
视觉传感器:2D感知算法
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
1 前言
2 物体检测
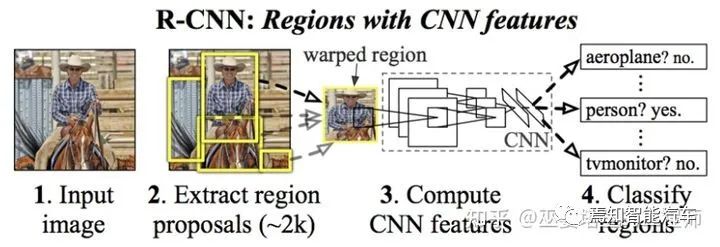
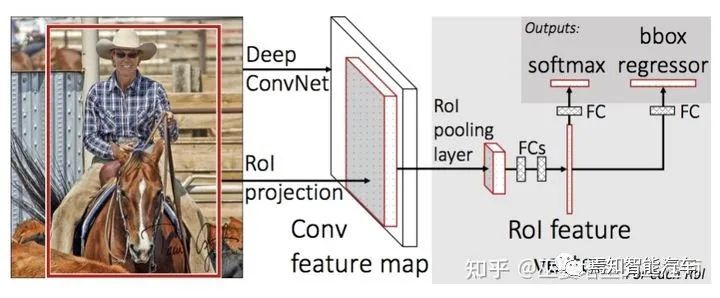
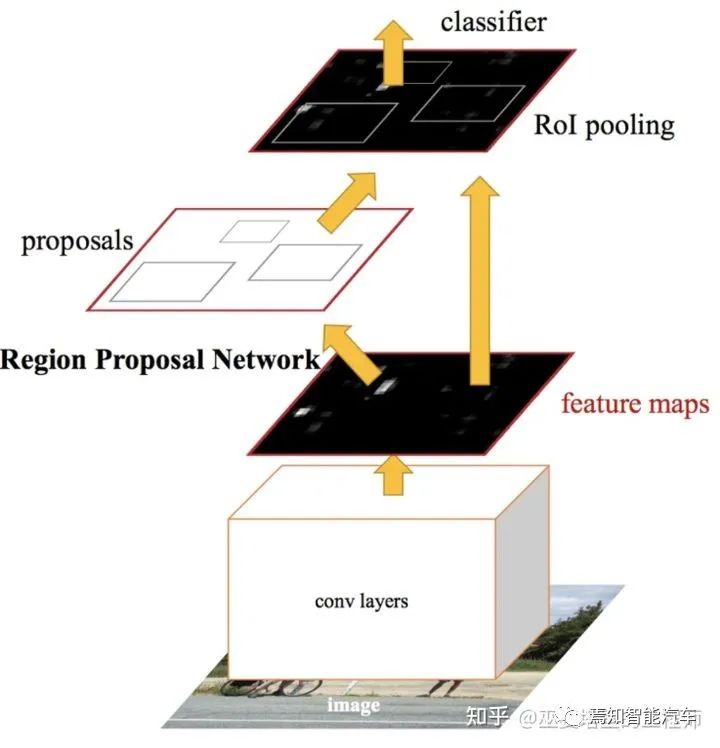
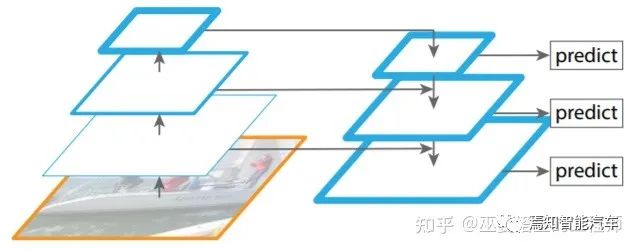
2.1 两阶段检测
2.2 单阶段检测
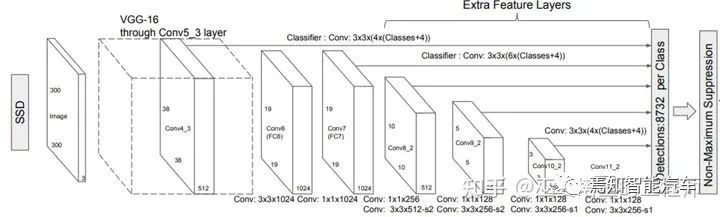
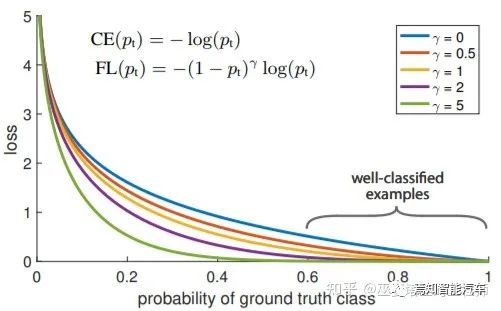
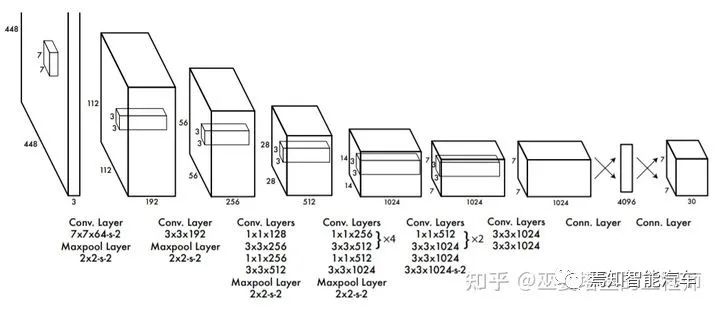
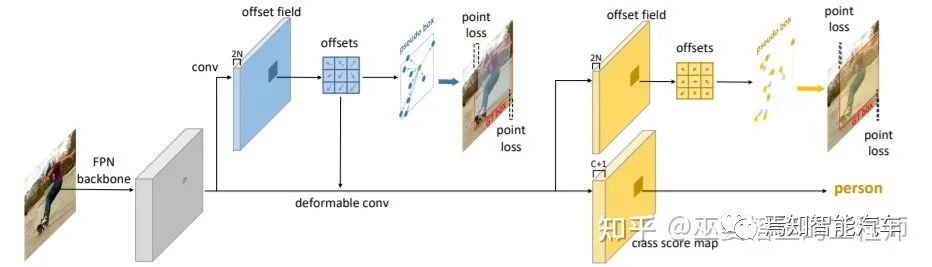
2.3 无Anchor检测

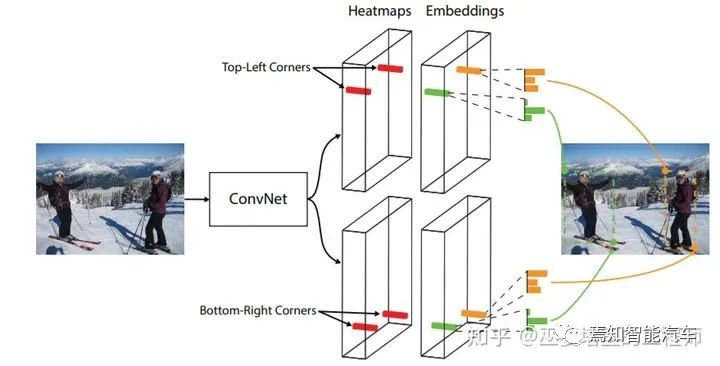

