
YOLO in the Dark 窥见黑夜 | 黑夜里的目标检测
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达

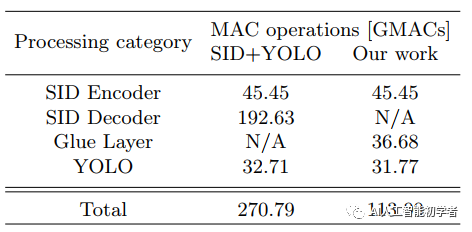
对于处理新的视觉任务,则需要额外的数据集,这需要花费大量精力。本文提出了一种域自适应的新方法,该方法可以比创建附加数据集更轻松地合并多个模型。该方法使用glue层和生成模型合并了不同领域中的预训练模型,该模型提供了潜在特征来训练glue层而无需其他数据集。我们还提出了从预先训练的模型中通过知识蒸馏创建的生成模型。它还允许重用数据集来创建潜在特征以训练胶合层。我们将此方法应用于弱光条件下的目标检测。“Dark YOLO”包含两个模型,“学习如何在黑暗中看”和
YOLO。与其它方法相比,“Dark YOLO”花费更少的计算资源。
1、简介
在光线弱的情况下进行视觉任务是一个比较困难的课题。Short-Exposure图像没有足够的特征进行视觉处理,而图像的亮度增强会引起噪声进而影响视觉任务。相比之下,Long-Exposure图像也含有噪声,由于运动模糊而影响视觉任务。
前人一些工作可以总结为以下三点:
1、通过制作附加数据集(比如说the See-in-the-Dark dataset)的方式来缓解这个问题,让数据集中尽可能的包含多种Exposure情况下的图像,但是带来的弊端就是,需要多余的人力来解决,同时不是一个 end to end的模型。2、通过知识蒸馏的方式解决这个问题,相对于构造附加数据集的方式而言是个更好的处理方式; 3、使用无监督学习的方式来学习 Domain Gap,进而学到Domain Adaption特性,进而提升在不同Domain之间的适应性,方便Domain的迁移。
2、本文方法
本文主要还是基于前面提到的知识蒸馏的方法进行的设计,提出了YOLO in the Dark模型。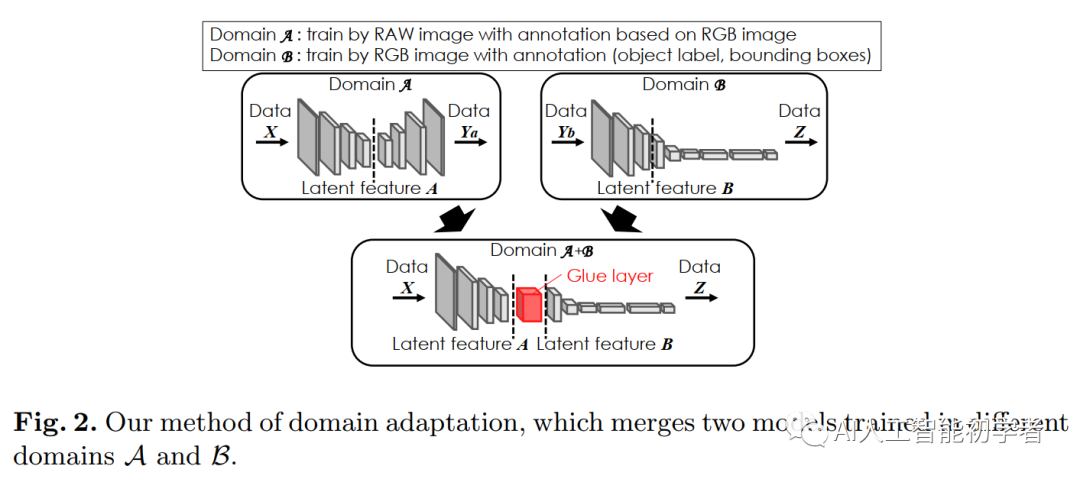
这里model A从一个RAW图片中预测一个RGB图片,然后model B从RGB图像中预测目标的位置和类别,完成model A和B的训练后,以潜在特征A和B的边界提取模型fragments。new model由model A和B的以潜在特征A和B的边界提取模型fragments通过一层粘合层(Glue Layer)组合而成。
Glue Layer层可以将模型fragments中的latent feature A转换为latent feature B。SID模型在低光图像上有比较好的效果,因此对model A使用SID模型。还使用目标检测模型YOLO对于model B。
2.1、Domain Adaption的生成模型
通过图2也可以看出来训练Gule Layer需要Domain A+B的数据,然而制作一个这样的数据集需要很大的功夫,所以作者在这里选择了知识蒸馏的方法来定义一个生成模型进而来训练Gule Layer
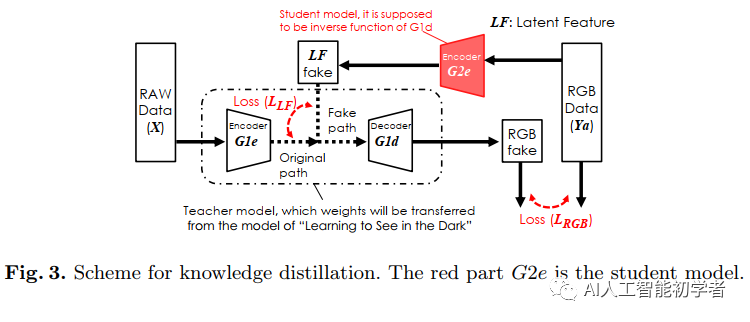
图3 解释了知识蒸馏的方案,其中的生成模型输出的latent feature A来自于,SID模型是编解码的结构,因此生成模型可以作为解码器的映射函数;同时作为Teacher Model同时使用来自SID数据集和模型的数据样本对来训练Student Model。
使用RGB数据和通过构造的伪RGB数据训练模型的损失函数loss为:
同时在训练的过程中还定义了Latent Feature(LF) 和LF G1e:
这两个损失函数帮助定义G2e为G1d的逆函数:
