
激光雷达:点云语义分割算法
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
1. 前言
之前的文章中介绍了基于LiDAR点云的物体检测算法。物体检测的输出是场景中感兴趣物体的信息,包括位置,大小,类别,速度等。相对于点云数据来说,这些输出结果是非常稀疏的,只描述了场景内的一部分信息。对于全自动驾驶的应用场景,这些稀疏的信息是远远不够的。
首先,物体只是场景中的一部分内容,还有很多重要的信息是以非物体的形式存在的,比如说道路,建筑物,树木等等。如果没有这些信息,车辆就无法识别可以行驶的区域,也无法规避所有的障碍物,自动驾驶的功能也就会受到很多限制,比如说只能完成一般的AEB(自动紧急刹车)功能。
其次,即使是在物体级别,3D物体框也是一个粗略的表示。在需要更为精细的空间信息时(比如自动泊车应用),物体框的精度就不太够了,尤其是对于形状可变的物体,比如说铰接式公交车。
因此,除了物体检测以外,自动驾驶的环境感知还包括另外一个重要的组成部分,那就是语义分割。准确的说,这部分有三个不同的任务:语义分割(semantic segmentation),实例分割(instance segmentation)和全景分割(panoramic segmentation)。语义分割的任务是给场景中的每个位置(图像中的每个像素,或者点云中的每个点)指定一个类别标签,比如车辆,行人,道路,建筑物等。实例分割的任务类似于物体检测,但输出的不是物体框,而是每个点的类别标签和实例标签。全景分割任务则是语义分割和实例分割的结合。算法需要区分物体上的点(前景点)和非物体上的点(背景点),对于前景点还需要区分不同的实例。
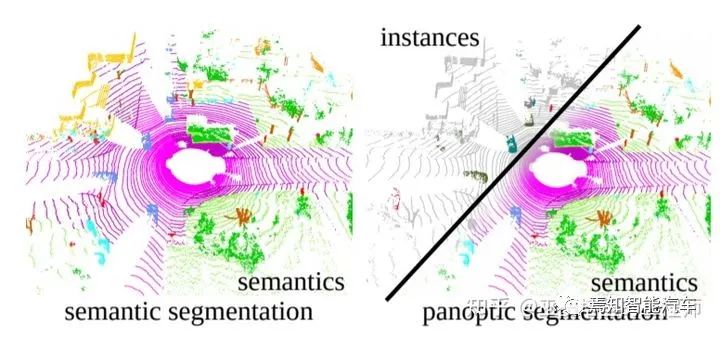
基于LiDAR点云的不同的分割任务(图片来源于参考文献[15])
2. 语义分割
语义分割和物体检测这两个任务有着很多的相似之处,其关键之处都在于如何有效的从原始点云数据中提取场景中的有用信息,以此对不同位置的语义信息进行解析。
在深度学习流行之前,语义分割一般是通过传统的监督学习算法(supervised learning)来解决的。其流程主要分为两步:首先,通过聚类算法找到每个点的邻域,在该邻域范围内进行特征提取,以此特征为基础对每个点进行分类。机器学习领域中经典的分类器,比如SVM,AdaBoost,Random Forest等等都可以采用。这一步骤与传统的点云物体检测方法非常类似。其次,以上的特征提取和分类并没有考虑大范围的上下文信息,而这部分信息对语义分割来说是不可或缺的。因此,在局部分类的基础上,还需要一个上下文模型来提高分割结果的正确性和平滑性。这里最常用的模型是Conditional Random Fields (CRF)。
一般来说,CFR可以作为一个正则项与局部分类器的优化目标相结合,从而将两个步骤整合为一个优化问题来求解。
