
ICCV 2021 | PMF: 基于视觉感知的多传感器融合点云语义分割方法

极市导读
基于视觉感知多传感器融合点云语义分割方法 >>加入极市CV技术交流群,走在计算机视觉的最前沿
目录
Introduction Motivation Method
1.Overview 2.模块一:Perspective projection 3.模块二:Two stream network with residual-based fusion modules 4.模块三:Perception-aware loss
Experiments
1.Results on SemanticKITTI
2.Results on nuScenes
3.Results on SensatUrban
4.Adversarial Analysis
5.Effect of perception-aware loss
Conclusion
今天,我将分享一个 ICCV 2021 中的工作,基于视觉感知的多传感器融合点云语义分割方法《Perception-Aware Multi-Sensor Fusion for 3D LiDAR Semantic Segmentation》。

论文连接
https://openaccess.thecvf.com/content/ICCV2021/papers/Zhuang_Perception-Aware_Multi-Sensor_Fusion_for_3D_LiDAR_Semantic_Segmentation_ICCV_2021_paper.pdf
代码连接
https://github.com/ICEORY/PMF
1. Introduction
语义分割是计算机视觉的关键问题之一,它可以提供细粒度环境信息。因此在许多应用,比如机器人和自动驾驶中,都有极其重要的应用。
根据使用传感器的种类,目前的语义分割方法可以分为三类:基于摄像头的方法,基于激光雷达的方法和基于多传感器融合的方法。
基于相机的方法,也就是以Deeplab[1]为代表的2D语义分割方法。由于RGB图像拥有丰富的颜色、纹理等表征信息,并且得益于公开数据集的丰富性,基于相机的语义分割方法已经取得了极大的进展。但是,由于相机是被动传感器,它很容易受到光线的干扰,所以采集到的数据是经常存在噪声,对于自动驾驶等应用来说这是非常危险的。因此,近年来越来越多的研究者关注基于激光雷达的3D语义分割方法,提出了RangeNet[2]等方法。由于激光雷达是一个主动传感器,因此可以提供可靠的环境信息,此外,它还能提供空间几何信息。但是,激光雷达采集到的数据往往非常稀疏和不规则的,并且也缺乏颜色和纹理信息,这使得单纯基于激光雷达数据去进行细粒度的语义分割是非常具有挑战性的。
因此,一个非常直接的想法就是融合相机和激光雷达的两种传感器的数据来共同完成语义分割任务。
2. Motivation
已有基于多传感器数据的语义分割方法,比如RGBAL[3]和PointPainting[4],采用球面投影的方式将点云投影到图像上,获取相关的像素信息,然后将相关的图像像素投影回点云空间,在点云空间上进行多传感器融合。然而这种方式会导致相机传感器中的数据损失严重,如图1左边所示,汽车和摩托车在投影之后纹理、形状等视觉感知信息都严重丢失。

针对上述问题,作者提出基于透视投影的融合方法,来保留足够多的图像信息,如上图右边所示。

然而,如上图所示,由于透视投影得到的点云非常稀疏,这导致神经网络只能提取到局部点云的特征,而难以从稀疏的点云中提取到物体的视觉感知特征。
为了解决上述问题,作者提出了一种全新的多传感器感知融合方案(PMF),来有效地融合来自相机和激光雷达两个传感器的信息。本文的主要贡献包括以下三点:
第一,提出了一种全新的多传感器感知融合方案(PMF),可以有效地融合来自相机和激光雷达两个传感器的信息。
第二,提出的多传感器融合方法在光照极度不利(如黑夜)和点云极度稀疏的情况下,依然可以达到理想的语义分割效果。尤其在有视觉对抗样本的情况下,本文方法依然可以达到理想的语义分割效果。
第三,提出了一种全新的perception-aware loss,可以促进网络捕捉不同模态的感知信息(RGB图像的颜色和纹理,激光雷达数据的几何形状)。
所提出的方法在大规模数据集如SemanticKITTI、nuScenes和Sensat上均可以达到排名靠前的结果。并通过一系列的消融实验验证了本方法的优势和合理性。
3. Method
3.1. Overview
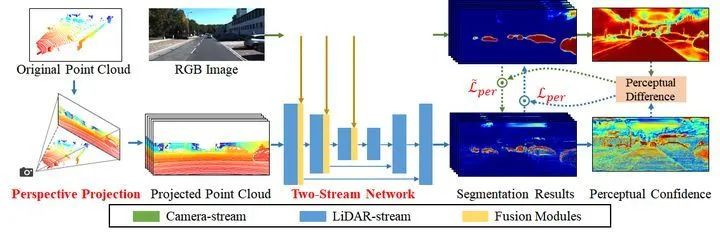
PMF方法首先使用透视投影(Perspective projection)将激光雷达数据投影到相机坐标中。然后,通过一个双流网络提取多模态数据的特征,并将多模态特征通过多个基于残差的融合块(Residual-based fusion block)融合。最后,通过将感知损失函数(Perception-aware loss)引入网络的训练,来量化两种模式之间的感知差异,并帮助网络学习到不同模态的感知特征(RGB图像的颜色和纹理,激光雷达数据的几何形状)。其结构如上图所示,主要包含三个主要的模块。
3.2. 模块一:Perspective projection

