
目标检测 | 盘点目标检测中的特征融合技巧(根据YOLO v4总结)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在深度学习的很多工作中(例如目标检测、图像分割),融合不同尺度的特征是提高性能的一个重要手段。低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,其语义性更低,噪声更多。高层特征具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。如何将两者高效融合,取其长处,弃之糟泊,是改善分割模型的关键。
很多工作通过融合多层来提升检测和分割的性能,按照融合与预测的先后顺序,分类为早融合(Early fusion)和晚融合(Late fusion)。
早融合(Early fusion): 先融合多层的特征,然后在融合后的特征上训练预测器(只在完全融合之后,才统一进行检测)。这类方法也被称为skip connection,即采用concat、add操作。这一思路的代表是Inside-Outside Net(ION)和HyperNet。两个经典的特征融合方法:
(1)concat:系列特征融合,直接将两个特征进行连接。两个输入特征x和y的维数若为p和q,输出特征z的维数为p+q;
(2)add:并行策略,将这两个特征向量组合成复向量,对于输入特征x和y,z = x + iy,其中i是虚数单位。
晚融合(Late fusion):通过结合不同层的检测结果改进检测性能(尚未完成最终的融合之前,在部分融合的层上就开始进行检测,会有多层的检测,最终将多个检测结果进行融合)。这一类研究思路的代表有两种:
(1)feature不融合,多尺度的feture分别进行预测,然后对预测结果进行综合,如Single Shot MultiBox Detector (SSD) , Multi-scale CNN(MS-CNN)
(2)feature进行金字塔融合,融合后进行预测,如Feature Pyramid Network(FPN)等。
接下来,主要对晚融合方法进行归纳总结。
论文地址:
https://arxiv.org/abs/1612.03144
FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
FPN将深层信息上采样,与浅层信息逐元素地相加,从而构建了尺寸不同的特征金字塔结构,性能优越,现已成为目标检测算法的一个标准组件。FPN的结构如下所示。
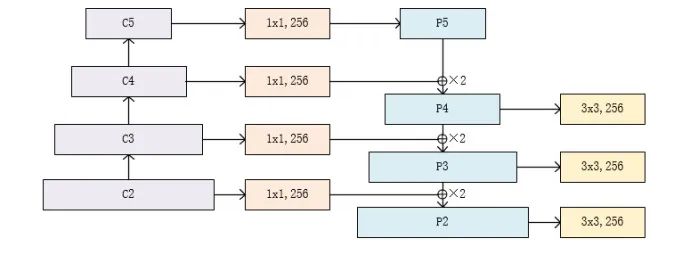
自下而上:最左侧为普通的卷积网络,默认使用ResNet结构,用作提取语义信息。C1代表了ResNet的前几个卷积与池化层,而C2至C5分别为不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。
自上而下:首先对C5进行1×1卷积降低通道数得到P5,然后依次进行上采样得到P4、P3和P2,目的是得到与C4、C3与C2长宽相同的特征,以方便下一步进行逐元素相加。这里采用2倍最邻近上采样,即直接对临近元素进行复制,而非线性插值。
横向连接(Lateral Connection):目的是为了将上采样后的高语义特征与浅层的定位细节特征进行融合。高语义特征经过上采样后,其长宽与对应的浅层特征相同,而通道数固定为256,因此需要对底层特征C2至C4进行11卷积使得其通道数变为256,然后两者进行逐元素相加得到P4、P3与P2。由于C1的特征图尺寸较大且语义信息不足,因此没有把C1放到横向连接中。
卷积融合:在得到相加后的特征后,利用3×3卷积对生成的P2至P4再进行融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