进入深度学习时代以后,特征提取和分类的任务基本上交给神经网络来完成。我们需要设计的主要是原始数据的组织形式以及神经网格的细节。与点云物体检测算法类似,按照输入数据的不同组织形式,语义分割的方法也可以分为基于点的方法,基于网格的方法,以及基于投影的方法。当然,两个任务也有很多不同。
最显著的一点是,语义分割任务需要比物体检测任务更大范围的上下文信息。举例来说,一个车辆的检测只需要观测其局部邻域(最多几十米)的范围即可,与更远范围的场景因素关联性较弱。但是,如果要进行道路的分割,那就得观测整个场景,场景中任何一个位置的因素都有可能对道路分割的结果产生影响。这个特点也决定了语义分割的特征提取网络必须要具备更大的感受野。
2.1 基于点的方法
对于直接处理点的方法来说,PointNet[2]和PointNet++[3]是最具有代表性的。PointNet首先通过共享的MLP来提取每个点特征,然后利用池化操作再将所有点的特征合并为一个全局特征向量。对于分类任务来说,可以直接以此向量作为特征,用MLP进行分类。对于分割任务来说,需要把点特征与全局特征进行拼接,然后用MLP对每个点进行分类(也就是分配一个语义标签)。
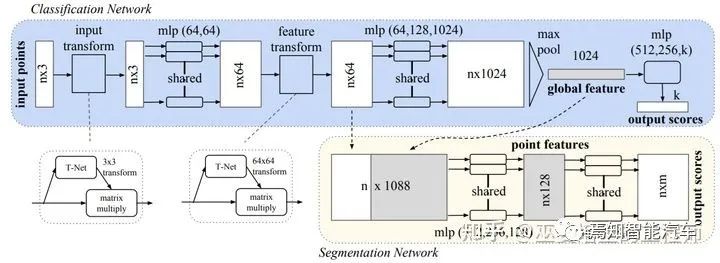
PointNet网络结构
从上面的描述中不难看出,虽然点分类的时候采用了全局+点特征,但是PointNet中的点特征提取是对每个点独立进行的,这个过程并没有用到邻域的信息。
因此,局部上下文信息在整个特征提取过程中是被忽略的,这对语义分割来说影响比较大。作为PointNet的升级版本,PointNet++用聚类的方式来产生多个点云子集,在每个子集内采用PointNet来提取点的特征。这个过程以一种层级化的方式重复多次,每一次聚类算法输出的多个点集都被当做抽象后的点云再进行下一次处理(Set Abstraction,SA)。这样得到的点特征具有较大的感受野,包含了局部邻域内丰富的上下文信息。对于分割任务来说,下一步我们需要将聚类后的点云和学习到的高层次特征再映射回原始的点云上(Point Feature Propagation)。与SA的过程类似,propagation也是一个迭代的过程。在把第L层的点云映射回L-1层时,对于L-1层的每一个点,需要从L层点云中选取其K近邻(文章中取K=3),通过插值的办法得到propagation后的特征,插值的权重根据点与点之间的距离来计算。然后,将propagation的特征与L-1层原始的特征进行拼接(skip link),并利用一个共享的全连接网络来做进一步的特征提取。这个过程重复多次,直至回到原始的点云层。最后,再用一个全连接网络来输出每个点的类别。
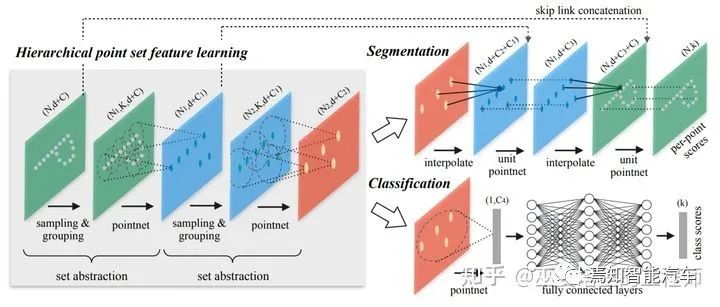
PointNet++网络结构