考虑到之前的方法一般采用球面投影的方式将点云投影到图像上,获取相关的像素信息,然后将相关的图像像素投影回点云空间,在点云空间上进行多传感器融合。而这导致了严重的信息损失。为了解决这个问题,作者提出基于透视投影的融合方法,通过把激光雷达数据投影到相机坐标系下,来保留足够多的相机传感器数据。
把激光雷达数据投影到图像的过程借助已知的标定参数来实现。对于投影之后的每个激光雷达点,采用跟backbone方法SalsaNext[5]一样的设计,即保留(d, x, y, z, r)五个维度的特征。其中,d表示深度值。
3.3. 模块二:Two stream network with residual-based fusion modules
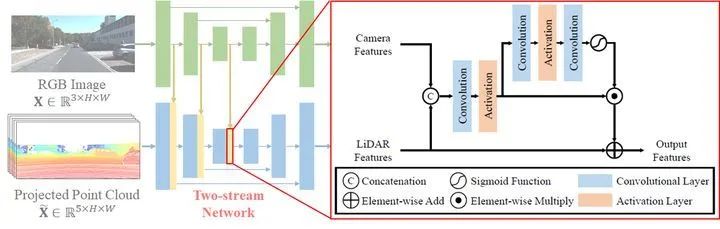
由于相机数据和激光雷达数据所包含的信息之间存在显着差异,因此,使用双分支的网络来分别处理不同模态的数据。
对于多模态特征的融合,由于考虑到相机数据很容易受到光照和天气条件的影响,导致来自相机的数据可能是不可靠的。因此,作者设计了Residual-based的融合方式,只把融合的特征作为激光雷达特征的补充,而激光雷达特征保持不变。除此之外,为了进一步消除融合特征中噪声信息的干扰,作者还加入Attention Module,来选择性的把融合之后的特征加入到激光雷达的特征中。
通过以上的设计,使得最终得到的融合特征更加可靠。
3.4. 模块三:Perception-aware loss
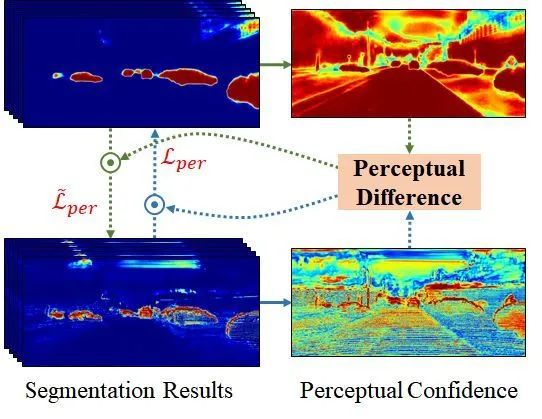
从预测结果来看,由于激光雷达分支难以从稀疏点云中捕捉感知特征,即只有在物体边缘以及有投影到的数据的地方,特征才被激活。相比之下,相机分支却可以很好地从稠密的图像数据中学习到数据的特征,如上图所见,相机分支在物体内部的特征被激活,并且特征变化具有连续性。
因此,本文提出了一种Perception-aware loss,来使网络可以更好的利用以上提到的各个分支的预测优势,最终达到更好的预测效果。具体设计如下:

