
支持向量机背后的数学 -对于SVM背后的数学和理论解释的快速概览及如何实现
标签:支持向量机 数学

支持向量机(SVM)介绍
支持向量机(SVM)是怎么工作的
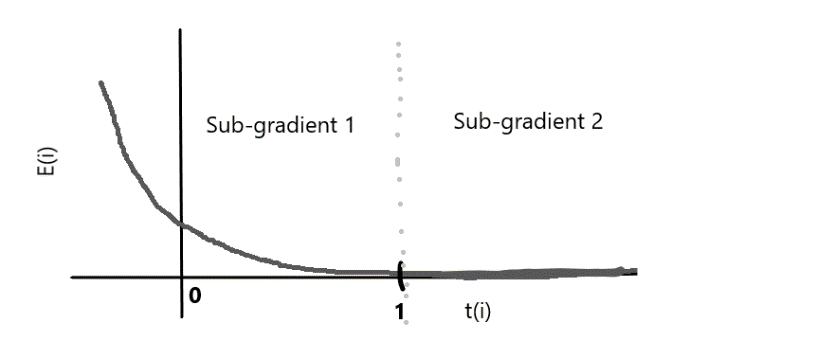
处理异常值
PEGASOS法
非线性回归分类
支持向量机(SVM)的优劣
可视化支持向量机(SVM)
支持向量机(SVM)的应用
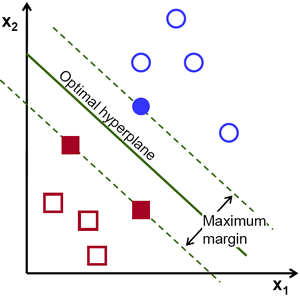
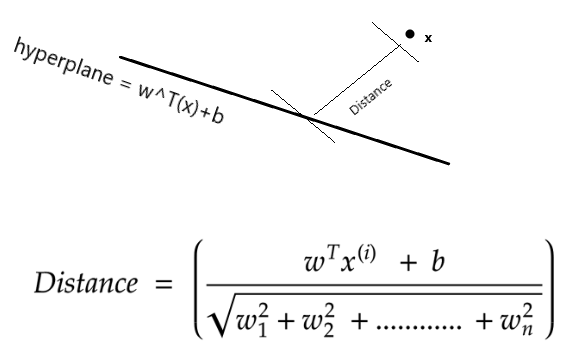
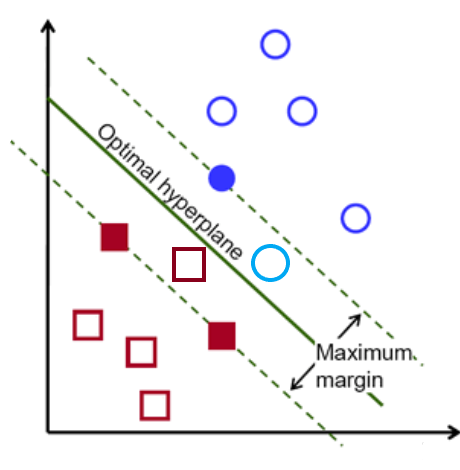
(上图注释:最优超平面:Optimal hyperpline;最大间隔:Maximum margin)

目标:找到最佳的超平面
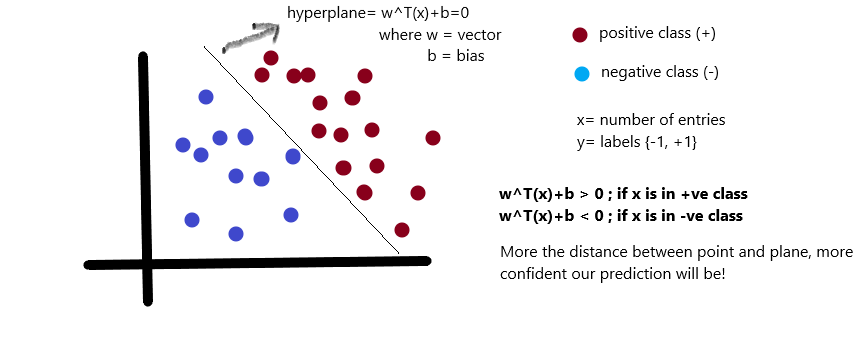
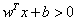 是正的,反之是负的。由于我们需要找到所谓的“最近距离”的支持向量,那么肯定点越多越好了,因为这样提供距离的点越多,就越准确)