PointNet++的网络结构非常简洁,也具有很好的上下文特征提取能力。但是,这个系列的方法一般只能用来处理小规模的点云。在自动驾驶应用中,考虑到复杂的道路交通场景,百万级别的点云数量,以及对实时性的严苛要求,这类方法就不太适用了。这里主要的问题有两个:一个是点采样的方法(比如farthest-point sampling)对点云规模的可扩展性较差,另外一个是局部特征的学习无法适应自动驾驶中的复杂场景(学习能力不够或者感受野不够)。RandLA-Net[4]采用了随机采样的策略,极大的降低了点采样过程的计算复杂度。同时,通过局部空间编码和基于注意力机制的池化,对局部特征提取进行优化。在SemanticKITTI(点云数量约10万/帧)的测试上,RandLA-Net的速度是PointNet++的50倍,达到22FPS。语义分割的准确性方面也比PointNet++提升了一倍多(mIoU指标:53.9% vs. 20.1% )。
除了PointNet++系列以外,对点云的直接处理还可以通过Point卷积的方式进行。这类方法的主要思路是将卷积操作从网格数据移植到点云上。在传统的卷积操作中,卷积核中的权重是输入数据在空间位置上一一对应的,因此可以进行一对一的操作,比如加权求和,从而得到相应位置的输出。对于点云数据来说,点的位置是不固定的,卷积操作也无法在空间位置上找到对应关系。KPConv[5]提出在一个领域范围内定义相对位置固定的一些kernel points(类比传统的卷积核)。由于在空间位置上无法与点云对齐,因此邻域中每个点的卷积权重需要对所有kernel points权重进行加权求和来得到。这里的权重通过点和kernel points的空间距离来确定。KPConv的输入和输出都是点云,点的数量也不变,但是点特征被增强了。对于语义分割任务,我们可以采用与PointNet++中类似的策略,也就是sampling,pooling,upsampling这样的结构进一步扩大感受野,并最终得到每一个点的类别输出。
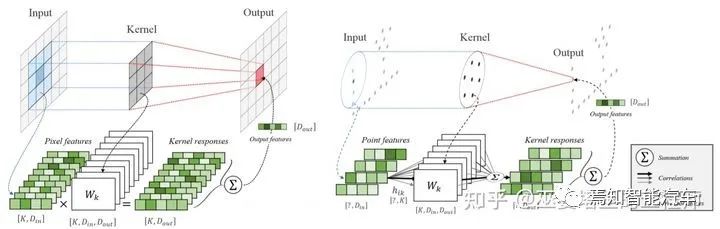
传统Conv与KPConv的对比
此外,还有一些方法采用循环神经网络(RNN)或者图神经网络(GNN)来更好的提取上下文信息,但是这些方法一般计算复杂度比较高,通常只适用于室内小规模场景的处理,这里就不做介绍了。
2.2 基于网格的方法
在3D物体检测领域的经典方法VoxelNet中,点云被量化为均匀的3D网格(voxel)。配合上3D卷积,图像语义分割中的全卷积网络结构就可以用来处理3D的voxel数据。
FCPN[6]在三维空间进行均匀采样,每个采样的位置收集邻域内固定数量的点用来提取点特征。这里与VoxelNet中的方式略有不同:VoxelNet中的网格也是均匀位置采样,邻域的大小是固定的,但点的数量则是不固定的。所以,VoxelNet中的网格数据是稀疏的,而FCPN中的网格数据则是稠密的。但是,无论哪种方式,最后得到的数据形式都是4D的张量,也就是3D网格+特征。这种数据形式可以采用3D卷积来处理,并通过一个U-Shape Net的结构来提取不同尺度的信息,最终得到原始量化尺度下的分割结果。每个网格会被分配一个类别标签,网格中所有的点共享此标签。
