
毕业设计:微博语料中文情感分析

向AI转型的程序员都关注了这个号???
人工智能大数据与深度学习 公众号:datayx
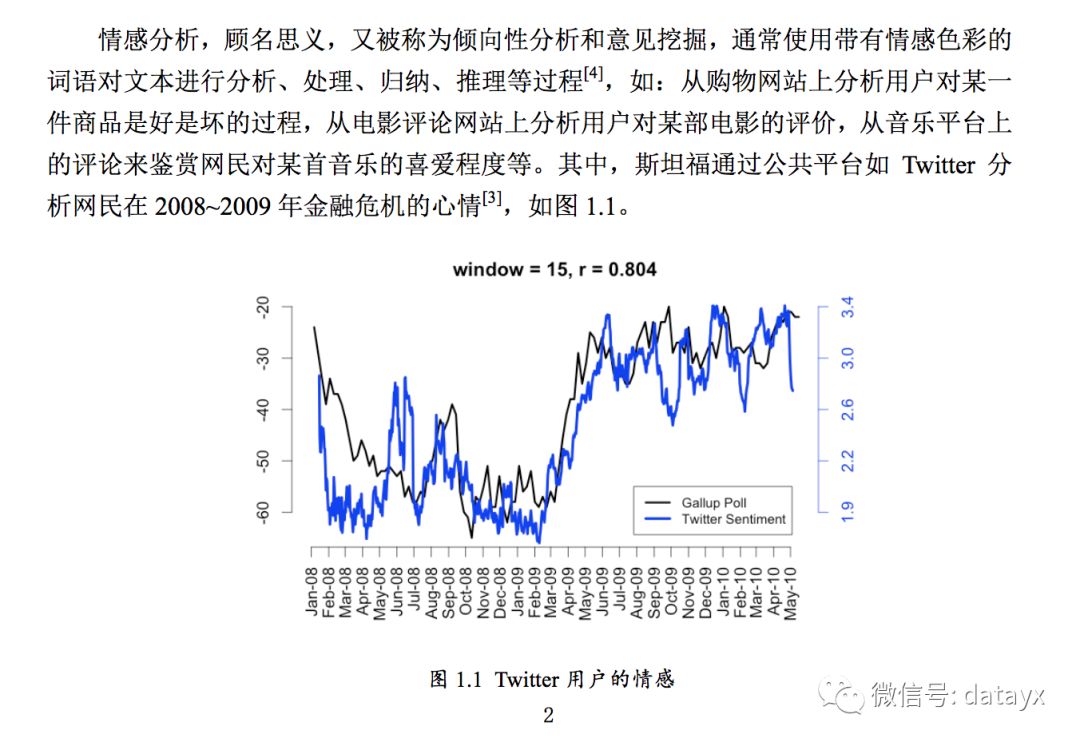
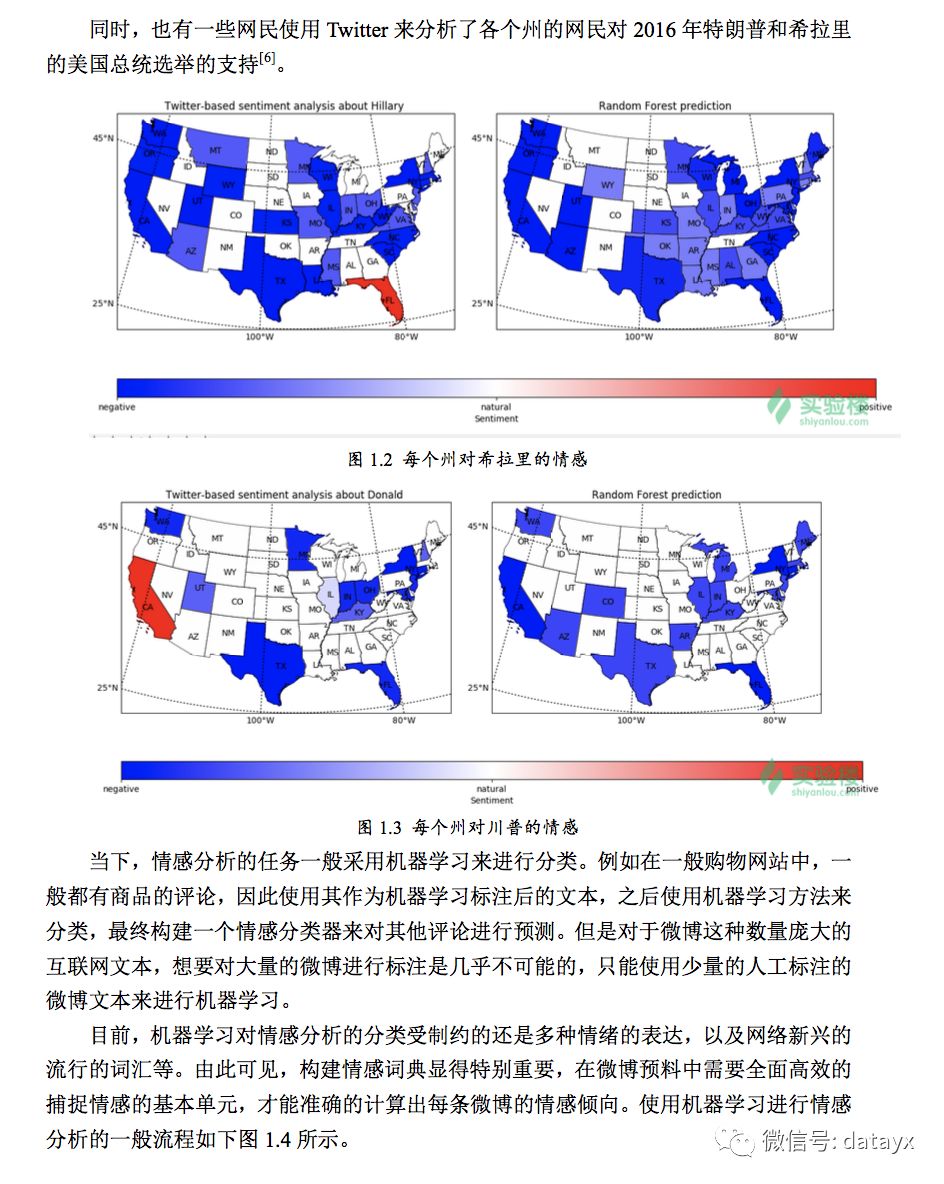
微博的强大影响力已经深深的吸引了更多的人加入。而对微博的情感分析,不仅可以获取网民的此时的心情,对某个事件或事物的看法,还可以获取其潜在的商业价值,还能对社会的稳定做出一定的贡献。
情感分析(Sentimentanalysis),也称意见挖掘(OpinionMining),主要是对带有感情色彩的主观性文本进行分析、处理、归纳然后进行推理的过程,例如对产品,话题,政策的意见[2]。利用这些分析的结果,消费者可以深入了解商品的实用性,从而优化购买的决策,同时,生产者和经销商可以改善自己的服务,从而赢得竞争的优势。随着信息时代的到来,越来越多的公司开始组建数据分析团队对自身公司的数据进行挖掘、分析。比如某服装公司想调查自己制作的服装的受喜爱程度,就可以从服装的评论入手,挖据文本内容,判断留下评论的用户对服装的喜好态度,积极的、消极的或者是中性的评价。
情感分析作为Web挖掘中新兴的一个领域,对其不同角度的研究也越来越多,比如识别商品评论的信息、判断客户的褒贬态度等。姚天昉[3]等人对情感分析的研究现状做了如下总结:
①首先,介绍情感分析的定义和研究的目的;
②从主题的识别、意见持有者的识别、情感描述的选择和情感的分析四个方面进行评述,并介绍了一些成型的系统;
③讨论中文情感分析的研究现状。而本文将要从微博的符号、词语等粒度上,用情感分析的方法对微博文本进行分类。
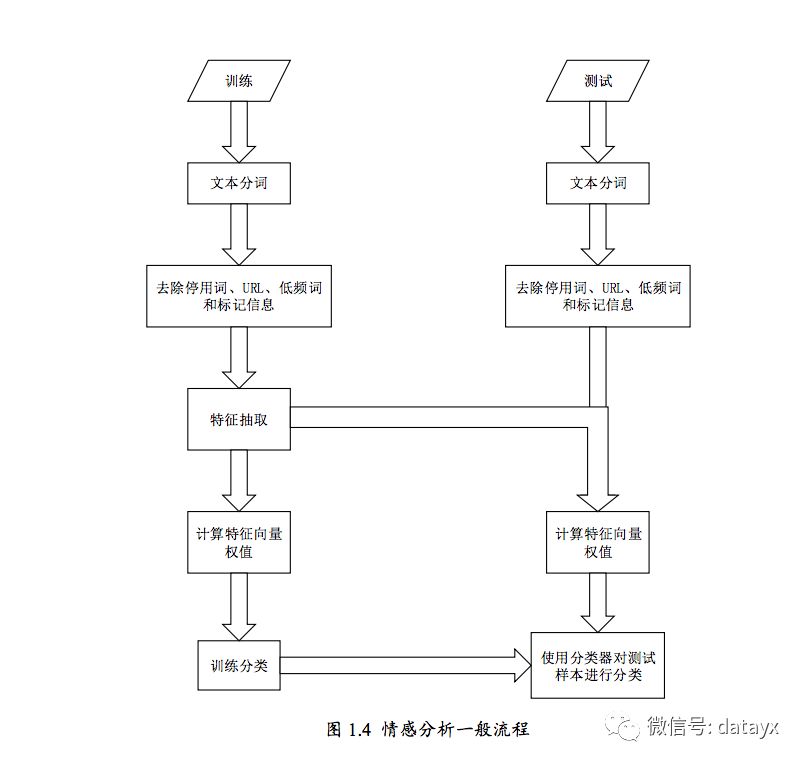
虽然研究者在文本挖掘展开了越来越多的研究,但是对各个领域的深入挖掘依然处在探索阶段。