
LeCun世界模型出场!Meta震撼发布首个「类人」模型,理解世界后补全半张图,自监督学习众望所归

新智元报道
新智元报道
【新智元导读】LeCun的世界模型终于来了,可谓是众望所归。既然大模型已经学会了理解世界、像人一样推理,是不是AGI也不远了?


LeCun的世界模型来了
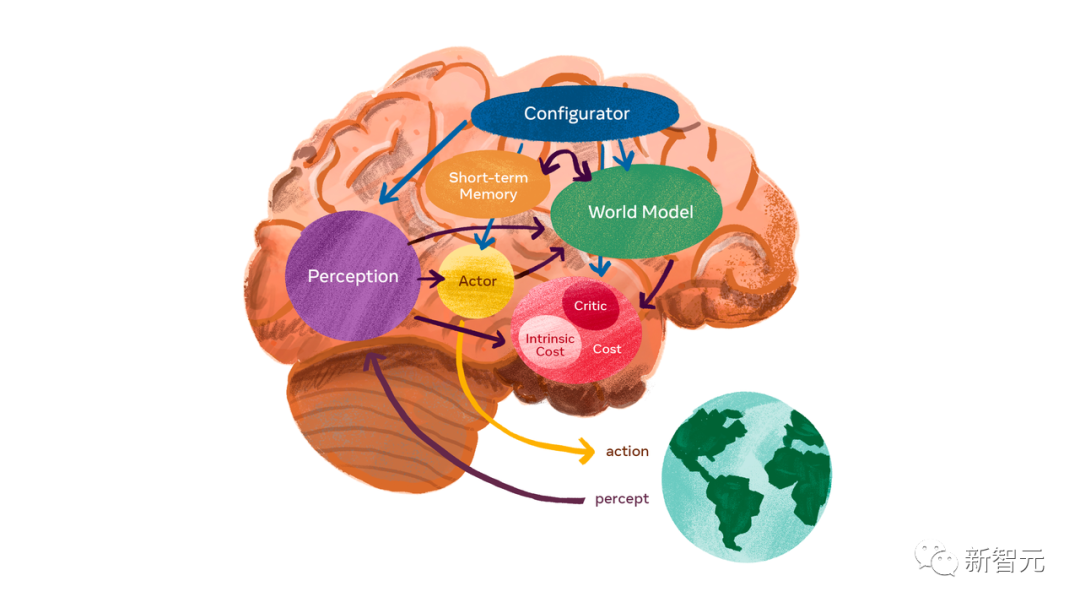