是正的,反之是负的。由于我们需要找到所谓的“最近距离”的支持向量,那么肯定点越多越好了,因为这样提供距离的点越多,就越准确)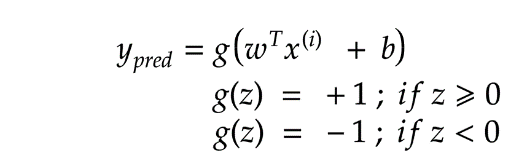
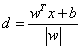
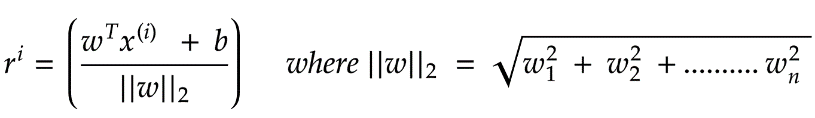
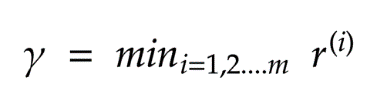
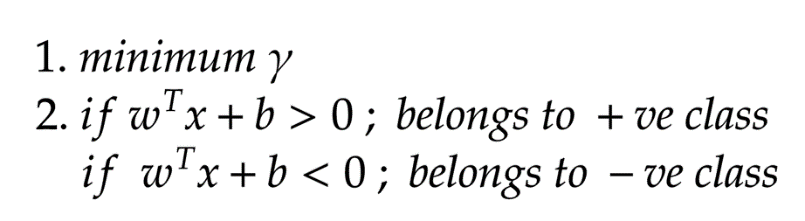
 ,
, 为函数间隔,结合两者同号我们可以写成
为函数间隔,结合两者同号我们可以写成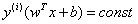 形式,最大化距离则意味着
形式,最大化距离则意味着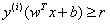 ,因为我们的目标也是最大化r)。因此,我们将以支持向量必须位于超平面上的方式对数据重新正则化。