FPN对于不同大小的RoI,使用不同的特征图,大尺度的RoI在深层的特征图上进行提取,如P5,小尺度的RoI在浅层的特征图上进行提取,如P2。FPN的代码实现如下:
import torch.nn as nnimport torch.nn.functional as Fimport mathclass Bottleneck(nn.Module):expansion = 4def __init__(self, in_planes, planes, stride=1, downsample=None):super(Bottleneck, self).__init__()self.bottleneck = nn.Sequential(nn.Conv2d(in_planes, planes, 1, bias=False),nn.BatchNorm2d(planes),nn.ReLU(inplace=True),nn.Conv2d(planes, planes, 3, stride, 1, bias=False),nn.BatchNorm2d(planes),nn.ReLU(inplace=True),nn.Conv2d(planes, self.expansion * planes, 1, bias=False),nn.BatchNorm2d(self.expansion * planes),)self.relu = nn.ReLU(inplace=True)self.downsample = downsampledef forward(self, x):identity = xout = self.bottleneck(x)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass FPN(nn.Module):def __init__(self, layers):super(FPN, self).__init__()self.inplanes = 64self.conv1 = nn.Conv2d(3, 64, 7, 2, 3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(3, 2, 1)self.layer1 = self._make_layer(64, layers[0])self.layer2 = self._make_layer(128, layers[1], 2)self.layer3 = self._make_layer(256, layers[2], 2)self.layer4 = self._make_layer(512, layers[3], 2)self.toplayer = nn.Conv2d(2048, 256, 1, 1, 0)self.smooth1 = nn.Conv2d(256, 256, 3, 1, 1)self.smooth2 = nn.Conv2d(256, 256, 3, 1, 1)self.smooth3 = nn.Conv2d(256, 256, 3, 1, 1)self.latlayer1 = nn.Conv2d(1024, 256, 1, 1, 0)self.latlayer2 = nn.Conv2d( 512, 256, 1, 1, 0)self.latlayer3 = nn.Conv2d( 256, 256, 1, 1, 0)def _make_layer(self, planes, blocks, stride=1):downsample = Noneif stride != 1 or self.inplanes != Bottleneck.expansion * planes:downsample = nn.Sequential(nn.Conv2d(self.inplanes, Bottleneck.expansion * planes, 