而微博,作为一个越来越吸引用户的社交平台,涉及的内容十分广泛,如娱乐、影视、体育等,不同内容针对不同的领域都有着不可忽视的影响。本文主要结合文本情感分析领域的研究结果以及现有的微博情感分析方法,将对微博的情感分析分为四大类:文本预处理、SVM过滤无关信息、进行情感分类、加强分类算法。
代码获取方式
关注微信公众号 datayx 然后回复 微博 即可获取。
AI项目体验地址 https://loveai.tech
项目流程
一、 使用微博应用获取微博文本
二、 SVM初步分类
三、 利用贝叶斯定理进行情感分析
四、 利用AdaBoost加强分类器
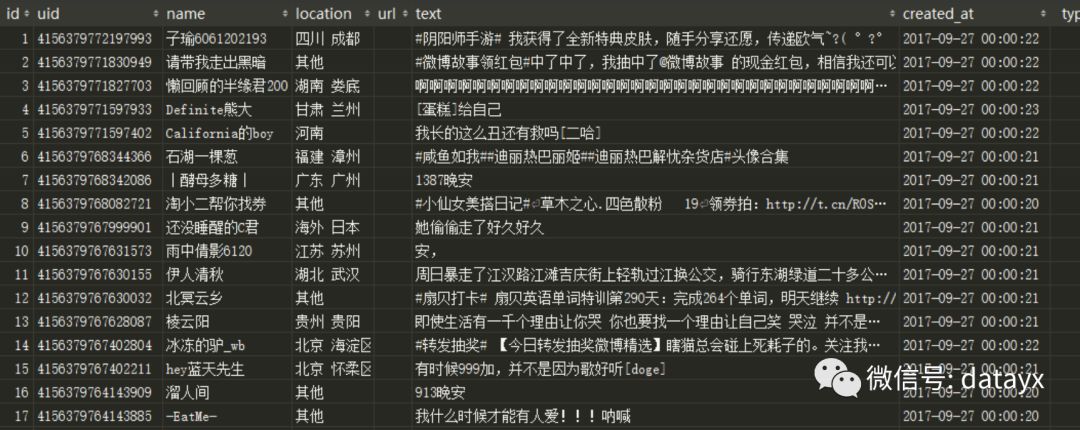
一、获取微博文本
二、SVM初步分类
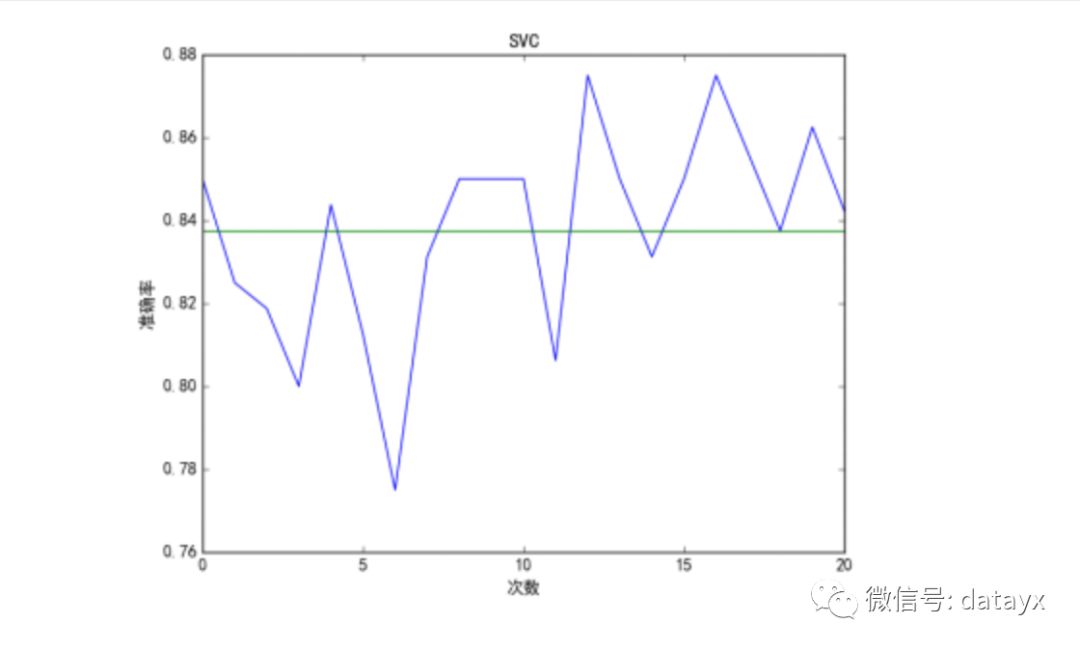
我们使用 python scikitlearn 中的 LinearSVC 进行训练和预测,然后进行训练和预
测,对实验中进行二十次迭代,得出结果绘制成图表如图
三、使用朴素贝叶斯分类
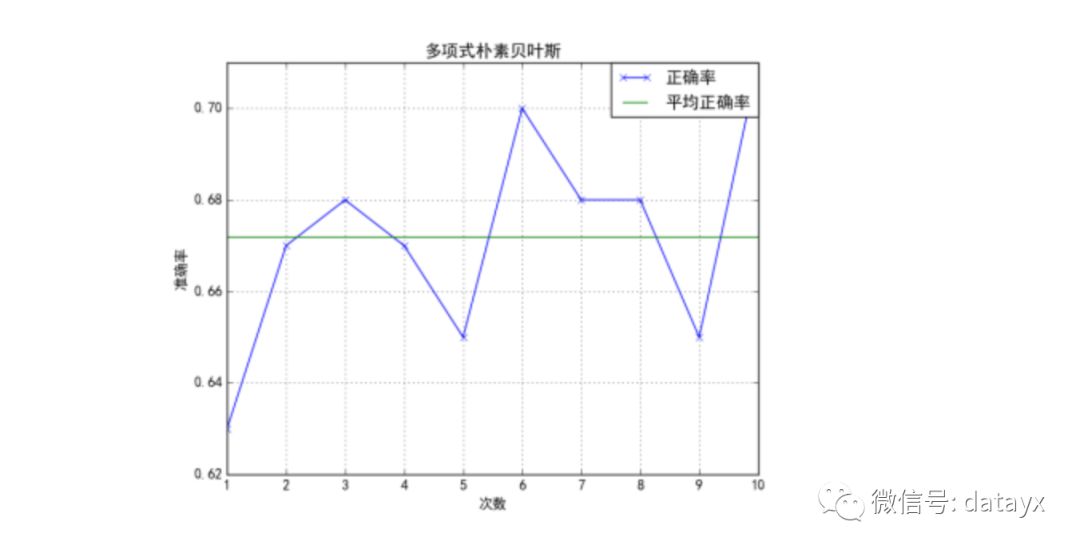
本实验从训练集中随机选取100条用来测试,一共进行了十次实验,统计后将其正确率绘制成曲线如图
四、AdaBoost
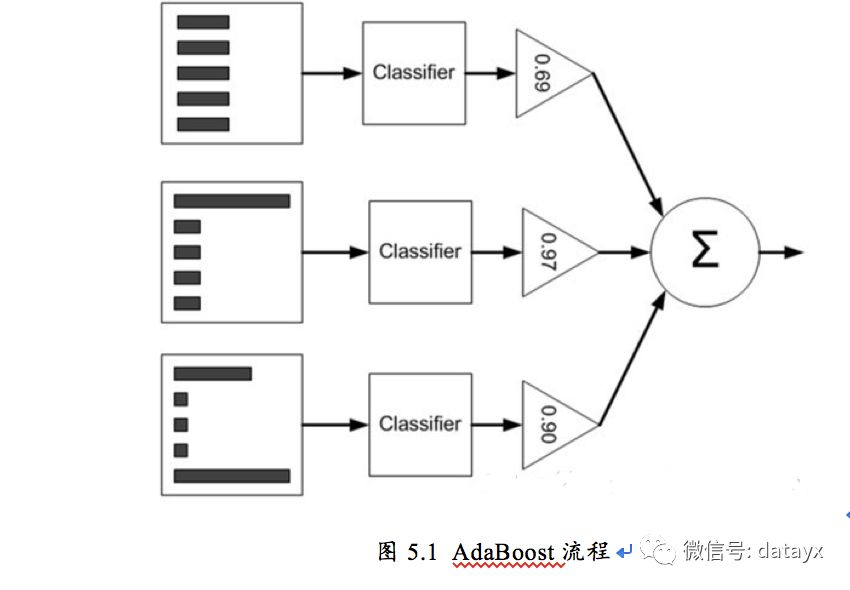
Adaboost是一种迭代的算法,会对同一个训练集使用不同的分类器训练,之后,再把这些分类器集合起来,构建一个最终的最强的分类器。其算法本身是通过改变一个权重D的分布来实现的,该权重D初始化一致,然后改变之后交给下一次分类器。使用Adaboost分类器能够过滤掉一些不必要的训练数据特征,然后放在关键的训练数据上面。AdaBoost分类流程图如图
二分类AdaBoost
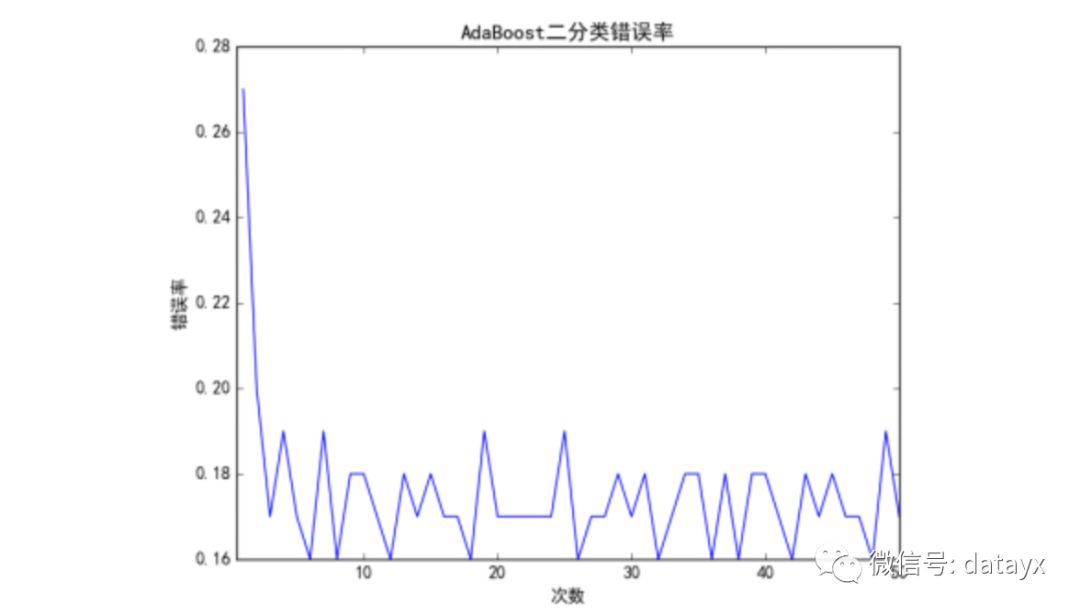
