
爬虫实战|2.5w+张4k高清壁纸爬取~
👆点击关注|设为星标|干货速递👆
大家好,我是小菜鸟~
最近在网上发现了一些非常适合猛男的壁纸,然后就用爬虫程序给爬取了下来。而且独乐乐不如众乐乐,大家一起分享快乐的同时,也可以学到一定的知识~
01
页面分析

首先我们按F12打开开发者模式,对name里面的网页进行观察,发现我们要的图片URL存在源网页中,如图:
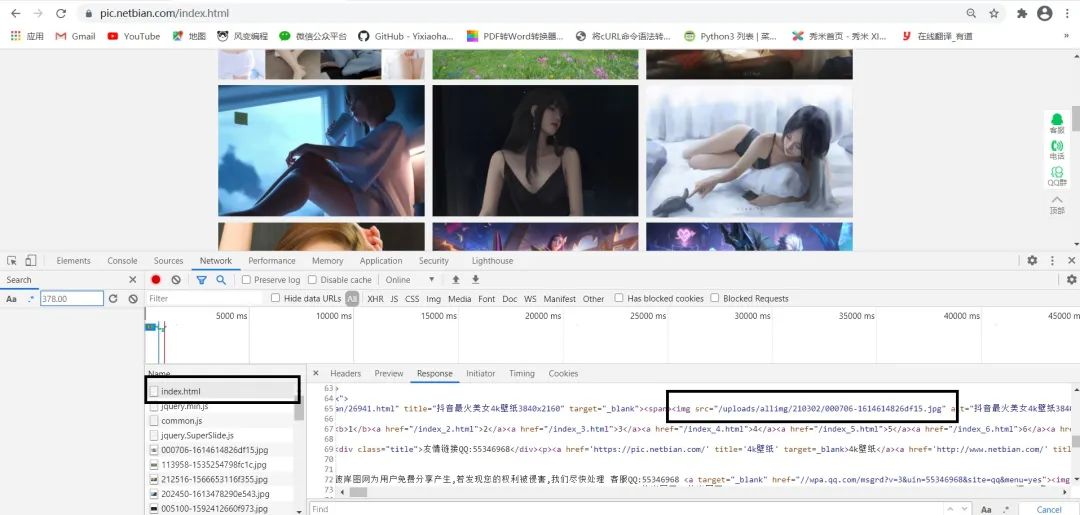
但是,我们发现这个图片的URL并不完整,我们来观察一下完整的URL,看看两者之间有何联系,如图:
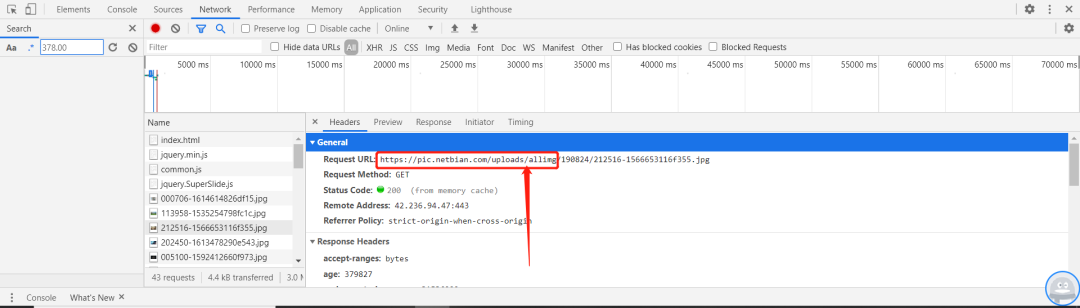
我们发现,图片的URL就是https://pic.netbian.com+src里面内容。
好,我们现在找到了数据之间的规律,我们现在就要开始提取数据了。
02
数据采集
我们结合之前的页面分析,发现选用正则表达式对图片的URL和名字进行提取最为方便,代码如下:
url = f'https://pic.netbian.com/index_{page}.html'
r = requests.get(url)
r.encoding = r.apparent_encoding
hrefs = re.findall('<img src="(.*?jpg)"',r.text)
names = re.findall('<b>(.*?)</b>',r.text)
让我们来看看提取的数据:
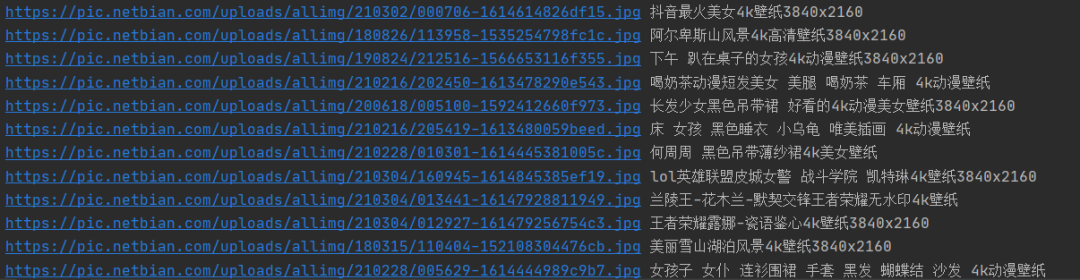
效果很好,没有什么问题,那我们就可以开始着手准备存储图片了。
03
数据存储
数据存储的方式在之前的文章已经讲的很清楚了,这里我们不在详细介绍,只提供一下图片存储的思路:图片是以二进制数据的方式存储的,我们只需将其以二进制的方式存储到txt文件中即可。代码如下:
pic_url = 'https://pic.netbian.com' + hrefs[i]
pic = requests.get(pic_url)
with open(f'{names[i]}.jpg', 'ab') as f:
f.write(pic.content)
让我们来看看效果图:

04
小结
1. 本文详细的介绍了如何获取高清4k壁纸图,请读者仔细阅读,并加以操作。
2. requests库提供了content用以提取图片二进制数据
3. 在存储二进制文件时需要在存储方式后面加个b,如‘ab’。
4. 本文仅供学习参考,不做它用
5. 后台回复[壁纸]即可获得源代码。
推荐阅读

👆点击关注|设为星标|干货速递👆
评论