FCPN网络结构
Voxel的表示方式优点在于数据规整,可以采用标准的卷积操作来处理,多尺度的信息也可以很容易的通过pyramid结构来获取。其缺点在于非常依赖网格大小的选取:网格较小导致数据维度较大,影响计算速度;网格较大会丢失信息,影响分割精度。当采用较小的网格时,数据会变得非常稀疏。所以可以通过稀疏卷积的方式来提高运算效率,比如LatticeNet[7]。
2.3 基于投影的方法
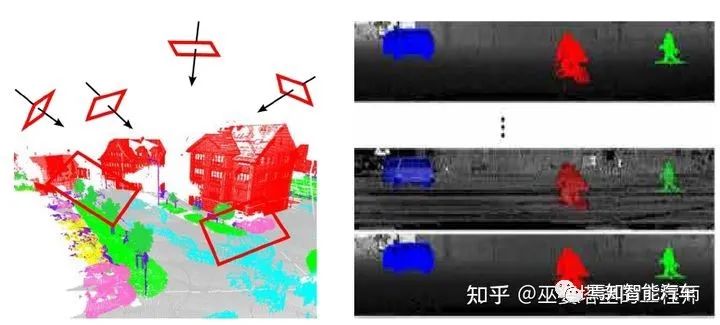
点云是存在于3D空间的,具有完整的空间信息,因此可以将其投影到不同的二维视图上。比如,我们可以假设3D空间中存在多个虚拟的摄像头,每个摄像头所看到的点云形成一幅2D图像,图像的特征可以包括深度和颜色(如果通过RGB-D设备采集)等信息。对这些2D图像进行语义分割,然后再将分割结果投影回3D空间,我们就得到了点云的分割结果。这个基于多视图的方法缺点在于非常依赖于虚拟视角的选择,无法充分的利用空间和结构信息,而且物体间会相互遮挡。
Multi-view(左)和Range-View(右)
此外,我们还可以将3D点云投影到RangeView。对于采用水平和垂直扫描的LiDAR来说,点云中的每个扫描点自然的就有水平和垂直两个角度,而且这些角度都是离散的,其个数取决于相应的分辨率。比如128线的LiDAR,其垂直角度个数就是128。假设其水平角度分辨率为0.5度,那么其扫描一周就产生了720个角度。将点云映射到以水平和垂直角度为XY坐标的二维网格上,就得到了一个720x128像素的Range图像,其像素值可以是点的距离,反射强度等。
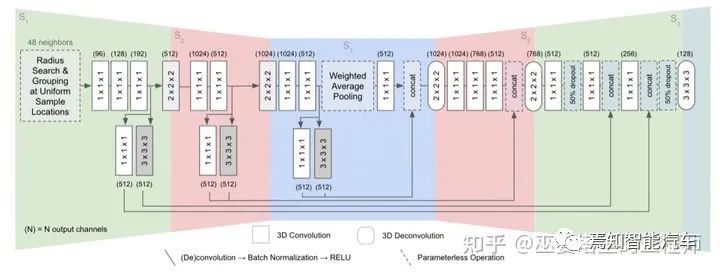
RangeNet++[8]是基于RangeView的一个典型方法。在将点云转换为range图像之后,经典的hourglass全卷积网络被用来对图像进行语义分割。之后将分割结果投影回3D空间后,再进行一些后处理,以提高分割结果的局部一致性。
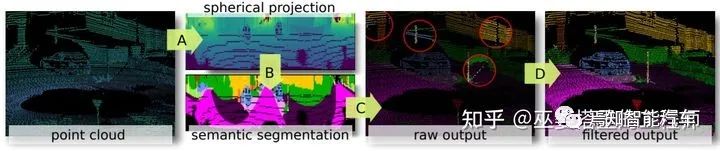
RangeNet++的组成模块
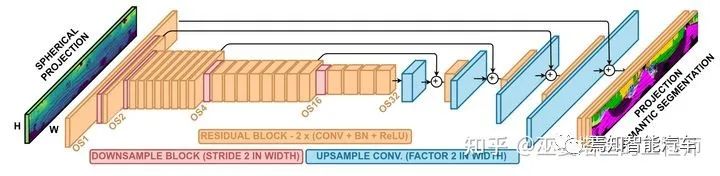
RangeNet++网络结构图
SqueezeSeg[9](及其改进版本SqueezeSegV2[10])也是基于RangeView的方法。在转换后的range图像上采用SqueezeNet网络来得到语义分割的结果,然后采用CRF对分割结果进行优化(用RNN来实现CRF)。实例级别的输出则是通过传统的聚类算法得到的。V2版本在网络结构,损失函数,批标准化(BN)以及额外的输入特征方面进行了改进,并利用了合成数据以及域适应学习(Domain Adaptation)。