,因为我们的目标也是最大化r)。因此,我们将以支持向量必须位于超平面上的方式对数据重新正则化。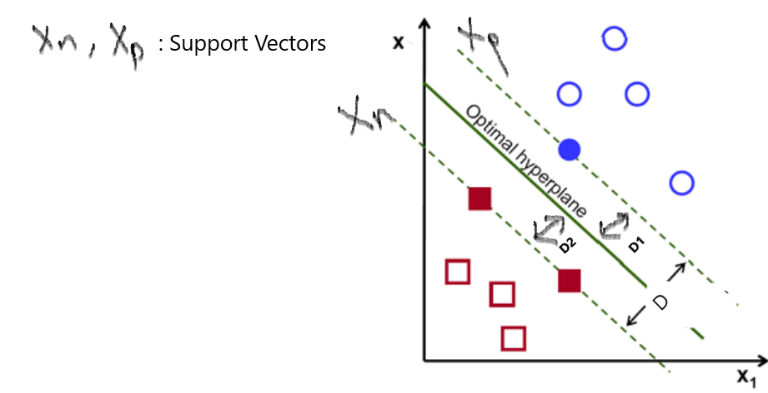
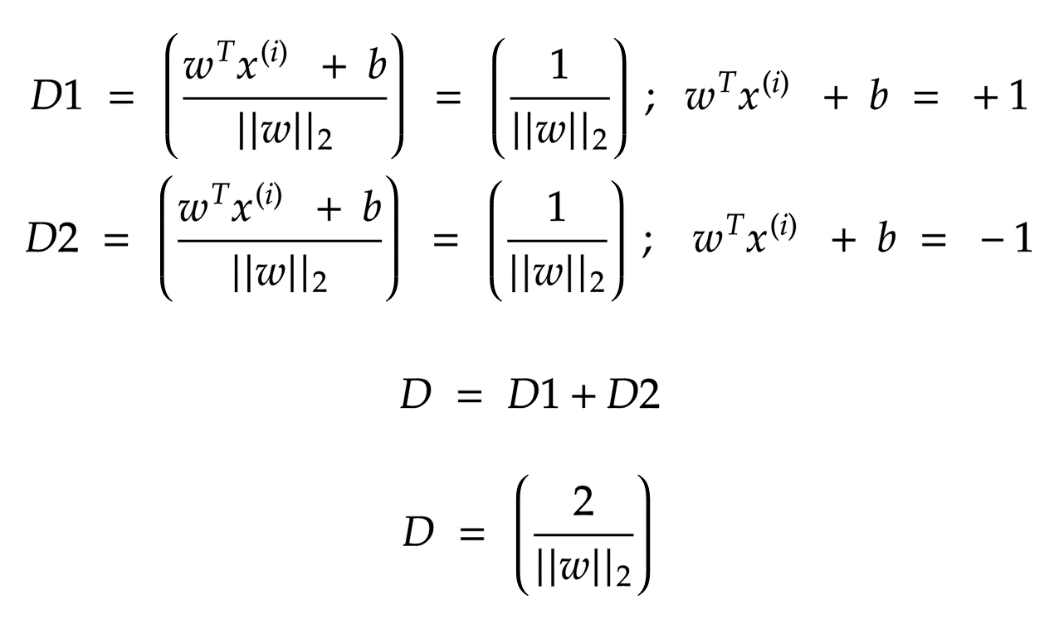
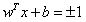 )的情况下减少“ || w ||”。
)的情况下减少“ || w ||”。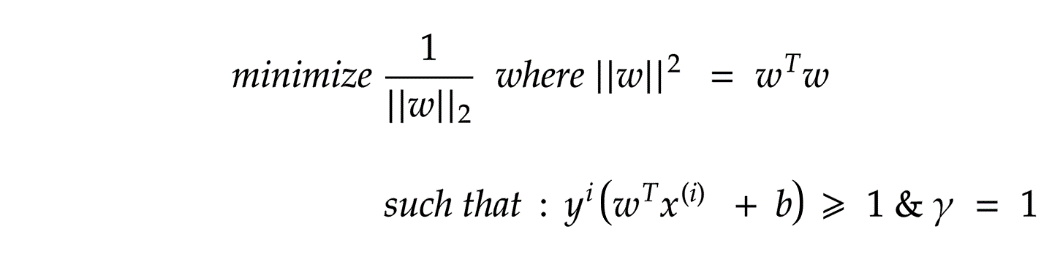

二次方程求解器
拉格朗日量密度
PEGASOS算法
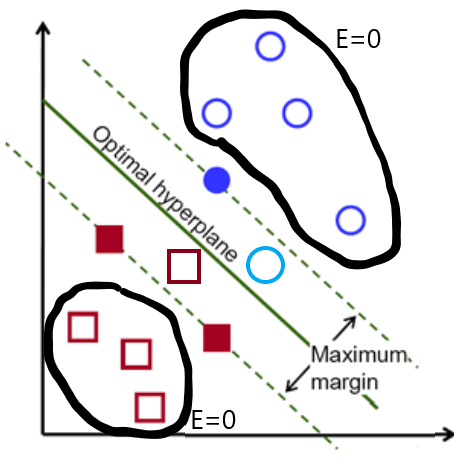
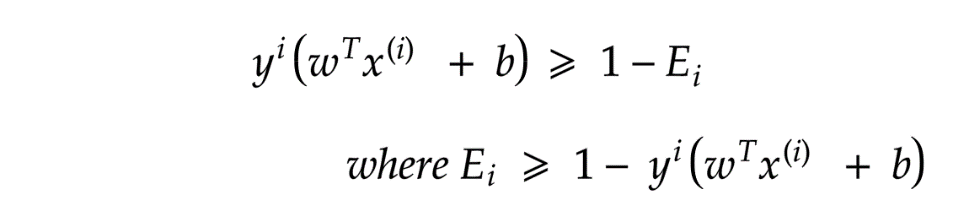
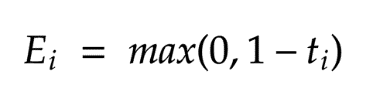
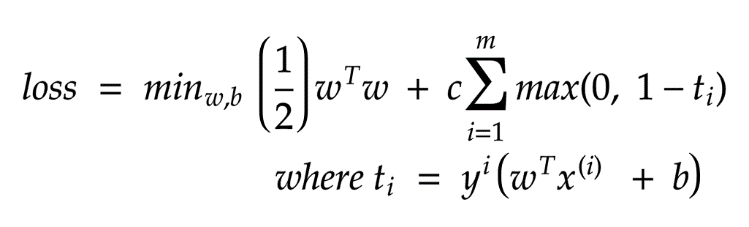
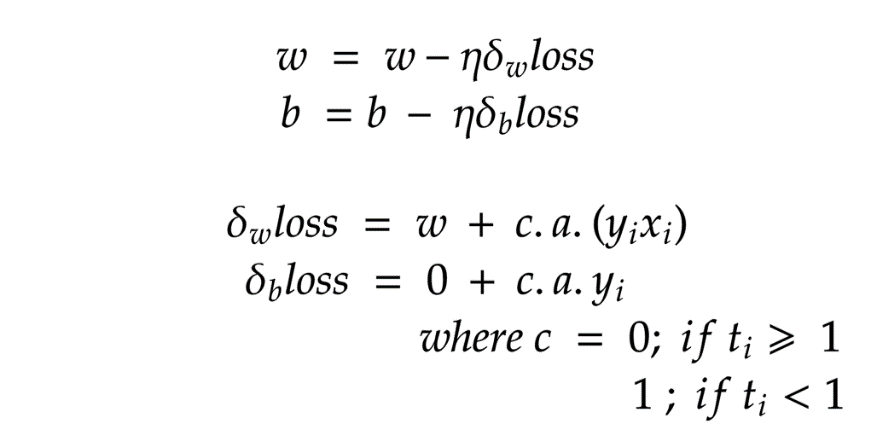