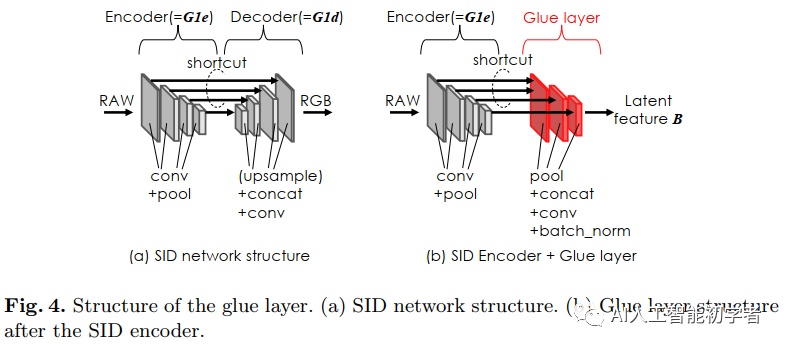
(a)是SID网络结构(基于UNet)。SID编码器具有与4层特征相对应的池化scales。
(b)为Gule Laye结构。由pool、cat、Conv和BN组成。pool和cat函数有助于收集latent feature。Conv和BN帮助Domain B转换一个新的latent feature。

图5显示了使用SID编码器的潜在特性重新构建的RGB图像。(a)展示了使用所有特性重构的图像。这些图像的峰值信噪比(PSNR)为31.81,具有结构特征相对于原始图像的相似性(SSIM)为0.752。(b)、(c)和(d)为使用较少特征重建的图像,去除了高空间频率信息。这些图象的质量比图象(a)的质量差。但是为了检测物体,必须识别出物体的具体形状,因此文章决定使用所有的Latent Feature用于Gule Layer。
 图 6 可以看出SID模型生成的RGB图像和组合的RGB图像时非常相近的。
图 6 可以看出SID模型生成的RGB图像和组合的RGB图像时非常相近的。
同时为了进一步的优化G2e模型,文章还使用YOLO的分类输出特征向量来优化G2e,以提升其转换Domain A->B的性能,具体就是使用余弦相似度来计算向量之间的损失,最后通过反向传播进行更新迭代和优化:
2.2、Training environment
图7(a)显示了环境的完整视图,其中点边界显示了用于训练新模型的部分,其中Gule Layer是模型训练的目标;而训练该模块使用的RGB图像数据即是G2e编码器通过知识蒸馏的方法得到的。整体的训练环境还是基于原生的YOLO模型,使用和G2e编码器一样的RGB数据,这里使用的是COCO数据集进行训练。
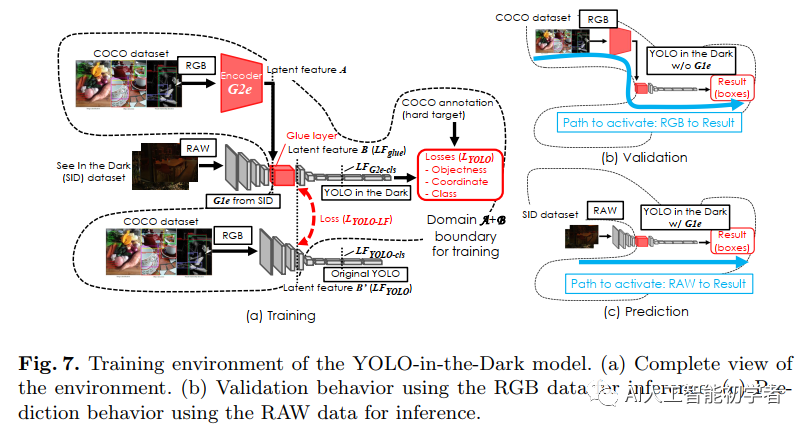
在训练期间Gule Layer层会被多个损失函数同时约束,第一个损失函数就是原始YOLO的损失函数;其他的损失函数都是基于原始YOLO模型的Latent Feature A与YOLO in Dark中的Latent Feature B之间的差异得到:
总的损失函数为:
其中即为原生YOLO的损失函数。
图7(b)显示了验证期间的数据流。验证使用与训练相同的路径,后者使用RGB数据并评估来自数据集的足够样本,以确认Gule Layer的行为是正确的。
图7(c)显示了预测期间的数据流。预测使用另一条路径,使用通过编码器G1e从SID模型传输的原始数据。这一阶段是为了评估所提出的黑暗中模型,该模型将改进短曝光原始图像中的目标检测。
3、实验结果
图8显示了SID数据集的对象检测结果。图8(a)是原始YOLO模型使用亮度增强的RGB图像得到的检测结果。RGB图像的亮度增强使得原始YOLO模型更容易检测到目标。因此原始的YOLO模型可以很好地检测图像中的对象。但是,该模型无法检测到图像中的目标。这是因为亮度增强增加了噪音,影响了模型的推断。而本文提出的方法可以直接检测RAW图像中的目标。检测结果如图b1和b2所示。图像c1和c2是标签,标签是通过原始YOLO模型使用SID ground truth(长曝光)图像检测得到。在图像b1中,提出的模型表现得和原始的YOLO模型(图像a1)一样好。此外,所提出的模型可以检测图像b2中的目标。
References
[1] YOLO in the Dark - Domain Adaptation Method for Merging Multiple Models
下载1:动手学深度学习
在「AI算法与图像处理」公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