1, stride, bias=False),nn.BatchNorm2d(Bottleneck.expansion * planes))layers = []layers.append(Bottleneck(self.inplanes, planes, stride, downsample))self.inplanes = planes * Bottleneck.expansionfor i in range(1, blocks):layers.append(Bottleneck(self.inplanes, planes))return nn.Sequential(*layers)def _upsample_add(self, x, y):_,_,H,W = y.shapereturn F.upsample(x, size=(H,W), mode='bilinear') + ydef forward(self, x):c1 = self.maxpool(self.relu(self.bn1(self.conv1(x))))c2 = self.layer1(c1)c3 = self.layer2(c2)c4 = self.layer3(c3)c5 = self.layer4(c4)p5 = self.toplayer(c5)p4 = self._upsample_add(p5, self.latlayer1(c4))p3 = self._upsample_add(p4, self.latlayer2(c3))p2 = self._upsample_add(p3, self.latlayer3(c2))p4 = self.smooth1(p4)p3 = self.smooth2(p3)p2 = self.smooth3(p2)return p2, p3, p4, p5
论文地址:
https://arxiv.org/abs/1803.01534
代码地址:
https://github.com/ShuLiu1993/PANet
1、缩短信息路径和用低层级的准确定位信息增强特征金字塔,创建了自下而上的路径增强
2、为了恢复每个建议区域和所有特征层级之间被破坏的信息,作者开发了适应性特征池化(adaptive feature pooling)技术,可以将所有特征层级中的特征整合到每个建议区域中,避免了任意分配的结果。
3、全连接融合层:使用一个小型fc层用于补充mask预测
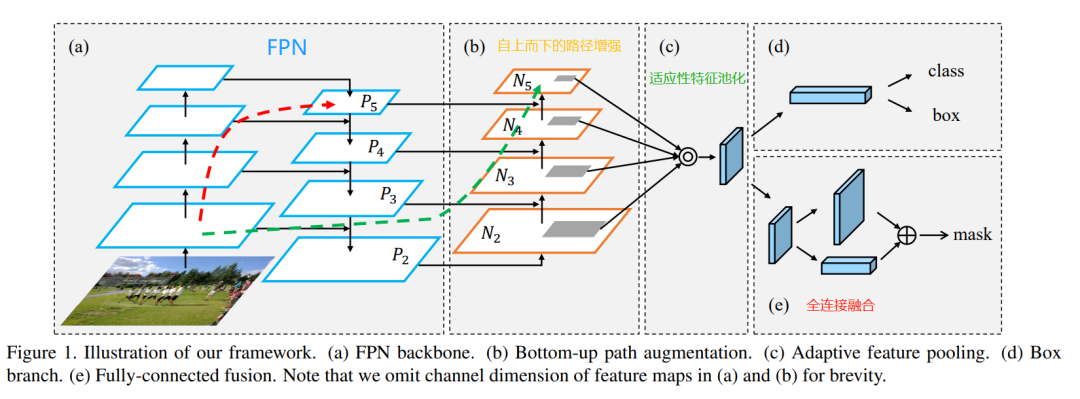
自下而上的路径增强
Bottom-up Path Augemtation的提出主要是考虑到网络的浅层特征对于实例分割非常重要,不难想到浅层特征中包含大量边缘形状等特征,这对实例分割这种像素级别的分类任务是起到至关重要的作用的。因此,为了保留更多的浅层特征,论文引入了Bottom-up Path Augemtation。
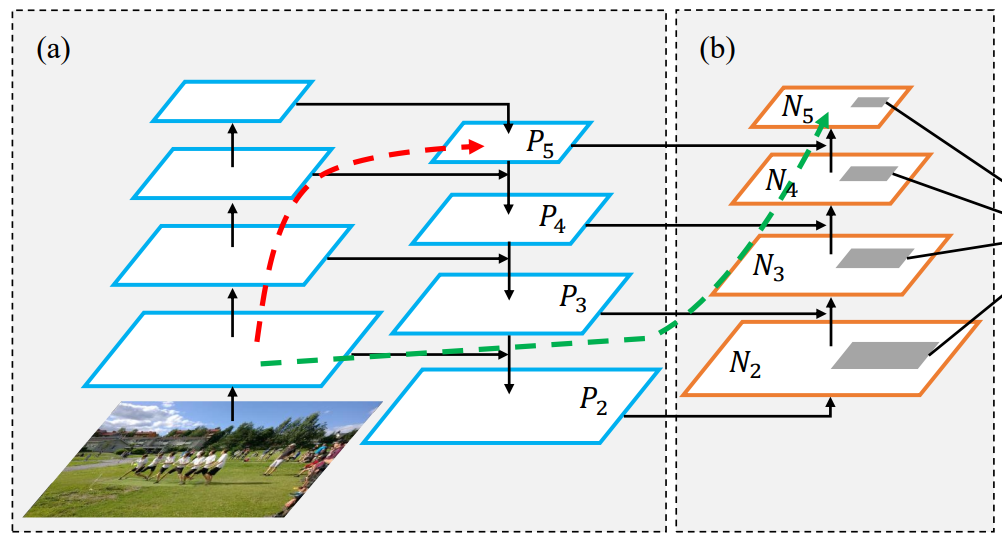
红色的箭头表示在FPN中,因为要走自底向上的过程,浅层的特征传递到顶层需要经过几十个甚至上百个网络层,当然这取决于BackBone网络用的什么,因此经过这么多层传递之后,浅层的特征信息丢失就会比较严重。
绿色的箭头表作者添加了一个Bottom-up Path Augemtation结构,这个结构本身不到10层,这样浅层特征经过原始FPN中的横向连接到P2然后再从P2沿着Bottom-up Path Augemtation传递到顶层,经过的层数不到10层,能较好的保存浅层特征信息。注意,这里的N2和P2表示同一个特征图。 但N3,N4,N5和P3,P4,P5不一样,实际上N3,N4,N5是P3,P4,P5融合后的结果。
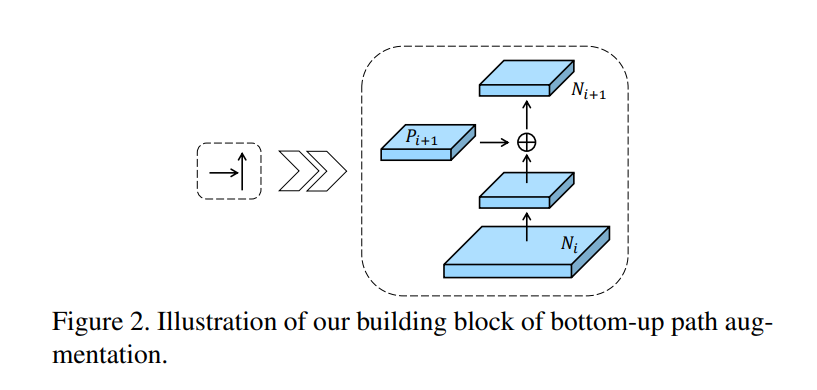
