日期 : 2021年11月06日
正文共 :1381字
近几个月以来,学术圈不端行为屡被爆出,先是港科大硕士 ICCV 论文涉嫌抄袭,后有北理工硕士生「一字不差」抄袭顶会投稿。
更离谱的来了!
近日,B 站一位博主发视频称复旦大学重点实验室疑似抄袭美国教授的论文,并列出了一系列抄袭证据。
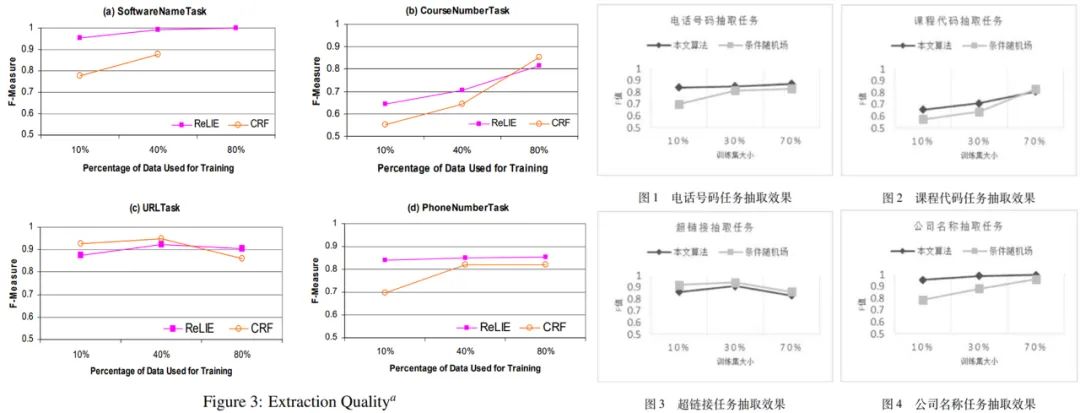
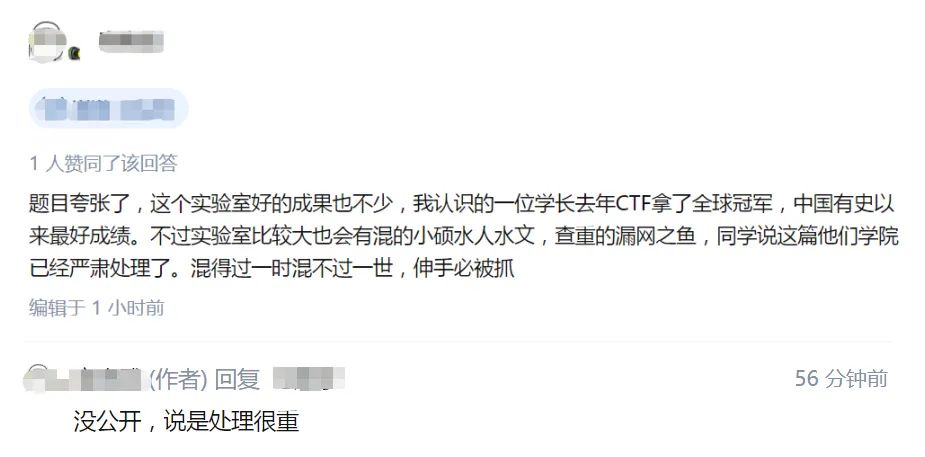
涉嫌抄袭的论文是 2017 年发表在期刊《计算机应用与软件》上的《基于正则表达式构建学习的网页信息抽取方法》,两位作者来自复旦大学计算机科学技术学院智能信息处理重点实验室。值得注意的是,这篇论文没有挂导师名字。
论文地址:http://www.shcas.net/jsjyup/pdf/2017/2/%E5%9F%BA%E4%BA%8E%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%9E%84%E5%BB%BA%E5%AD%A6%E4%B9%A0%E7%9A%84%E7%BD%91%E9%A1%B5%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96%E6%96%B9%E6%B3%95.pdf上述论文疑似抄袭了 2008 年发表的一篇论文《Regular Expression Learning for Information Extraction》,几位作者来自 IBM Almaden 研究中心,并由密歇根大学安娜堡分校电气工程与计算机科学系教授 H. V. Jagadish 提供支持。论文地址 https://aclanthology.org/D08-1003.pdf根据爆料博主的说法,「从摘要到正文内容,几乎都是翻译之后再成文的。」首先,论文摘要(Abstract)和引言(Introduction)部分存在相似的地方,如下为两篇论文的部分摘要截图:在下图两篇论文的引言部分,可以看到,列举的示例存在高度重合,如邮箱地址、信用卡号码以及基因和蛋白质名称等。其次,在两篇论文的第二章节《2 The Regex Learning Problem 》和《2 问题描述》,行文的逻辑、涉及的部分定义和公式更能看出抄袭痕迹。如下为部分截图:此外,两篇论文中各自提出的算法「ReLIE 搜索算法」和「正则表达式构建学习算法」也高度相似:最后,实验结果也疑似抄袭,下图左为英文原文在 SoftwareName、CourseNumber、 URL 和 PhoneNumber 四个任务上的抽取结果,图右为中文论文在电话号码、课程代码、超链接任务和公司名称任务上的抽取结果,不难看出部分任务上的变化趋势有重合的地方:值得注意的是,涉嫌抄袭的论文是 2017 年发表的,被抄袭的论文是 2008 年发表的。这意味着 2017 年这篇论文已几乎没有学术价值,只是给论文量加了一笔。此次疑似抄袭事件被曝出之后,在知乎引起热议,有网友随即质疑复旦大学重点实验室的学术严谨水平。网友调查发现两位作者是复旦大学已毕业的硕士生,论文作者中没有学校导师。并且论文发表时间是在 2017 年,当时作者已经毕业。但也有网友提到:疑似抄袭的论文提交时间是 2016 年 1 月,当时一作尚未毕业。一时之间,大家的关注点转移到了实验室的科研水平上。有网友为复旦大学计算机科学技术学院智能信息处理重点实验室正名:实验室的好成果很多,并称这篇论文已被学院严肃处理。这篇论文再次给学术圈敲响了警钟。对于研究者来说,实事求是基本的要求;对于读者而言,保有质疑精神也是推动学术研究良好发展的重要力量。https://www.zhihu.com/question/493606496https://www.bilibili.com/video/BV1tR4y1J7iR?share_medium=android&share_plat=android&share_session_id=e3161655-39b9-4856-8f32-21b002db95cb&share_source=COPY&share_tag=s_i×tamp=1634754137&unique_k=6xCoig (https://www.bilibili.com/video/BV1tR4y1J7iR?share_medium=android&share_plat=android&share_session_id=e3161655-39b9-4856-8f32-21b002db95cb&share_source=COPY&share_tag=s_i×tamp=1634754137&unique_k=6xCoig)