为了利用图像分支的特征来提升点云分支的预测效果,首先在等式(1)中定义预测熵,然后根据等式(2)进一步计算预测置信度。由于并非来自相机分支的所有信息都是有效的,比如在物体的边缘,预测置信度会比较低,因此,通过等式(3)来衡量来自相机分支信息的重要性。由于希望不同模态的预测结果应该在语义上的分布是相似的,因此,在这里引入了KL散度。最终,通过公式(4)来计算激光雷达分支的Perception-aware Loss。
如公式(4)所述,对于激光雷达分支,完整的损失函数包含Perception-aware Loss、Focal Loss以及Lov´asz softmax Loss。
受Mutual Learning机制的启发,相机分支损失函数的设计采用和激光雷达分支相似的方案。
4. Experiments
在这一部分,展示了PMF在不同激光雷达数据集和不同天气情况下的泛化性实验结果,并引入一个对抗性实验来验证PMF在输入对抗攻击样本情况下的鲁邦性能。实验结果证明,PMF在多种情况下都具有很好的泛化性,并且可以在对抗攻击中保持高鲁棒性。
4.1. Results on SemanticKITTI
为了评估本方法在SemanticKITTI上的精度,将PMF与几种最先进的激光雷达语义分割方法进行了比较。由于SemanticKITTI只提供前视图摄像机的图像,因此本方法将点云投影到透视图中,并只保留图像上的可用点来构建SemanticKITTI的一个子集。为了评估的公平性,作者使用其他方法公开的最先进的训练模型在前视图数据上进行评估。
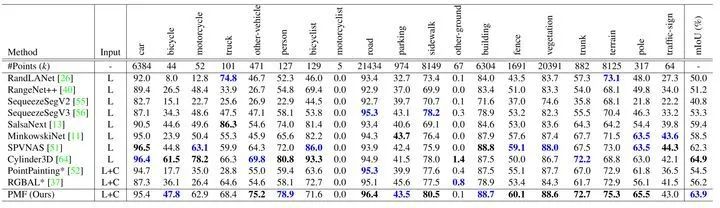
实验结果如上表所示。可以看出,PMF在基于投影的方法中达到最好性能。例如,PMF在mIoU中的性能优于SalsaNext4.5%。然而,PMF的性能比最先进的三维卷积方法,即Cylinder3D[6]相比差1.0%。但是考虑到远距离感知对自动驾驶汽车的安全性也至关重要,因此作者还进行了基于距离的评估。
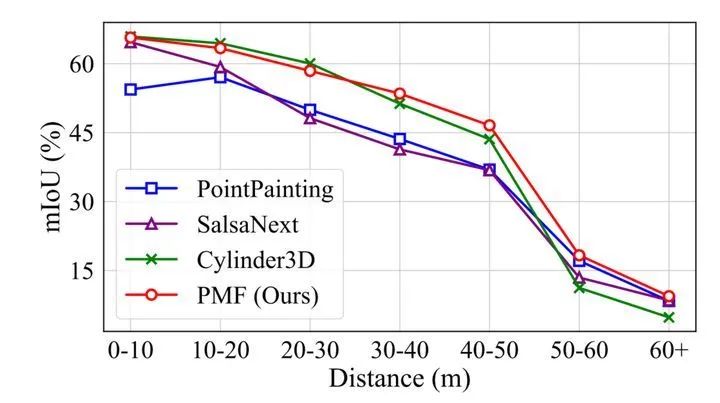
实验结果证明,当距离大于30米时,PMF的性能超过了Cylinder3D[6],达到最好性能。作者认为,这是由于相机数据可以为远处物体提供了更多的信息,因此基于融合的方法在远距离上优于仅使用激光雷达数据的方法。这也表明基于PMF更适合于解决稀疏激光雷达数据的语义分割任务。
4.2. Results on nuScenes
论文也在一个更复杂、也更稀疏的数据集nuScenes上进一步评估了所提出的方法。nuScenes的点云比SemanticKITTI的点云更稀疏(35k点/帧 vs. 125k点/帧)。

实验结果如上表所示。从结果来看,PMF 在 nuScenes 数据集上实现了最佳性能。这些结果与预期一致,即,由于PMF集成了RGB图像,因此能够在更加稀疏的点云条件下依然能达到理想的语义分割效果。

除此之外,如上图所示,PMF方法在夜晚也具有很好的语义分割效果,再一次证明了PMF方法的鲁棒性。更多的可视化结果请查看论文附录。
4.3. Results on SensatUrban
在投稿之后,此篇文章的方法还参加了SensatUrban ICCV2021竞赛。
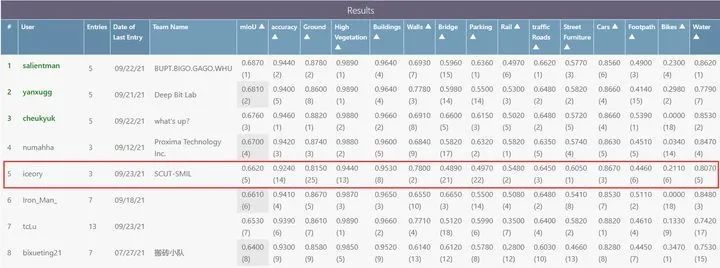
注意,因为SensatUrban数据集上数据形式的限制,所以无法使用透视投影,因此采用的是基于鸟瞰图的投影方式来处理数据的。其他关于实施方案的细节见GitHub。
4.4. Adversarial Analysis

由于真实世界总是存在一些会让汽车迷惑的场景,比如贴在公交车上的海报以及艺术家画在地面上的涂鸦。作者希望汽车在行驶过程中不会被这些场景所迷惑,否则这对于自动驾驶汽车来说将是十分危险的。
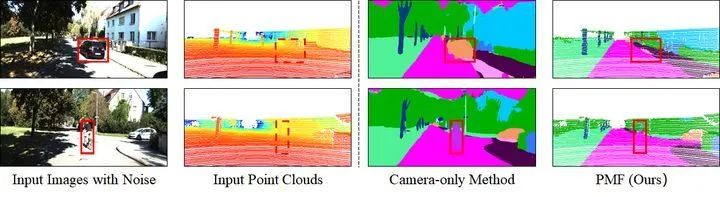
因此,为了模拟这种真实世界的场景,进一步验证方法的鲁棒性,作者从其他场景剪裁了一些物体(如上图的汽车和人),并粘贴在目标场景中来得到新的相机数据,但是并没有改变场景的激光雷达数据。
从上图的结果表明,单纯基于相机数据的方法很容易把这些粘贴上去的假物体识别为真实物体,而基于多传感器数据的PMF却不会受到这些假物体的干扰,并且可以实现精确的语义分割效果。更多的对抗攻击实验结果见附录。
值得注意的是,在这个实验中并没有使用额外的对抗攻击训练方法来训练PMF。
4.5. Effect of perception-aware loss
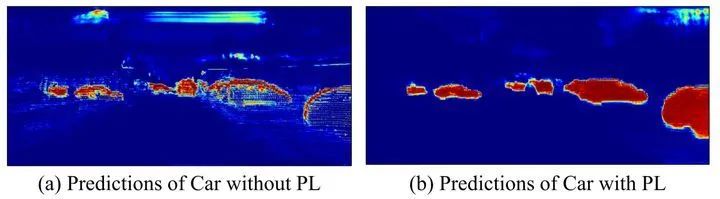
为了验证Perception-aware loss的影响,作者可视化了在有Perception-aware loss和没有Perception-aware loss情况下的激光雷达分支的预测。从上图的可视化效果来看,加入Perception-aware loss训练的模型可以学习到汽车的完整形状,而baseline模型只关注点的局部特征。这证明了Perception-aware loss的引入可以帮助激光雷达分支更好的学习到图像的信息。
5. Conclusion
最后总结一下,本文提出了一个有效的融合相机和激光雷达数据的语义分割方法PMF。与现有的在激光雷达坐标系中进行特征融合的方法不同,本方法将激光雷达数据投影到相机坐标系中,使这两种模态的感知特征(RGB图像的颜色和纹理,激光雷达数据的几何形状)能够协同融合。在两个基准数据集上的实验结果和对抗攻击实验的结果表明了该方法的优越性。表明了,通过融合来自相机和激光雷达的互补信息,PMF对复杂的户外场景和光照变化具有高度的鲁棒性。未来,作者将尝试提高 PMF 的效率,并将其扩展到其他自动驾驶任务上。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