线性核
RBF(径向基)核
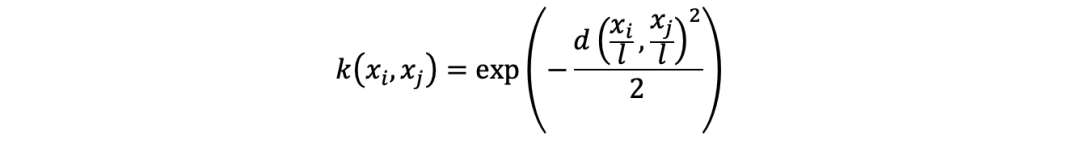
多项式核
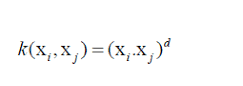
Sigmoid核
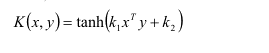
params= [{‘kernel’:[‘linear’, ‘rbf’, ‘poly’, ‘sigmoid’], ‘c’:[0.1, 0.2, 0.5, 1.0, 2.0, 5.0]}
cv: 交叉验证(cross-validation)
n_jobs: 可用的CPU数量
可以轻松处理大型特征空间
核技巧是支持向量机的真正优势,因为它有助于找到甚至更复杂问题的解决方案
适用于线性和非线性数据
不容易出现过拟合的现象
甚至适用于非结构化数据
对噪音敏感
选择最佳核比较困难
大型数据集的训练时间长

支持向量机的应用
推荐阅读
(点击标题可跳转阅读)
学深度学习是不是需要先学机器学习? 清华大学公开课:数据挖掘理论与算法
老铁,三连支持一下,好吗?↓↓↓
评论