Bottom-up Path Augemtation的详细结构如下图所示,经过一个尺寸为,步长为的卷积之后,特征图尺寸减小为原来的一半然后和这个特征图做add操作,得到的结果再经过一个卷积核尺寸为,的卷积层得到。
适应性特征池化(adaptive feature pooling)
论文指出,在Faster-RCNN系列的标检测或分割算法中,RPN网络得到的ROI需要经过ROI Pooling或ROI Align提取ROI特征,这一步操作中每个ROI所基于的特征都是单层特征,FPN同样也是基于单层特征,因为检测头是分别接在每个尺度上的。
本文提出的Adaptive Feature Pooling则是将单层特征换成多层特征,即每个ROI需要和多层特征(论文中是4层)做ROI Align的操作,然后将得到的不同层的ROI特征融合在一起,这样每个ROI特征就融合了多层特征。
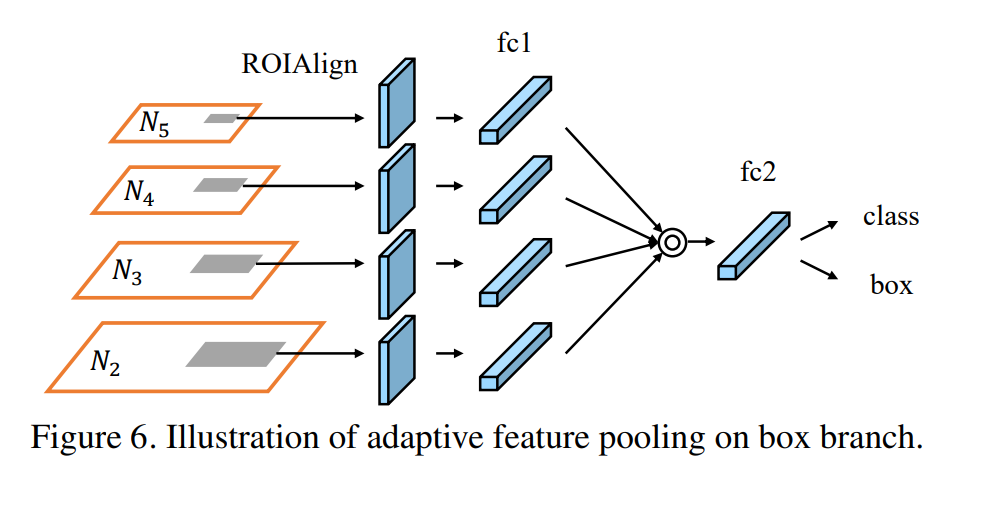
RPN网络获得的每个ROI都要分别和特征层做ROI Align操作,这样个ROI就提取到4个不同的特征图,然后将4个不同的特征图融合在一起就得到最终的特征,后续的分类和回归都是基于此最终的特征进行。
全连接融合层(Fully-Connected Fusion)
全连接融合层对原有的分割支路(FCN)引入一个前景二分类的全连接支路,通过融合这两条支路的输出得到更加精确的分割结果。这个模块的具体实现如图所示。
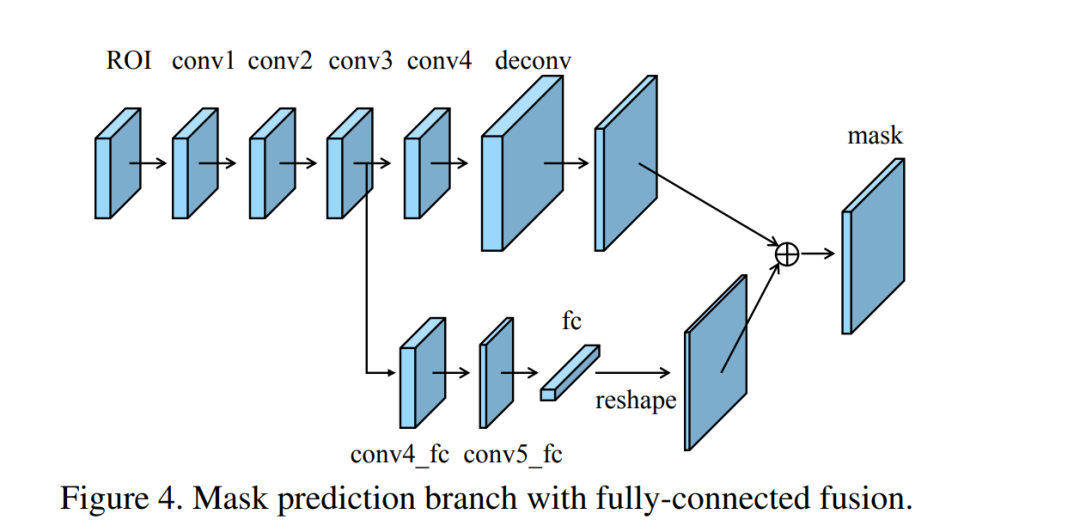
从图中可以看到这个结构主要是在原始的Mask支路(即带deconv那条支路)的基础上增加了下面那个支路做融合。增加的这个支路包含个的卷积层,然后接一个全连接层,再经过reshape操作得到维度和上面支路相同的前背景Mask,即是说下面这个支路做的就是前景和背景的二分类,输出维度类似于文中说的。而上面的支路输出维度类似,其中代表数据集目标类别数。最终,这两条支路的输出Mask做融合以获得更加精细的最终结果。
MLFPN来自《M2det: A single-shot object detector based on multi-level feature pyramid network》。
论文地址:
https://arxiv.org/abs/1811.04533
代码地址:
https://github.com/qijiezhao/M2Det
之前的特征金字塔目标检测网络共有的两个问题是:
1、原本 backbone 是用于目标分类的网络,导致用于目标检测的语义特征不足;
2、每个用于目标检测的特征层主要或者仅仅是由单级特征层(single-level layers)构成,也就是仅仅包含了单级信息;
这种思想导致一个很严重的问题,对分类子网络来说更深更高的层更容易区分,对定位的回归任务来说使用更低更浅的层比较好。此外,底层特征更适合描述具有简单外观的目标,而高层特征更适合描述具有复杂外观的目标。在实际中,具有相似大小目标实例的外观可能非常不同。例如一个交通灯和一个远距离的人可能具有可以比较的尺寸,但是人的外表更加复杂。因此,金字塔中的每个特征图主要或者仅仅由单层特征构成可能会导致次优的检测性能。
为了更好地解决目标检测中尺度变化带来的问题,M2det提出一种更有效的特征金字塔结构MLFPN, 其大致流程如下图所示:首先,对主干网络提取到的特征进行融合;然后通过TUM和FFM提取更有代表性的Multi-level&Mutli-scale特征;最后通过SFAM融合多级特征,得到多级特征金字塔用于最终阶段的预测。M2Det使用主干网络+MLFPN来提取图像特征,然后采用类似SSD的方式预测密集的包围框和类别得分,通过NMS得到最后的检测结果。
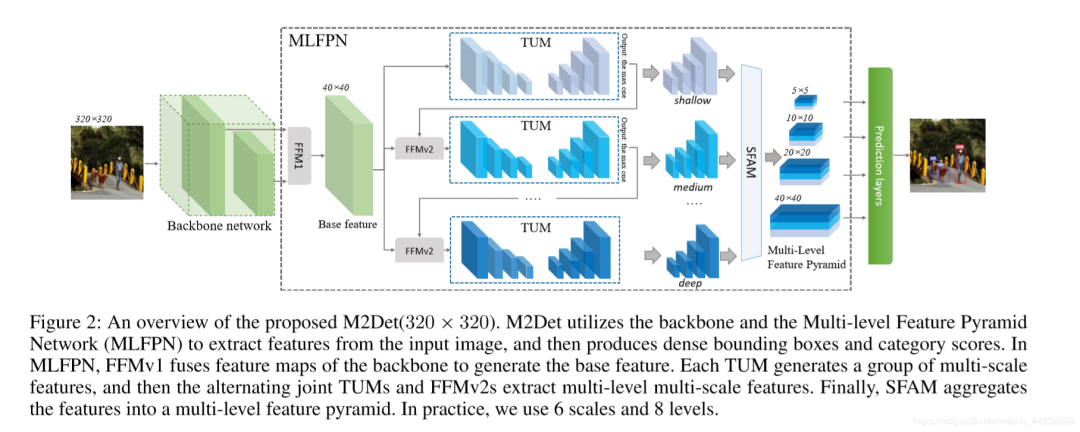
如上图所示,MLFPN主要有3个模块组成:
1)特征融合模块FFM;
2)细化U型模块TUM;
3)尺度特征聚合模块SFAM.