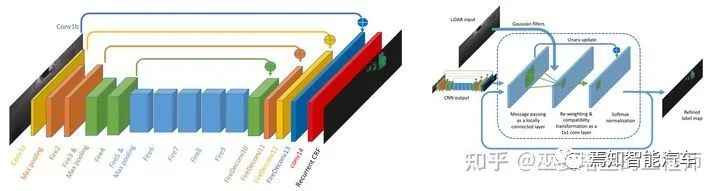
SqueezeSeg网络结构以及基于RNN的CRF实现
RangeView是一种非常紧致的数据表示,有利于减低算法的计算量,这对于自动驾驶的应用来说非常重要。因此,近年来RangeView在3D物体检测领域也受到了很多的关注。

3. 实例分割
与语义分割相比,实例分割需要对对点云进行更为精细的处理:在赋予每个点不同语义标签的同时,还需要区分不同的物体实例。实例分割可以通过两种方式来实现:自顶向下的方式和自底向上的方式。前者需要一个物体检测模型来给出候选物体框,然后再找到属于物体上的所有点;后者从语义分割的结果出发,通过聚类的方法来确定属于各个物体上的点。
3.1 自顶向下的方法
对于这类方法,物体检测是第一步也是至关重要的一步,检测结果的质量直接影响分割的效果。考虑到运行效率,对于室外大规模点云的实例分割一般会采用网格结构来表示点云,并采用类似VoxelNet中方法来进行物体检测。
LiDARSeg[11]提出了一个很典型的自顶向下的实例分割流程。首先,输入的点云数据被量化为2D网格结构,这样可以避免计算量很大的3D卷积操作。与一般的网格量化不同,LiDARSeg的每个网格包含了固定数量的点,这些点通过计算网格中心的K近邻得到。这样一来,每个网格中都有点,避免了网格数据过于稀疏的问题。在点特征设计方面,与VoxelNet类似,原始特征包括网格中心的位置,点相对于网格中心的偏移,点的高度以及反射率。
PointFC和VFE层被用来提取提取点特征以及网格内的局部信息。但是,与VoxelNet中最后采用pooling的方法来将点特征合并为网格特征不同,LiDARSeg采用类似加权求和的方式来合并网格内的点,权重通过self-attention机制自动学习得到。Backbone网络是两个hourglass结构的组合,并且两个结构之间也有一些shortcut连接。
理论上说,物体检测模块输出的3D物体框可以直接用来做实例分割:可以简单的认为物体框内的点就是实例上的点。但是,就算是手工标注的物体框,其内的点也会有大约12-16%左右是outlier(文章[11]中的统计)。因此,直接通过检测结果来生成实例分割是不准确的。在LiDARSeg中,每个网格都会输出预测的物体中心点位置和高度的范围。将临近的中心点(小于0.3m)以及其包含的点进行合并,并按照网络预测的高度范围对其进行过滤,去除outlier,这样就得到了精确的实例分割结果。
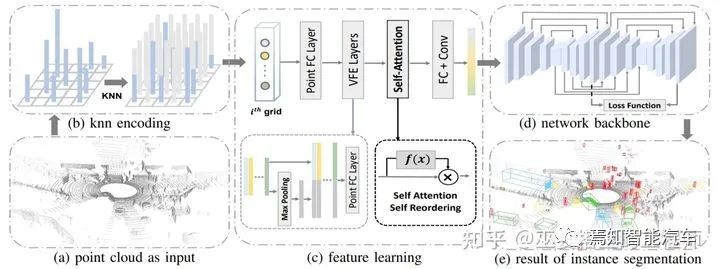
LiDARSeg网络结构图
3.2 自底向上的方法
在这类方法中没有物体检测模块,实例分割是通过对底层语义分割结果进行聚类得到的。聚类算法假设同一个实例上的点具有较大的相似度,因此如何学习更具有区分能力的点特征,以及如何将点组合成物体是这类方法研究中的重点。