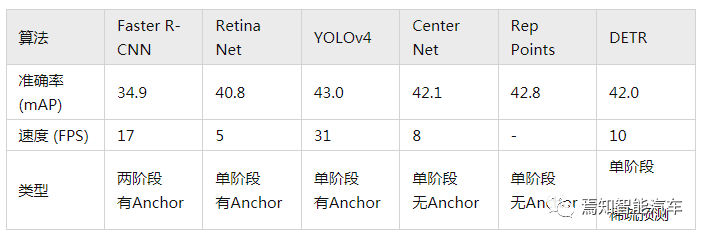
2.4 性能对比
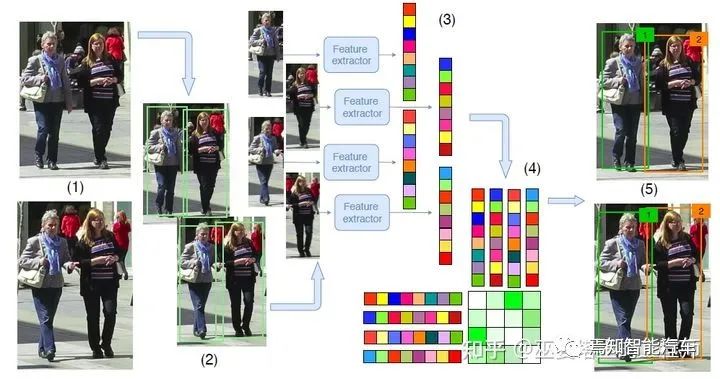
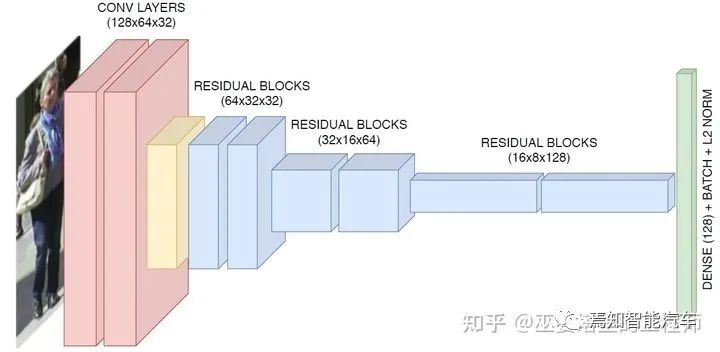
3 物体跟踪
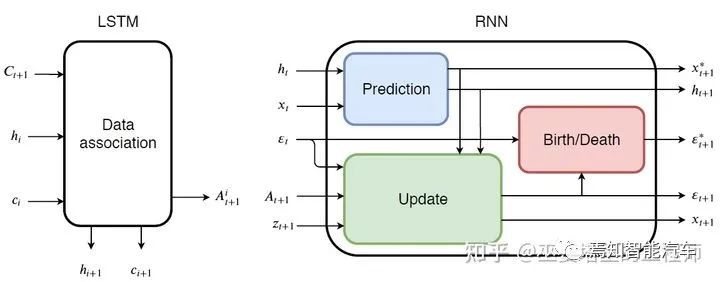
由物体检测器在单帧图像上得到物体框输出。 提取每个检测物体的特征,通常包括视觉特征和运动特征。 根据特征计算来自相邻帧的物体检测之间的相似度,以判断其来自同一个目标的概率。 将相邻帧的物体检测进行匹配,给来自同一个目标的物体分配相同的ID。

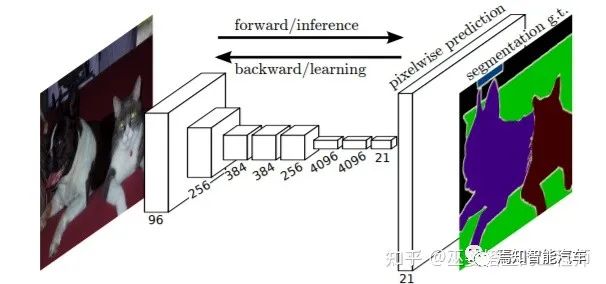
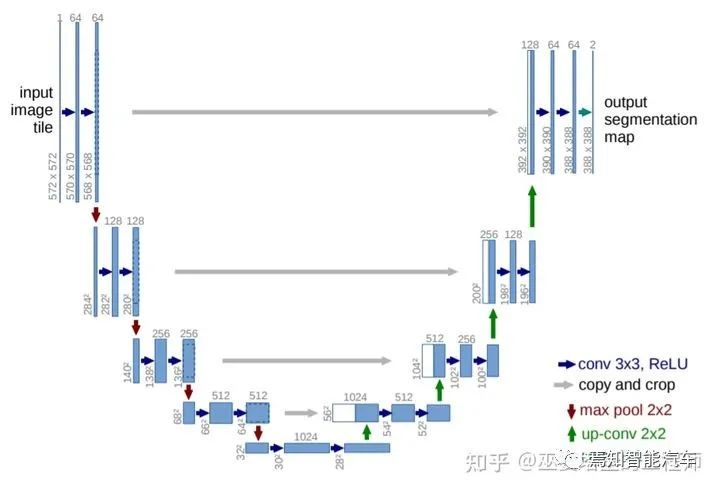
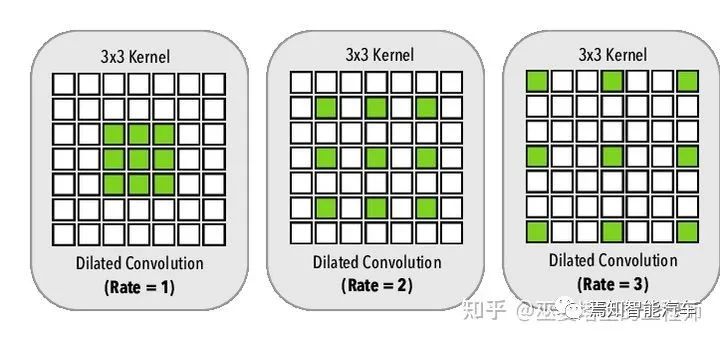
4 语义分割
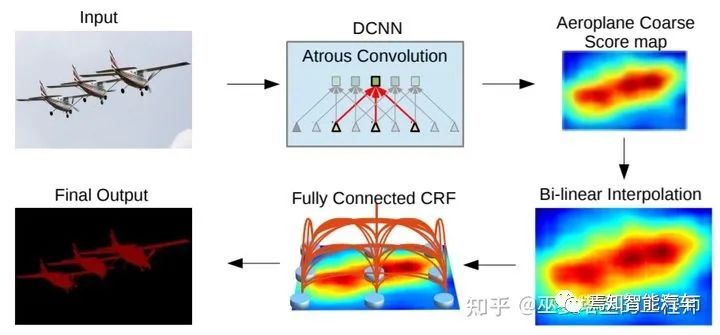
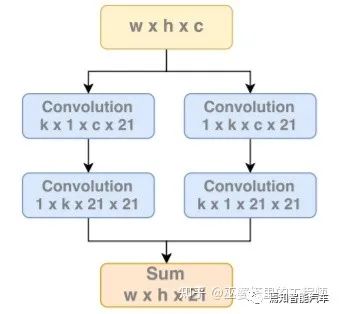
参考文献:
[1] Girshick et al., Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, 2014.
[2] Girshick, Fast R-CNN, 2015.
[3] Ren et al., Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
[4] Lin et al., Feature Pyramid Networks for Object Detection, 2017.
[5] Liu et al., SSD: Single Shot MultiBox Detector, 2015.
[6] Lin et al., Focal Loss for Dense Object Detection, 2017.
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
评论