首先, FFMv1对主干网络提取到的浅层和深层特征进行融合,得到base feature;
其次,堆叠多个TUM和FFMv2,每个TUM可以产生多个不同scale的feature map,每个FFMv2融合base feature和上一个TUM的输出,并给到下一个TUM作为输入(更高level)。
最后,SFAM通过scale-wise拼接和channel-wise attention来聚合multi-level&multi-scale的特征。
特征融合模块FFM
FFM用于融合M2Det中不同级别的特征,先通过1x1卷积压缩通道数,再进行拼接。
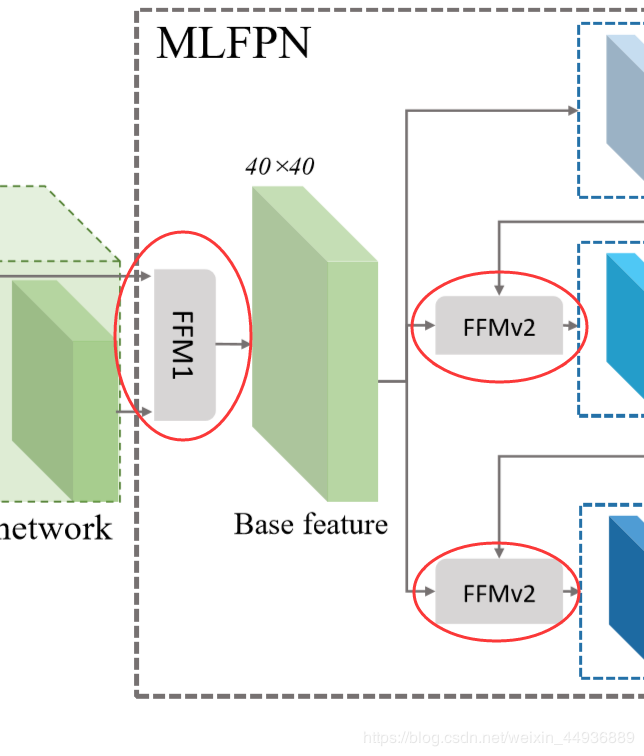
FFM1 用于融合深层和和浅层特征,为 MLFPN 提供基本输入的特征层(Base Feature);由于 M2Det 使用了 VGG 作为 backbone,因此 FFM1 取出了 Conv4_3 和 Conv5_3 作为输入:FFMv1使用两种不同scale的feature map作为输入,所以在拼接操作之前加入了上采样操作来调整大小;
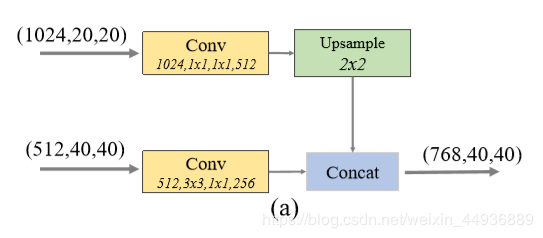
FFMv2用于融合 MLFPN 的基本输入(Base Feature)和上一个 TUM 模块的输出,两个输入的scale相同,所以比较简单。
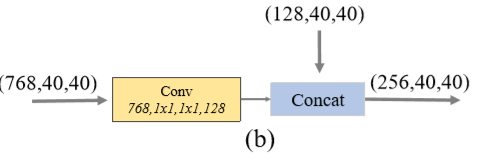
细化U型模块TUM
TUM使用了比FPN和RetinaNet更薄的U型网络。在上采样和元素相加操作之后加上1x1卷积来加强学习能力和保持特征平滑度。TUM中每个解码器的输出共同构成了该TUM的multi-scale输出。每个TUM的输出共同构成了multi-level&multi-scale特征,前面的TUM提供low level feature,后面的TUM提供high level feature。
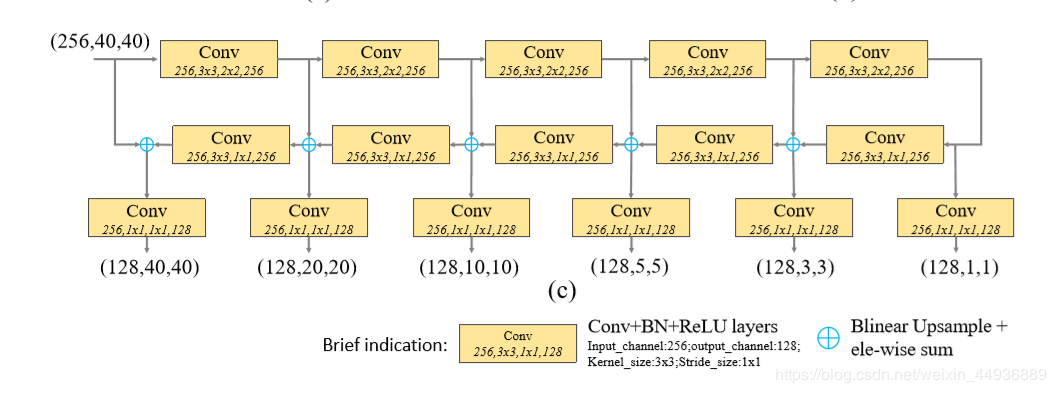
TUM 的编码器(encoder)使用 3×3 大小、步长为 2 的卷积层进行特征提取,特征图不断缩小;解码器(decoder)同过双线性插值的方法将特征图放大回原大小。
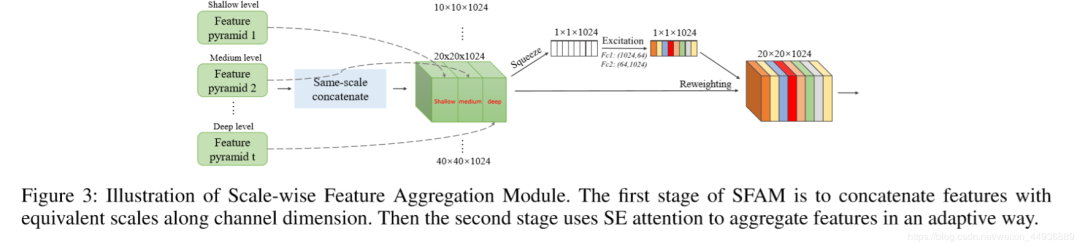
尺度特征聚合模块SFAM
SFAM旨在聚合TUMs产生的多级多尺度特征,以构造一个多级特征金字塔。在first stage,SFAM沿着channel维度将拥有相同scale的feature map进行拼接,这样得到的每个scale的特征都包含了多个level的信息。然后在second stage,借鉴SENet的思想,加入channel-wise attention,以更好地捕捉有用的特征。SFAM的细节如下图所示:
网络配置
M2Det的主干网络采用VGG-16和ResNet-101。
MLFPN的默认配置包含有8个TUM,每个TUM包含5个跨步卷积核5个上采样操作,所以每个TUM的输出包含了6个不同scale的特征。
在检测阶段,为6组金字塔特征每组后面添加两个卷积层,以分别实现位置回归和分类。
后处理阶段,使用soft-NMS来过滤无用的包围框。