SGPN[12]是这个方向早期的一个典型工作。它首先通过PointNet++来学习点的特征,这些特征作为后续三个分支的输入。语义分割的分支比较直观,就是通过点特征来预测每个点的语义标签。另外还有两个分支,一个用来生成相似度矩阵,用来得到每个点周围的聚类,另一个生成每个点的置信度,用来过滤不属于物体实例的聚类。
这个方法的关键在于相似度矩阵的这个分支。它首先要学习更具有区分性的点特征,然后以此为基础生成相似度矩阵。损失函数分为三个部分,分别对应三种不同的点对:属于相同语义且相同实例的点对,属于相同语义但是不同实例的点对,以及不属于相同语义的点对。特征学习的目标则是要使第一类点对的特征相似度较高,第二类和第三类则相对较低(这两类的权重也不尽相同)。最后,将通过相似度矩阵得到的聚类进行后处理(合并和过滤),以得到最终的实例分割结果。
SGPN由于要计算每两个点之间的相似度,计算复杂度(O(n*n))会随着点数量的增加而急剧增加,因此只适用于室内小规模的点云处理。这其实也是这一类方法的一般性问题:聚类算法对于点云规模的扩展性较差。因此,对于自动驾驶场景中的大规模点云分割,一般还是会采用自顶向下的方式。

SGPN网络结构图
4. 全景分割
全景分割可以看作语义分割和实例分割的结合。基于LiDAR点云的全景分割研究处于刚起步的阶段,其主要需求来源于自动驾驶,机器人等领域。尤其是在自动驾驶应用中,点云的空间覆盖范围和数量规模都很大,场景中包含大量不同尺寸的物体,背景非常复杂,对算法的精确度和实时性的要求也非常高。
点云的全景分割一般从语义分割出发,通过聚类来得到物体的分割结果,这个思路其实与实例分割中的自底向上的方法是非常类似的,比如前面提到的SGPN。但是其聚类算法的计算复杂度太高,导致其无法应用到大规模的点云上。下面介绍一个最新的点云全景分割算法,让我们来看看它是如何显著降低计算复杂度的。
Panoptic-PolarNet[13] 该方法采用BEV下的2D网格来表示数据,这样可以利用2D卷积提高数据处理效率,高度方向也基本不会有重叠的物体,因此也不会丢失信息。但是,一般的2D网格采用笛卡尔坐标,而该方法中采用极坐标,这样可以在近距离区域降低量化误差,提高特征提取能力。除此之外,点特征的提取采用MLP加MaxPooling的方式,最终每个网格得到一个定长的特征向量(C=512)。整个特征提取过程只包含了量化,MLP和Pooling,非常的简洁,计算复杂度非常低。
主干网络方面,同样是采用结构非常的简单的U-Net,并且语义和实例分支共享除了最后一层之外的所有特征,这也对减少计算量非常有帮助。语义分支在每一个网格位置都输出多个预测,并映射回3D网格,以区分不同高度的语义类别(比如物体和路面)。训练过程中的loss也是在3D网格空间计算的。实例分支类似于视觉任务中流行的CenterNet结构,在每个2D网格处输出物体中心出现的置信度(heatmap)和中心点相对于网格中心位置的偏移(offset)。