实验将训练集进行两类标注,分为积极和消极,经过文本预处理,然后采用朴素贝叶斯对训练集进行训练,其中使用AdaBoost对分类器进行加强。对于二分类,该算法的伪代码如下图5.8所示。由图中可以看出,经过50次迭代之后,AdaBoost有效的提升了朴素贝叶斯的分类准确性,由初始的27%变成了16%。
多分类AdaBoost
对于多分类的算法,AdaBoost的处理有多种方式,其中,以SAMME和SAMME.R效率较好。本文中将使用pythonsklearn库中的MultinomialNB和AdaBoost进行实验,sklearn优秀的实现了SAMME和SAMME.R算法,更与MultinomialNB能够完美无缝的结合。
(1) SAMME算法
其调用方式如下:
ada_discrete = AdaBoostClassifier(
base_estimator=multi,
learning_rate=learning_rate,
n_estimators=n_estimators,
algorithm="SAMME")
本实验中,我们首先使用AdaBoost来对训练集进行自个训练(即对自己测试),之后,再用训练结果模型来对测试集进行预测。最后,我们将错误率的结果绘制成图如5.11所示。
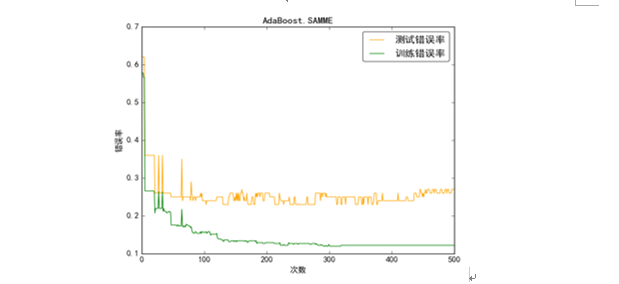
由图中可以看出,SAMEE算法波动比较大,主要是由于如果分类错误,该分类算法会偏向于错分类别中概率较大的那一类,最终,分类器的正确率无法有效的提升。
(2)SAMME.R算法
SAMME.R算法的伪代码和SAMME中的类似,只是将AdaBoostClassifier中的algorithm换成"SAMME.R"。
ada_real = AdaBoostClassifier(
base_estimator=multi,
learning_rate=learning_rate,
n_estimators=n_estimators,
algorithm="SAMME.R")