ASFF来自论文:《Learning Spatial Fusion for Single-Shot Object Detection》,也就是著名的yolov3-asff。
论文地址:
https://arxiv.org/pdf/1911.09516.pdf
代码地址:
https://github.com/ruinmessi/ASFF
金字塔特征表示法(FPN)是解决目标检测尺度变化挑战的常用方法。但是,对于基于FPN的单级检测器来说,不同特征尺度之间的不一致是其主要限制。因此这篇论文提出了一种新的数据驱动的金字塔特征融合方式,称之为自适应空间特征融合(ASFF)。它学习了在空间上过滤冲突信息以抑制梯度反传的时候不一致的方法,从而改善了特征的比例不变性,并且推理开销降低。借助ASFF策略和可靠的YOLOV3 BaseLine,在COCO数据集上实现了45FPS/42.4%AP以及29FPS/43.9%AP。
ASFF简要思想就是:原来的FPN add方式现在变成了add基础上多了一个可学习系数,该参数是自动学习的,可以实现自适应融合效果,类似于全连接参数。
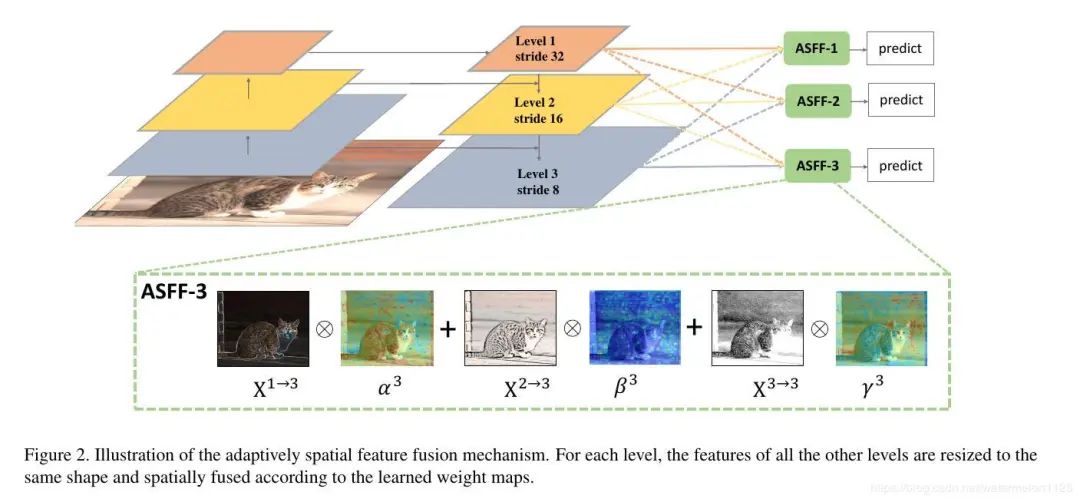
以ASFF-3为例,图中的绿色框描述了如何将特征进行融合,其中X1,X2,X3分别为来自level,level2,level3的特征,与为来自不同层的特征乘上权重参数α3,β3和γ3并相加,就能得到新的融合特征ASFF-3,如下面公式所示:
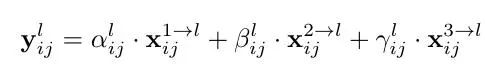
因为采用相加的方式,所以需要相加时的level1~3层输出的特征大小相同,且通道数也要相同,需要对不同层的feature做upsample或downsample并调整通道数。对于需要upsample的层,比如想得到ASFF3,需要将level1调整至和level3尺寸一致,采用的方式是先通过1×1卷积调整到与level3通道数一致,再用插值的方式resize到相同大小;而对于需要downsample的层,比如想得到ASFF1,此时对于level2到level1只需要用一个3×3,stride=2的卷积就可以了,如果是level3到level1则需要在3×3卷积的基础上再加一个stride=2的maxpooling,这样就能调整level3和level1尺寸一致。
对于权重参数α,β和γ,则是通过resize后的level1~level3的特征图经过1×1的卷积得到的。并且参数α,β和γ经过concat之后通过softmax使得他们的范围都在[0,1]内并且和为1:
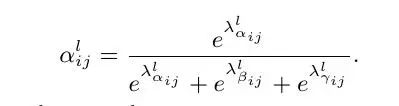
具体步骤可以概况为:
1、首先对于第l级特征图输出cxhxw,对其余特征图进行上下采样操作,得到同样大小和channel的特征图,方便后续融合
2、对处理后的3个层级特征图输出,输入到1x1xn的卷积中(n是预先设定的),得到3个空间权重向量,每个大小是nxhxw
3、然后通道方向拼接得到3nxhxw的权重融合图
4、为了得到通道为3的权重图,对上述特征图采用1x1x3的卷积,得到3xhxw的权重向量
5、在通道方向softmax操作,进行归一化,将3个向量乘加到3个特征图上面,得到融合后的cxhxw特征图
6、采用3x3卷积得到输出通道为256的预测输出层
为什么ASFF有效?
文章通过梯度和反向传播来解释为什么ASFF会有效。首先以最基本的YOLOv3为例,加入FPN后通过链式法则我们知道在backward的时候梯度是这样计算的:
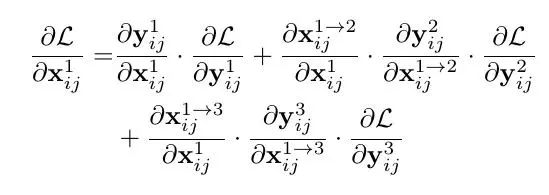
其中因为不同尺度的层之间的尺度变换无非就是up-sampling或者down-sampling,因此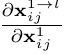 这一项通常为固定值,为了简化表达式我们可以设置为1,,则上面的式子变成了:
这一项通常为固定值,为了简化表达式我们可以设置为1,,则上面的式子变成了:
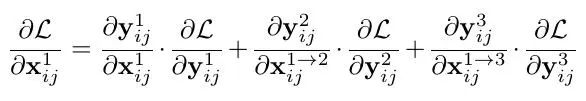
进一步的,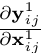 这一项相当于对输出特征的activation操作,其导数也将为固定值,同理,我们可以将他们的值简化为1,则表达式进一步简化成了:
这一项相当于对输出特征的activation操作,其导数也将为固定值,同理,我们可以将他们的值简化为1,则表达式进一步简化成了:
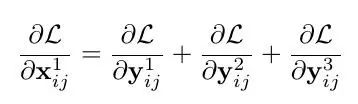
假设level1(i,j)对应位置feature map上刚好有物体并且为正样本,那其他level上对应(i,j)位置上可能刚好为负样本,这样反传过程中梯度既包含了正样本又包含了负样本,这种不连续性会对梯度结果造成干扰,并且降低训练的效率。而通过ASFF的方式,反传的梯度表达式就变成了:
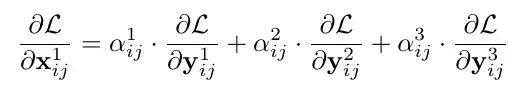
我们可以通过权重参数来控制,比如刚才那种情况,另α2和α3=0,则负样本的梯度不会结果造成干扰。另外这也解释了为什么特征融合的权重参数来源于输出特征+卷积,因为融合的权重参数和特征是息息相关的。
BiFPN来自论文:《EfficientDet: Scalable and efficient object detection 》。BiFPN思想和ASFF非常类似,也是可学习参数的自适应加权融合,但是比ASFF更加复杂。
论文地址:
https://arxiv.org/abs/1901.01892
代码地址:
https://github.com/google/automl/tree/master/efficientdet(Google官方)
https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch(高星PyTorch复现)
EfficientDet的方法论和创新性围绕两个关键挑战:
更好地融合多层特征。这个毋庸置疑,肯定是从 FPN 发展过来的,至于 Bi 就是双向,原始的FPN实现的自顶向下(top-down)融合,所谓的BiFPN就是两条路线既有top-down也有down-top。在融合过程中,之前的一些模型方法没有考虑到各级特征对融合后特征的g共享度问题,即之前模型认为各级特征的贡献度相同,而本文作者认为它们的分辨率不同,其对融合后特征的贡献度不同,因此在特征融合阶段引入了weight。
模型缩放。这个主要灵感来自于 EfficientNet,即在基线网络上同时对多个维度进行缩放(一般都是放大),这里的维度体现在主干网络、特征网络、以及分类/回归网络全流程的整体架构上整体网络由主干网络、特征网络以及分类/回归网络组成,可以缩放的维度比 EfficientNet 多得多,所以用网络搜索方式不合适了,作者提出一些启发式方法。
BiFPN
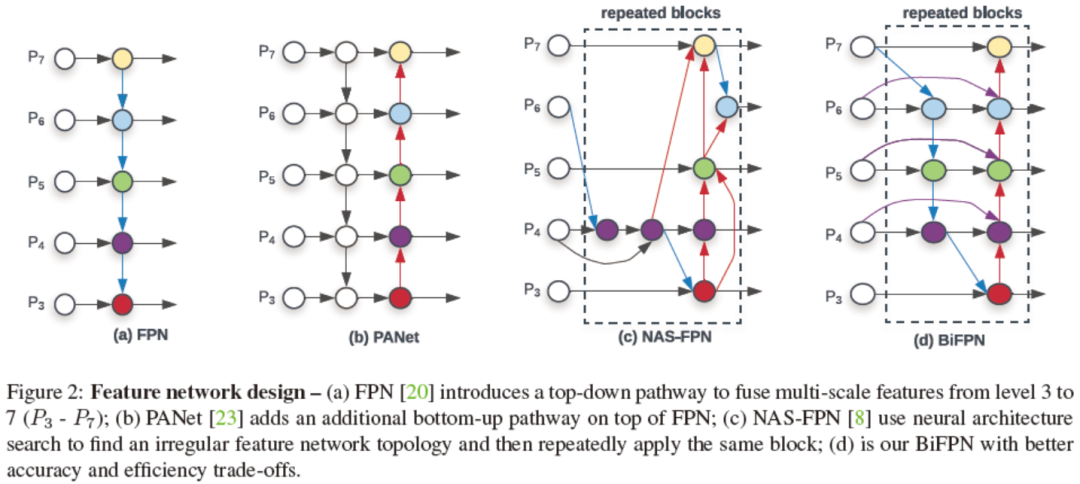
BiFPN的思想其实是基于路径增强FPN(PANet)的思想,在自顶向下特征融合之后紧接着自底向上再融合一遍。在图2中文章列举了三类FPN以及BiFPN。图2(a) 是传统FPN,图2(b)是PANet,图2(c)是利用网络自动搜索的方式生成的不规则特征融合模块,且这个模块可以重复叠加使用【即堆叠同样的模块,不停地使用相同的结构融合多层特征】。可以看到,PANet可以看做一个naïve的双向FPN。
BiFPN针对PANet的改进点主要有三个:
削减了一些边。BiFPN删除了只有一个入度的节点,因为这个节点和前一个节点的信息是相同的【因为没有别的新的信息传进来】,这样就祛除了一些冗余计算。
增加了一些边。BiFPN增加了一些跳跃连接【可以理解为residual连接,图2(d)中横向曲线3个连接】,这些连接由同一层的原始特征节点【即没有经历自顶向下融合的特征】连接到输出节点【参与自底向上特征融合】。
将自顶向下和自底向上融合构造为一个模块,使其可以重复堆叠,增强信息融合【有了一种递归神经网络的赶脚】。PANet只有一层自顶向下和一层自底向上。
而对于特征融合的计算,BiFPN也做了改进。传统融合计算一般就是把输入特征图resize到相同尺寸然后相加【或相乘,或拼接】。但是BiFPN考虑到不同特征的贡献可能不同,所以考虑对输入特征加权。文章中把作者们对如何加权的探索过程也列了出来。
首先尝试简单加权相加,对权值不做约束。这样得到的实验结果还可以,但是没有约束的权值会造成训练困难和崩溃。
然后为了归一化权值,作者尝试了用softmax操作把权值归一化到[0, 1]。虽然达到了归一化效果,但是softmax极大增加了GPU计算负担。
最后,回归本质,不整什么指数计算了。直接权值除以所有权值加和(分母加了一个极小量防止除0)来归一化【也就是计算权值在整个权值中的比例】,同样把权值归一化到[0,1],性能并没有下降,还增加了计算速度。
BiFPN介绍的最后,作者还提醒大家注意在特征融合模块里为了进一步提高计算效率,卷积使用的是逐深度卷积【就是每个通道自成一个分组】,并在每个卷积之后加了BN和激活函数。
EfficientDet
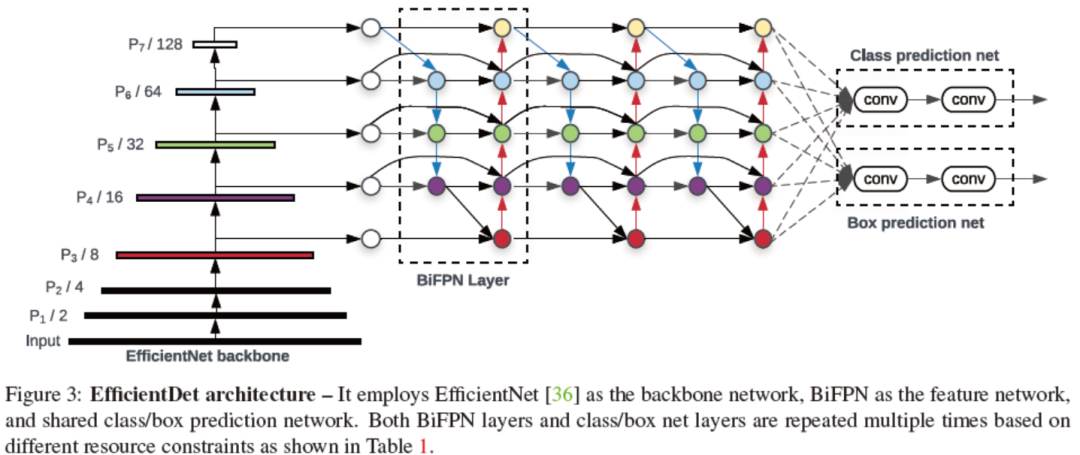
EfficientDet使用在imagenet上预训练的EfficientNet作为backbone模型,并对网络中第3到第7层特征进行了BiFPN特征融合,用来检测和分类。
EfficientDet同样对模型进行了缩放。与EfficientNet对传统提升模型尺度方法的态度一样,文章认为传统提升模型尺度指示简单地针对单一维度【深度,宽度或分辨率】进行增加,而EfficientNet提出的符合缩放才是真香。EfficientDet提出了自己的符合缩放,要联合对backbone,BiFPN,预测模块,和输入分辨率进行缩放。然而仅仅对EfficientNet本身缩放的参数进行网格搜索就已经很贵了,对所有网络的所有维度进行网格搜索显然也是不可承受之重。所以EfficientDet用了一个“启发式”方法【在我看来是对每个网络的每个维度自定了一些简单的规则而已】。
Backbone依然遵循EfficientNet。
BiFPN的深度随系数ϕ线性增长,宽度随ϕ指数增长。而对宽度指数的底做了一个网格搜索,确定底为1.35 。
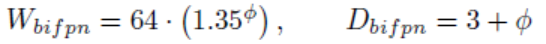
对预测模块,宽度与BiFPN一致。深度随ϕ线性增长。
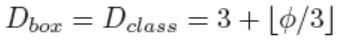
输入分辨率也是随ϕ线性增长。
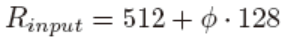
参考文章
https://zhuanlan.zhihu.com/p/93922612
https://blog.csdn.net/weixin_44936889/article/details/104269829
https://zhuanlan.zhihu.com/p/
https://blog.csdn.net/watermelon1123/article/details/103277773
涨分利器!攻克目标检测难点秘籍三,多尺度检测
https://zhuanlan.zhihu.com/p/141533907
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~