通过自监督学习获取常识
联合嵌入方法可以避免表征崩溃

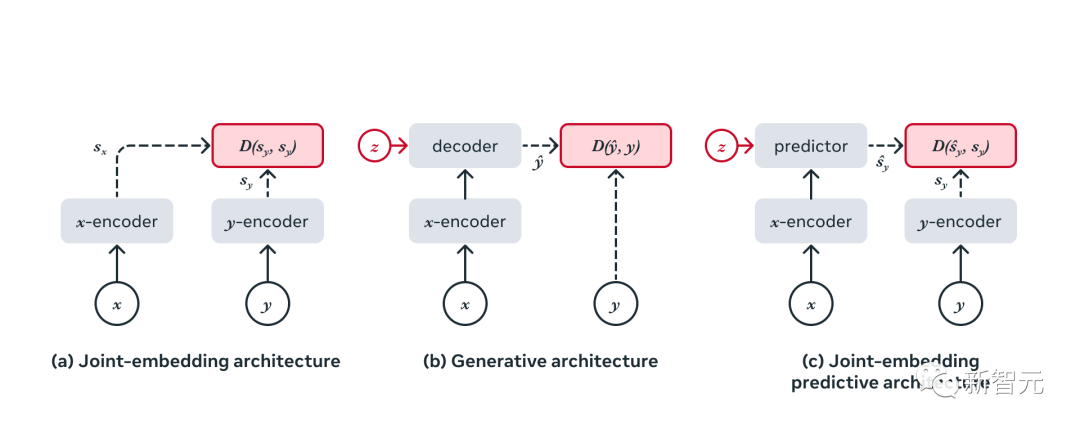 自监督学习的常见架构
自监督学习的常见架构联合嵌入预测架构
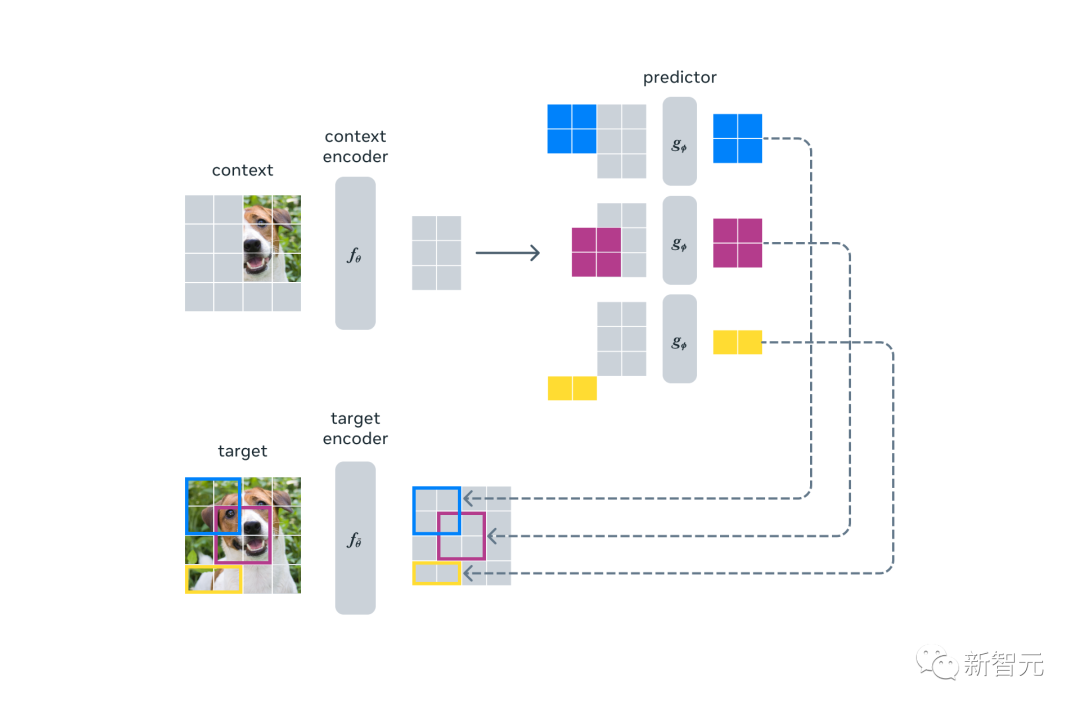
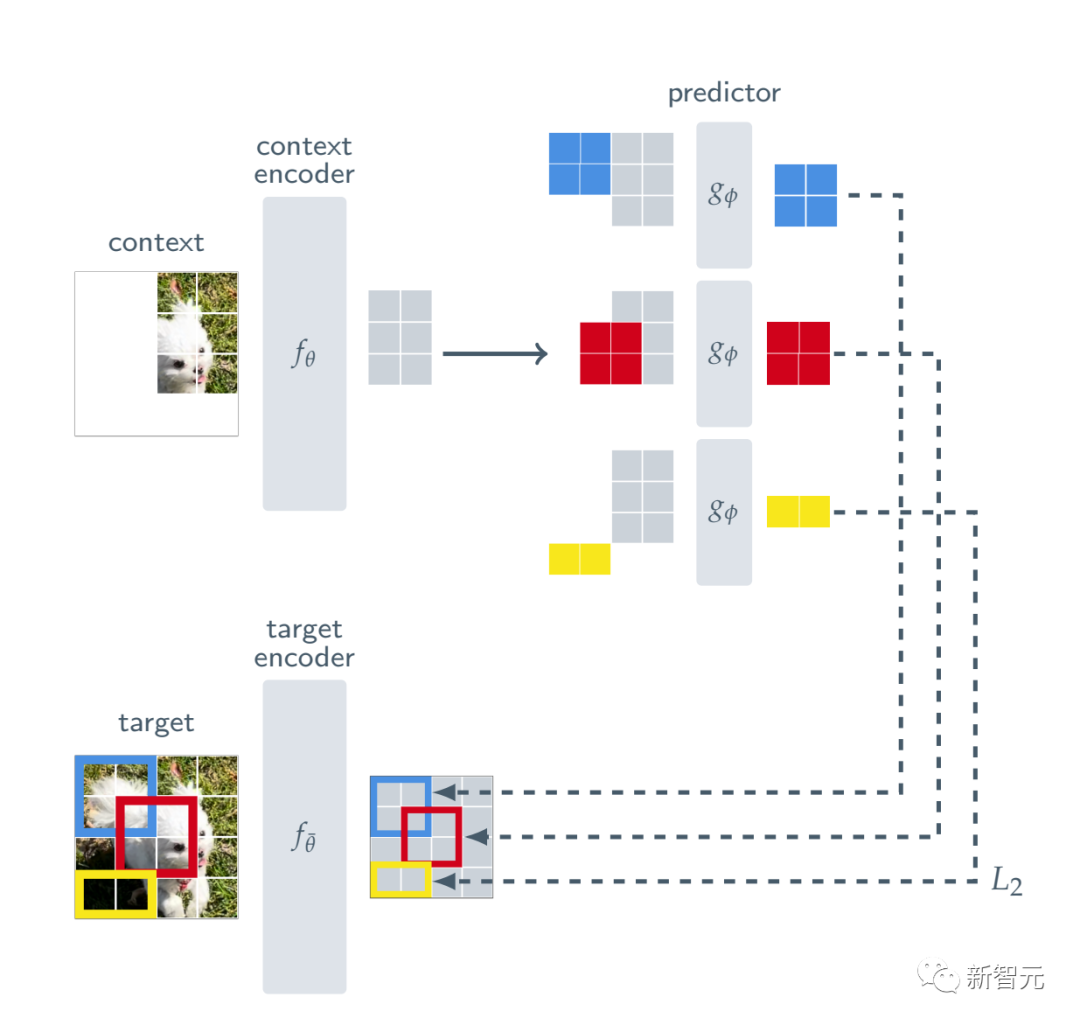