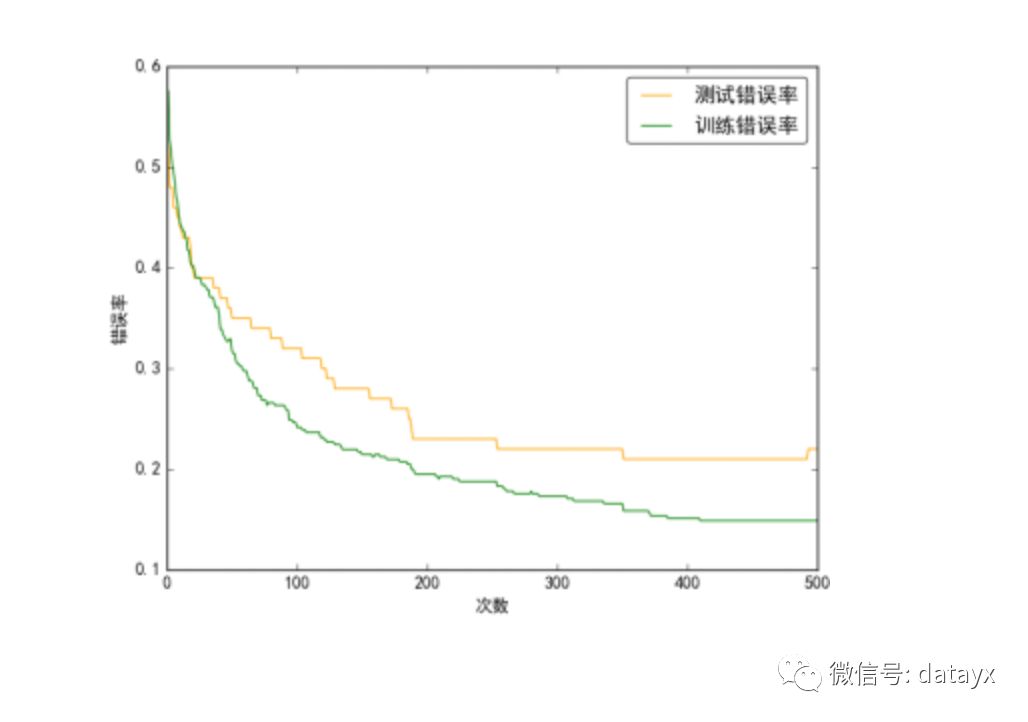
由图中可以看出,SAMME.R算法比较平滑,波动较小。AdaBoost.SAMME.R是对AdaBoost的扩展和提升,其输出结果是一个实数值(也称置信度),将朴素贝叶斯作为其弱分类器之后,能够有效的提高实验的准确度。
AdaBoost算法的研究大部分都集中在分类问题,其中,人脸检测更是优于其他算法,其应用系列解决了多种分类的问题如:二分问题、多类单标签问题、多类多标签问题等。使用该算法仅仅需要增加新分类器,方式简单,同时能够让分类错误率的上届随着训练次数的增加而稳定下降,几乎不会产生过拟合的问题。本文将朴素贝叶斯作为AdaBoost的基分类器,处理多类问题,对微博的分类进行了加强,不仅防止了过拟合问题,还能降低了朴素贝叶斯的错误率。
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码