有了以上信息以后,全景分割的模块首先在heatmap上通过NMS生成top K个物体中心点,并根据offset来确定它们的精确位置,然后在语义分割结果上提取前景mask。前景中的每一个点找到距离最近的物体中心,并以此进行聚类,每个聚类的类别由其中点的语义类别来决定。所有这些操作都可以在GPU中进行,计算效率很高。
最后,我们来总结一下。在Panoptic-PolarNet中,语义分支提供了3D的语义分割结果,每个点都有一个语义标签。实例分支提供物体中心位置,与语义分支输出的前景点相结合得到每个实例的分割结果。这样,全景分割的任务就完成了。此外,网络中所包括的2D网格数据结构,U-Net,中心点预测等都是非常简洁的结构,可以在GPU中高效的实现,因此整个系统的速度也就提升了上来,达到约12FPS。由于一般LiDAR的工作频率是10FPS,Panoptic-PolarNet的速度已经可以满足实时的要求。
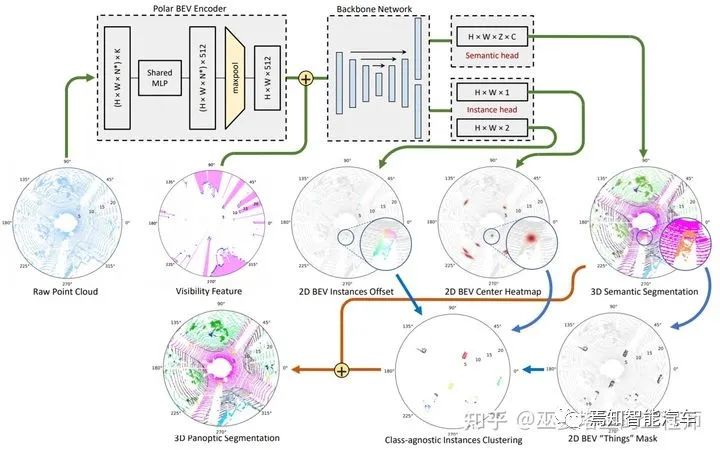
Panoptic-PolarNet网络结构图
3D点云的全景分割是一个比较新的研究方向,而图像的全景分割研究则相对成熟。因此,与语义分割类似,有的方法(比如[14])会将3D点云转换为range视图,在此数据上进行图像全景分割,再把分割的结果映射回3D空间。此外,还有的方法(比如[15])研究如何利用时序信息来提高全景分割的效果,这也是与自动驾驶应用场景非常相关的。
5. 数据库和算法对比
以上的部分主要介绍了不同分割任务中的代表性算法,以及它们的优缺点,主要都是定性的分析。这部分会系统的介绍点云分割任务的常用数据库和评测指标,并对上文提到的典型算法进行对比。点云数据库按照不同的场景和不同的采集设备可以分为很多种类。这里只关注室外道路场景,面向自动驾驶应用,由车载LiDAR采集的点云数据库,以及相关的算法对比。
5.1 数据库
SemanticKITTI
KITTI是图像和点云检测领域最常用的数据库之一。SemanticKITTI[16]将KITTI数据库中Visual Odometry Benchmark中的所有LiDAR点云序列进行标注,是第一个大规模的面向自动驾驶场景的3D点云语义分割数据库。
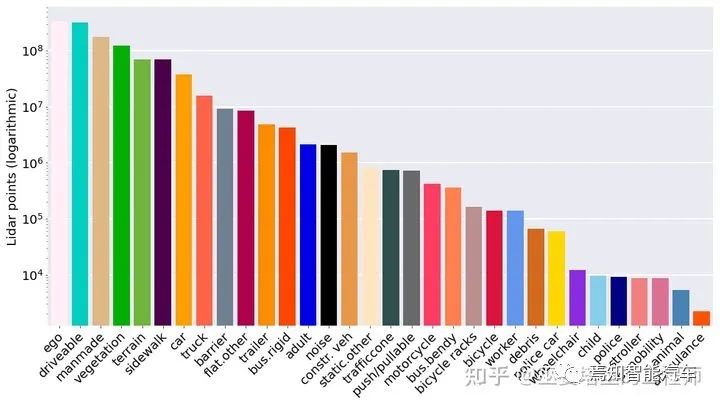
SemanticKITTI的点云数据是通过Velodyne64线激光雷达采集,共有22个序列,训练集和测试集分别包含23021和20351帧点云,每帧大约10万个点,标注的语义类别为28个。之后,SemanticKITTI又增加了实例级别的标注,实例的ID在时序上也是一致的,可以用来作为全景分割和物体跟踪的评测[17]。

SemanticKITTI数据库的标注分布(可移动物体在静止状态时用实心柱表示)
nuScenes
nuScenes[18]数据库由知名的汽车零部件供应商APTIV旗下的子公司Motional发布,专门面向自动驾驶应用,包含了1000段城市道路交通场景,数据由6个摄像头,5个毫米波雷达和1个激光雷达采集。这也是第一个包含了自动驾驶三个主要传感器的公开数据库。