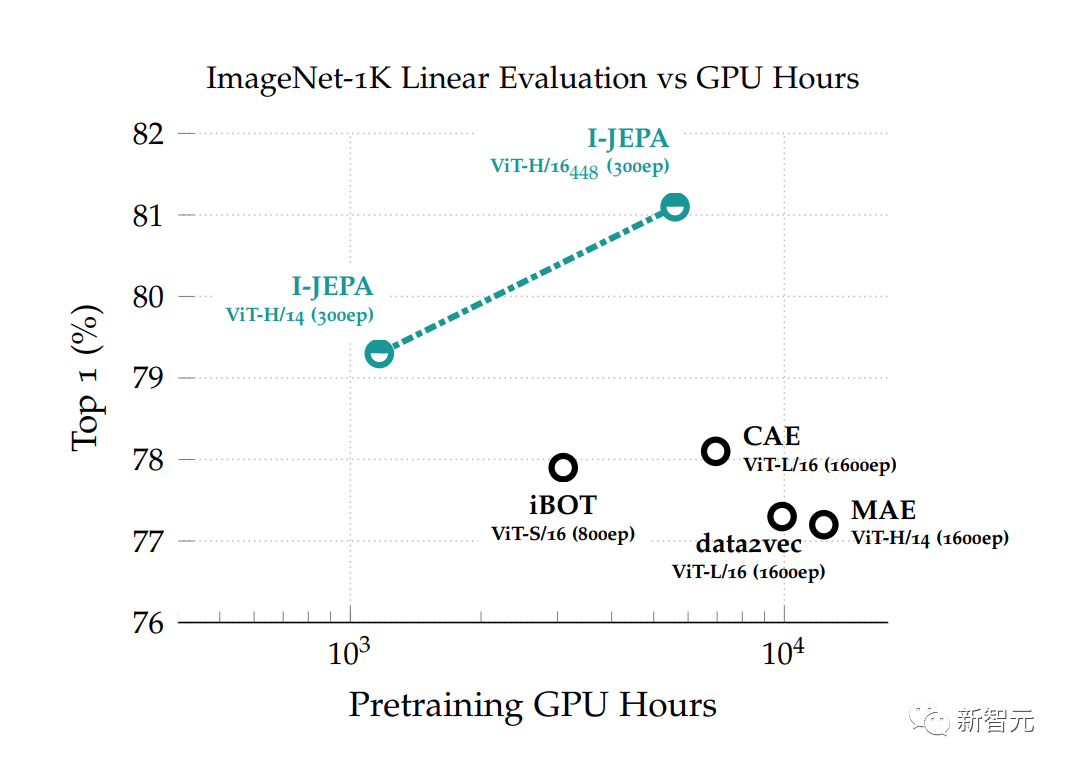
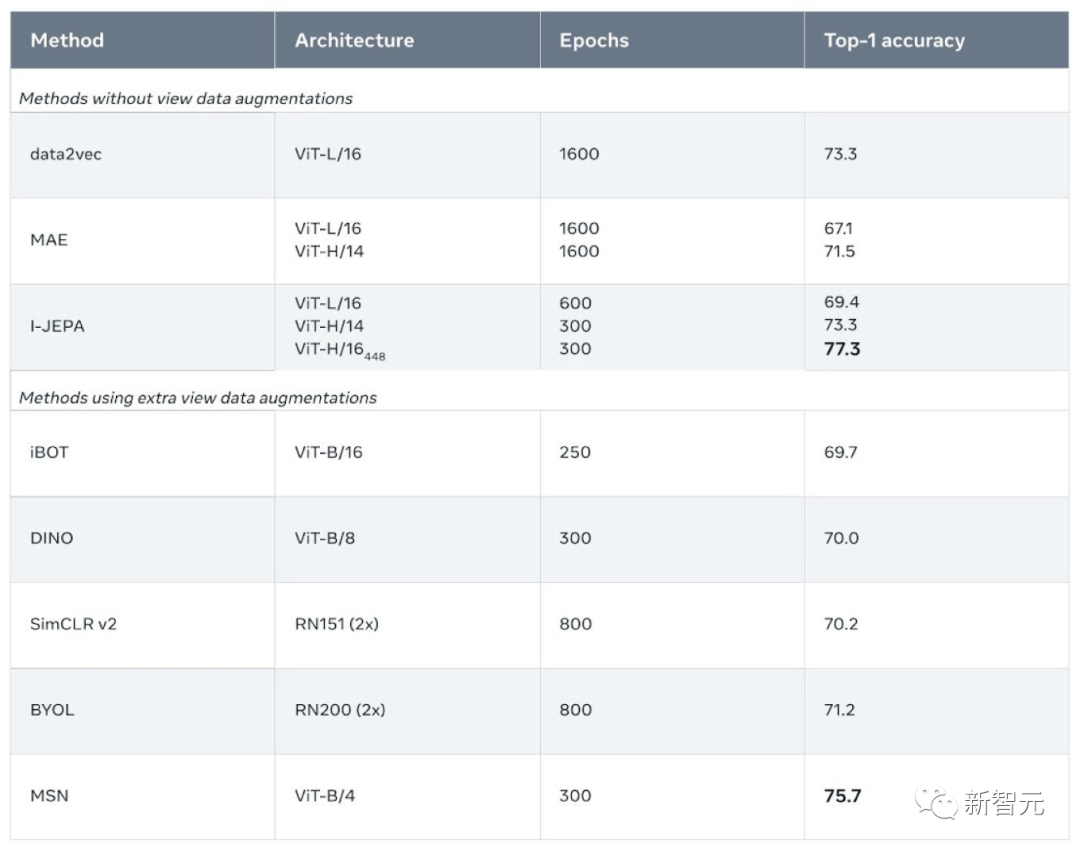
更高的效率,更强的性能
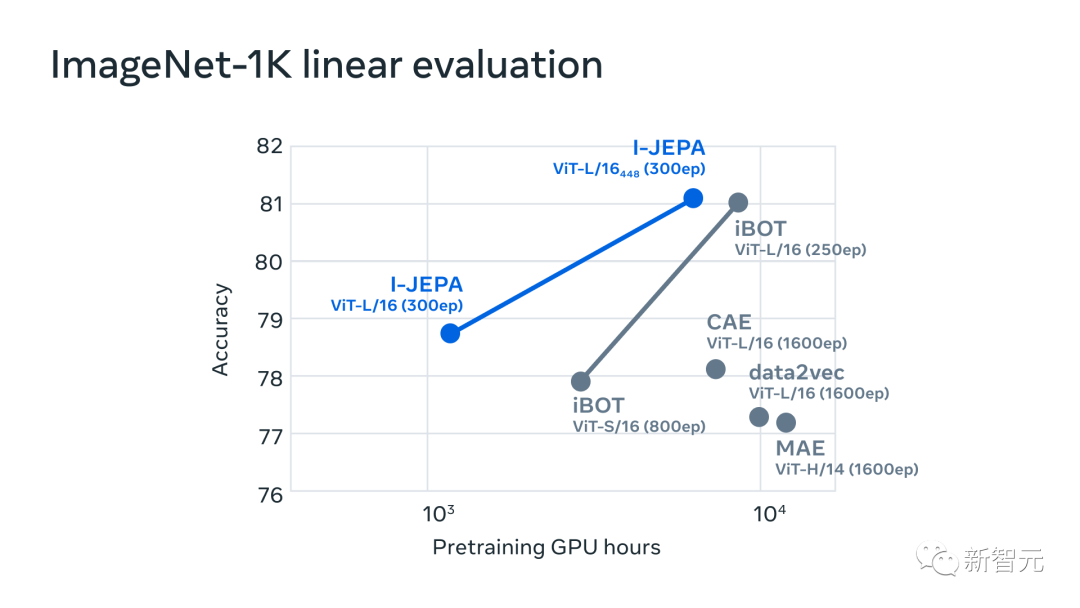
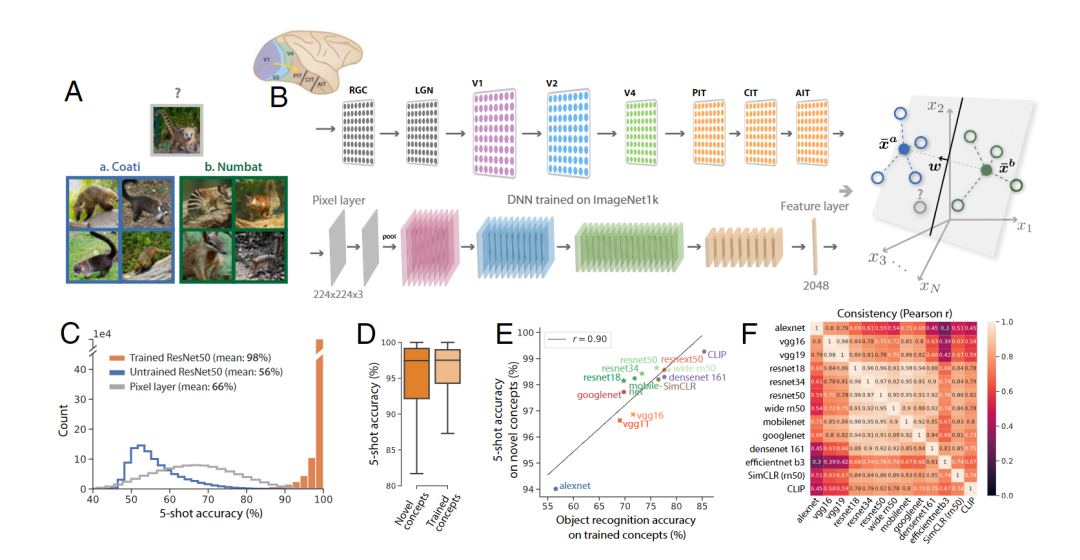
AI向人类智能更进了一步

预训练模型
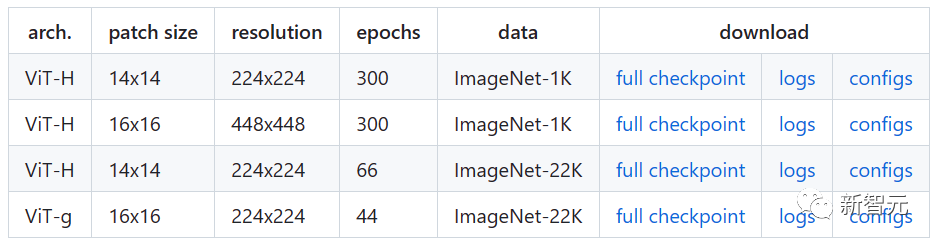
单GPU训练
python main.py \--fname configs/in1k_vith14_ep300.yaml \--devices cuda:0 cuda:1 cuda:2
多GPU训练
python main_distributed.py \--fname configs/in1k_vith14_ep300.yaml \--folder $path_to_save_submitit_logs \--partition $slurm_partition \--nodes 2 --tasks-per-node 8 \--time 1000
网友评论




评论