
【NLP】中文情感分类单标签
章节
背景介绍
预处理
完整的 GitHub 项目代码地址:
https://github.com/sherlcok314159/ML/blob/main/nlp/practice/sentiment.md
背景介绍
这次的任务是中文的一个评论情感去向分类:

每一行一共有三个部分,第一个是索引,无所谓;第二个是评论具体内容;第三个是标签,由0,1,2组成,1代表很好,2是负面评论,0应该是情感取向中立。
数据预处理
bert模型是可以通用的,但是不同数据需要通过预处理来达到满足bert输入的标准才行。
首先,我们创造一个读入自己数据的类,名为MyDataProcessor。其实,这个可以借鉴一下谷歌写好的例子,比如说MrpcProcessor。
首先将DataProcessor类复制粘贴一下,然后命名为MyDataProcessor,别忘了继承一下DataProcessor。
接下来我们以get_train_examples为例来简单介绍一下如何读入自己的数据。
第一步我们需要读取文件进来,这里需要注意的是中文要额外加一个utf-8编码。

读取好之后,这里模仿创建train_data为空列表,索引值为0。
代码主体跟其他的差不多,有区别的是我们这里并没有用DataProcessor的_read_tsv方法,所以文件分割部分我们得自己写。同时因为中文每行结束会有换行符("\n"),需要换为空白。

至于dev和test数据集处理方式大同小异,只需要将名字换一下,这里不多赘述,这里放了处理训练集的完整函数。
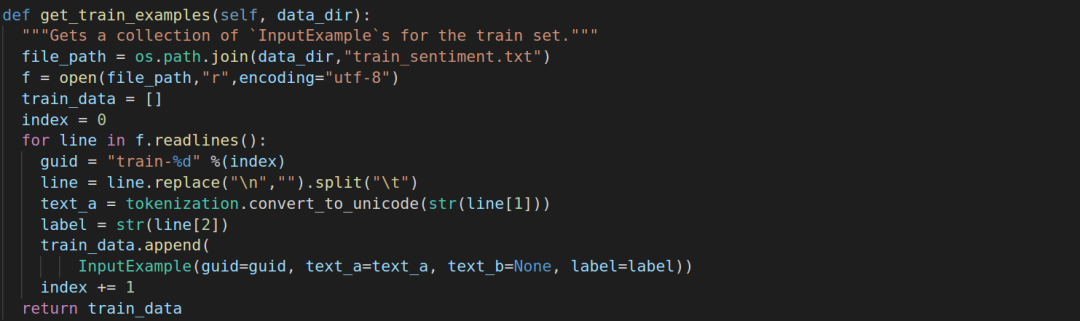
然后get_labels方法,里面写具体的labels,这里是0,1,2,那么就是0,1,2,注意不要忘了带上英文引号就行。最重要的是去main(_)方法下面添加自己定义的数据处理类别

模型去bert官方下载中文的预训练模型,其他的对着改改就好,相信看过我的文本分类(https://github.com/sherlcok314159/ML/blob/main/nlp/tasks/text.md)的剩下的都不需要多说。跑出来的结果如下,我用的是Tesla K80,白嫖Google Colab的,用时1h17min47s。

往期精彩回顾
本站qq群851320808,加入微信群请扫码: