
2020年人工智能领域突破性工作
DETR
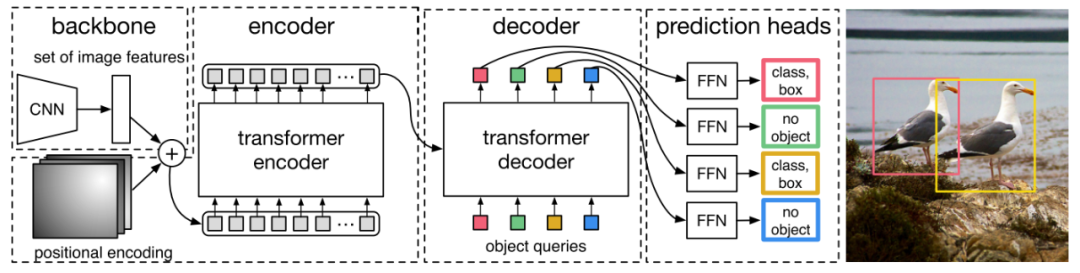
DETR是首个将完整的Transformer架构应用于计算机视觉领域的工作,开辟了计算机视觉大规模使用Transformer的新纪元。另外,DETR将目标检测问题当成集合预测问题,可以一次并行预测出所有目标框,引领了NMS-Free新方向。
ViT
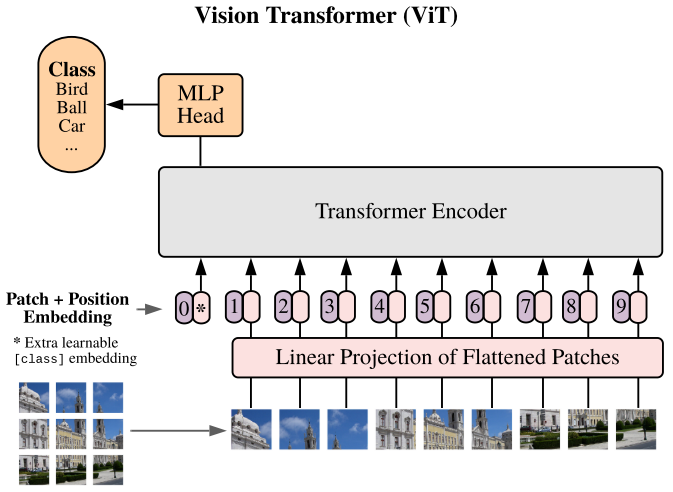
ViT更为巧妙的将输入图片看成是16x16的patches序列,直接使用Transformer Encoder来做patches序列的特征抽取,使得ViT可以作为一个标准的特征提取器,方便的应用于计算机视觉下游任务(最近基于ViT的魔改少说几百篇???)
BYOL
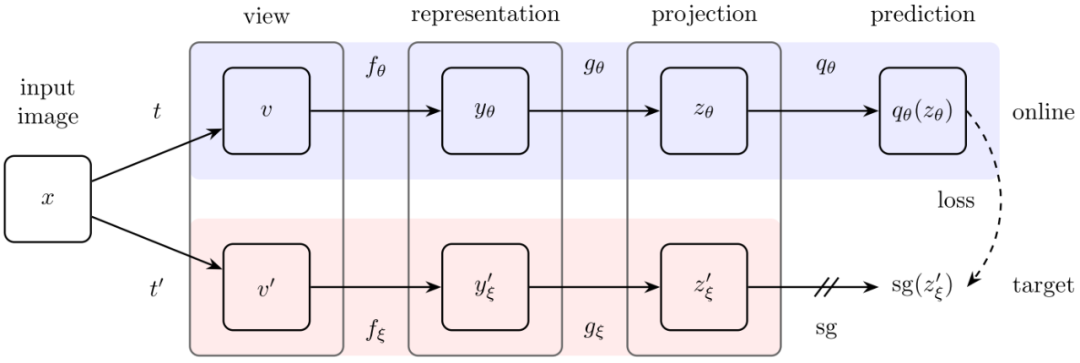
自从MoCo横空出世以来,Self-Supervised领域再度火热,但是BYOL之前的方法仍然遵循着正样本对拉近,负样本对排斥的原则。然而BYOL天马行空的将负样本排斥原则舍弃,只遵循正样本对拉近原则,并且取得了非常好的效果。这是什么概念,这就是Self-Supervised的周伯通啊,左手和右手互博,不需要和别人实战就能练成绝世神功。
NeRF
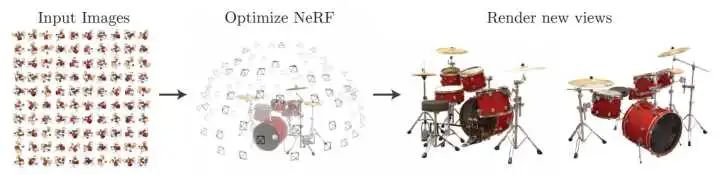
NeRF,只需要输入少量静态图片,就能做到多视角的逼真3D效果。
看一下demo效果!


GPT-3
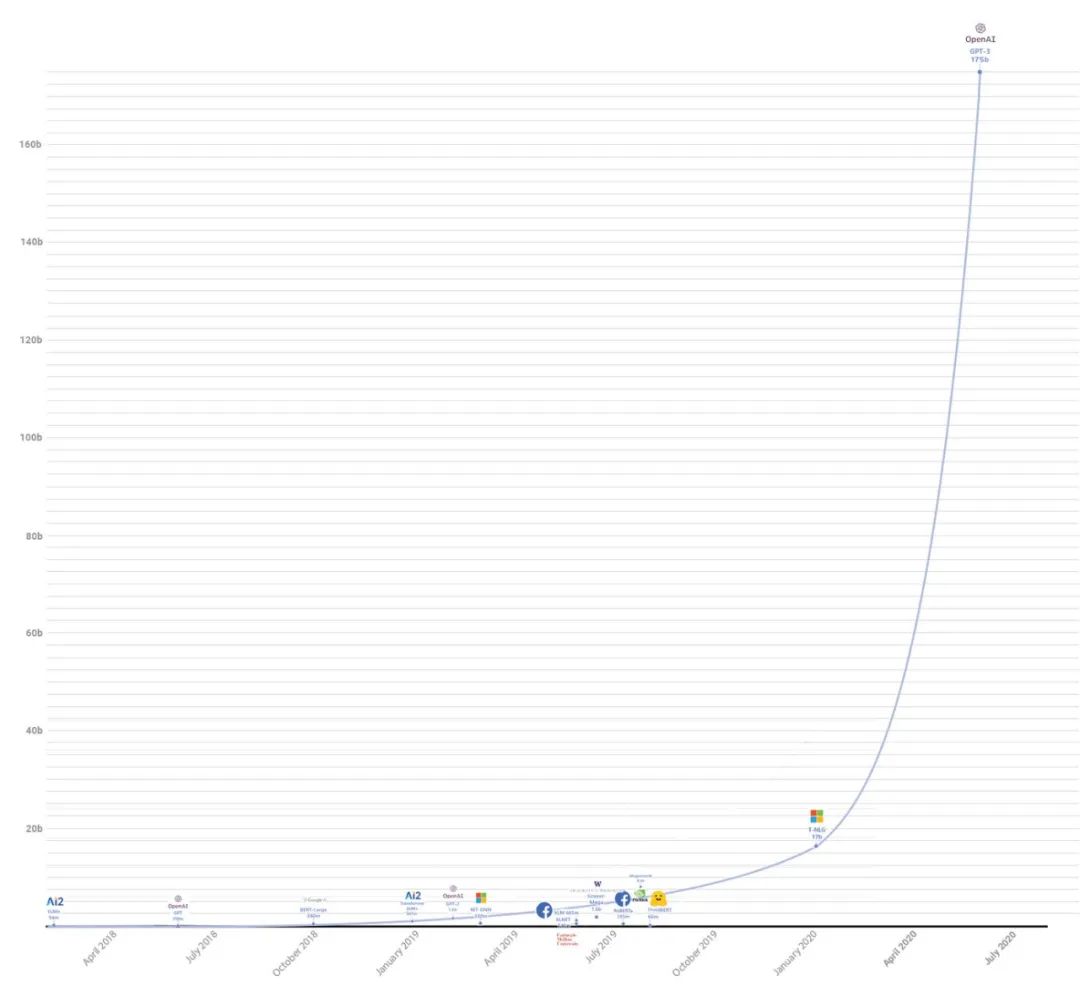
Money is all you need!OpenAI的GPT-3将训练的参数量堆到了1750亿,数据集总量是之前发布的GPT-2的116倍,是迄今为止最大的训练模型(2021年1月被Switch Transformer刷新)。
AlphaFold2
蛋白质结构预测问题是结构生物学一个里程碑式的问题,每两年,人类会组织一场蛋白质结构预测大赛。CASP14届Alphafold2血虐其他算法。
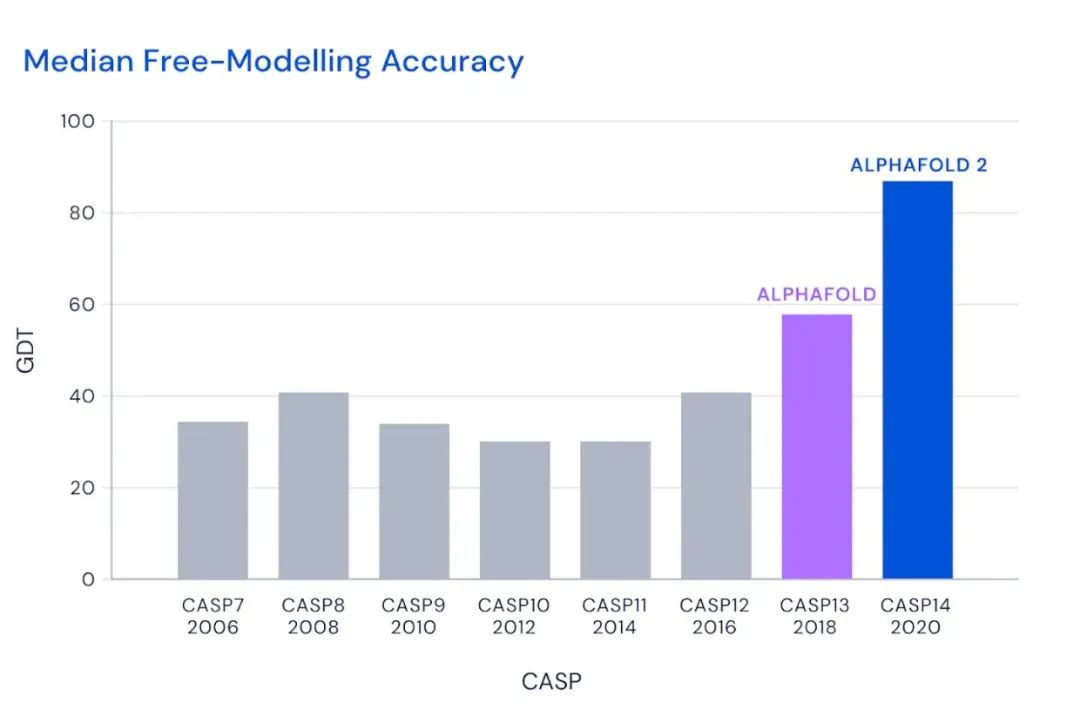
这个图什么概念?
CASP用来衡量预测准确性的主要指标是 GDT,范围为0-100。GDT可以近似地认为是和实验结构相比,成功预测在正确位置上的比例。70分就是达到了同源建模的精度,非正式的说,大约90 分可以和实验结果相竞争!
这次AlphaFold2直接把总分干到了92.4,和实验的误差在1.6,即使是在最难的没有同源模板的蛋白质上面,这个分数也达到了了恐怖的87.0 。
最后
前4个工作对于后面Transformer、Self-Supervised和3D视觉领域有着深远的影响,会一定程度上指引NLP和CV领域的发展。后两个工作可能属于行业颠覆型的工作,经久不衰。
Reference
[1] End-to-End Object Detection with Transformers
[2] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
[3] Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
[4] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
[5] Language Models are Few-Shot Learners
[6] AlphaFold: a solution to a 50-year-old grand challenge in biology | DeepMind
往期精彩回顾
本站qq群851320808,加入微信群请扫码: