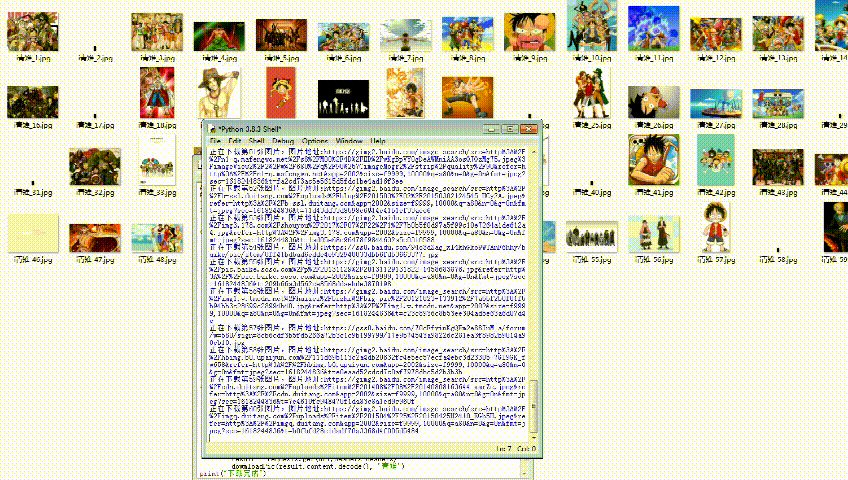
import reimport requestsimport os
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=='+name+'+&pn='+str(i*30)result = requests.get(url,headers=headers)dowmloadPic(result.content.decode(), name)
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
fp = open(dir, 'wb')fp.write(pic.content)fp.close()
#!/usr/bin/python# -*- coding: UTF-8 -*-import reimport requestsimport osdef dowmloadPic(html, keyword,i):pic_url = re.findall('"objURL":"(.*?)",',html,re.S)abc=i*60print('找到关键词:' + keyword + '的图片,现在开始下载图片...')...完整代码:请移步到,公众号:诗一样的代码dir = r'D:\image\i' + keyword + '_' + str(abc) + '.jpg'if not os.path.exists('D:\image'):os.makedirs('D:\image')fp = open(dir, 'wb')fp.write(pic.content)fp.close()abc += 1if __name__ == '__main__':#word = input("Input key word: ")headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'}name = input('输入下载图片的名字')num = 0x = input('您要爬取几张呢?,n*60')for i in range(int(x)):url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=='+name+'+&pn='+str(i*30)result = requests.get(url,headers=headers)dowmloadPic(result.content.decode(), name,i)print("下载完成")
搜索下方加老师微信
老师微信号:XTUOL1988【切记备注:学习Python】
领取Python web开发,Python爬虫,Python数据分析,人工智能等精品学习课程。带你从零基础系统性的学好Python!
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权
评论