nuScenes的点云数据在全部1000个序列的40000个关键帧上进行了标注,每帧大约3万个点。标注的语义类别共有32个,其中包括23个前景类别和9个背景类别。nuScenes目前没有公开的实例标注,研究者一般会自己进行额外的实例标注,以测试全景分割算法。
nuScenes数据库的标注分布
5.2 评价指标
在语义分割任务中,点云中的每个点被算法赋予一个预测的语义标签。将此预测的标签与人工标注的标签进行对比,对于每个类别我们统计三个指标:TP(True Positive),FP(False Positive)和FN(False Negative)。语义分割中常用的mean IoU指标可以通过下面的公式来计算,这里的C是类别的个数。
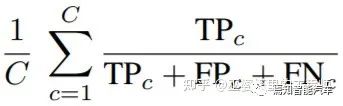
在全景分割任务中,算法不仅给每个点分配一个语义标签,还需要给属于物体类别的点一个实例标签(ID)。这种情况下,一个常用的评测指标是PQ (Panoptic Quality),其计算方式如下。其中S和S'分别表示标注和预测的实例点集,当两个集合的IoU大于一个阈值时(比如0.5),则认为是TP。FP和FN也可以通过类似的方式得到。这与物体检测领域的评测是非常类似的。PQ这个指标对于每个类别单独计算,然后取其均值作为最终的指标。在PQ指标中,非物体类别是作为一个大类来计算的,因此并不区分这些类之间的分割错误。这些错误可以通过语义分割的指标mIoU来衡量。
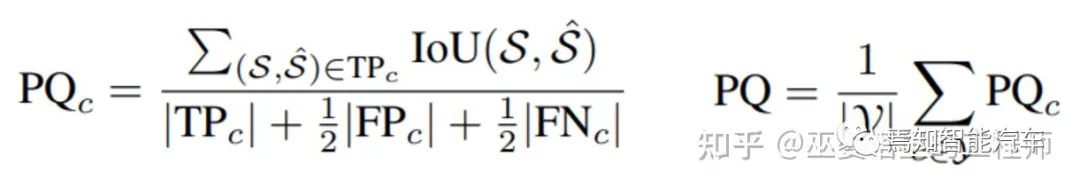
5.3 算法对比
有了数据库和评价指标,下面我们就来对比一下前文提到的一些典型算法。
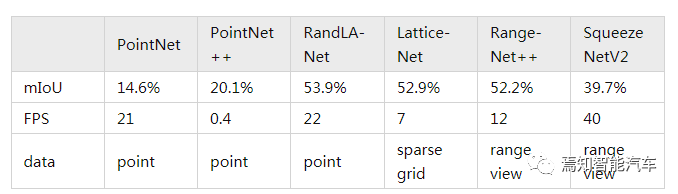
对于语义分割任务,下表对比了不同算法在SemanticKITTI上单帧的准确度(mIoU)和速度(FPS)指标。从这个对比中可以看出,基于Point的RandLA-Net和基于RangeView的RangeNet++在准确度和速度方面有着比较好的平衡。
对于全景分割任务,由于其研究刚刚起步,因此可用来对比的方法并不多。这里我们采用SemanticKITTI中定义的两个全景分割的baseline算法:KPConv + PointPillars和RangeNet++ + PointPillars。这些算法前面都介绍过,分别是语义分割和物体检测领域的经典算法。所以说,这两个全景分割的baseline其实就是语义分割和物体检测算法的组合。从下表的对比中可以看出,前面介绍的Panoptic-PolarNet无论是在准确度(PQ)还是速度(FPS)方面,相比于baseline算法有了很大程度的提升。

参考文献
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!